Clear Sky Science · en
A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation
Seeing Clearly in the Dark
Modern cars, street cameras, and security robots increasingly have to spot people and objects in rain, fog, and deep night. Visible-light cameras—much like our eyes—struggle when the scene is dark or full of glare, while infrared cameras can pick up heat but often miss detail. This paper presents a new way to combine, or “fuse,” visible and infrared images so that machines can detect pedestrians more reliably in difficult conditions, with fewer false alarms and missed targets.
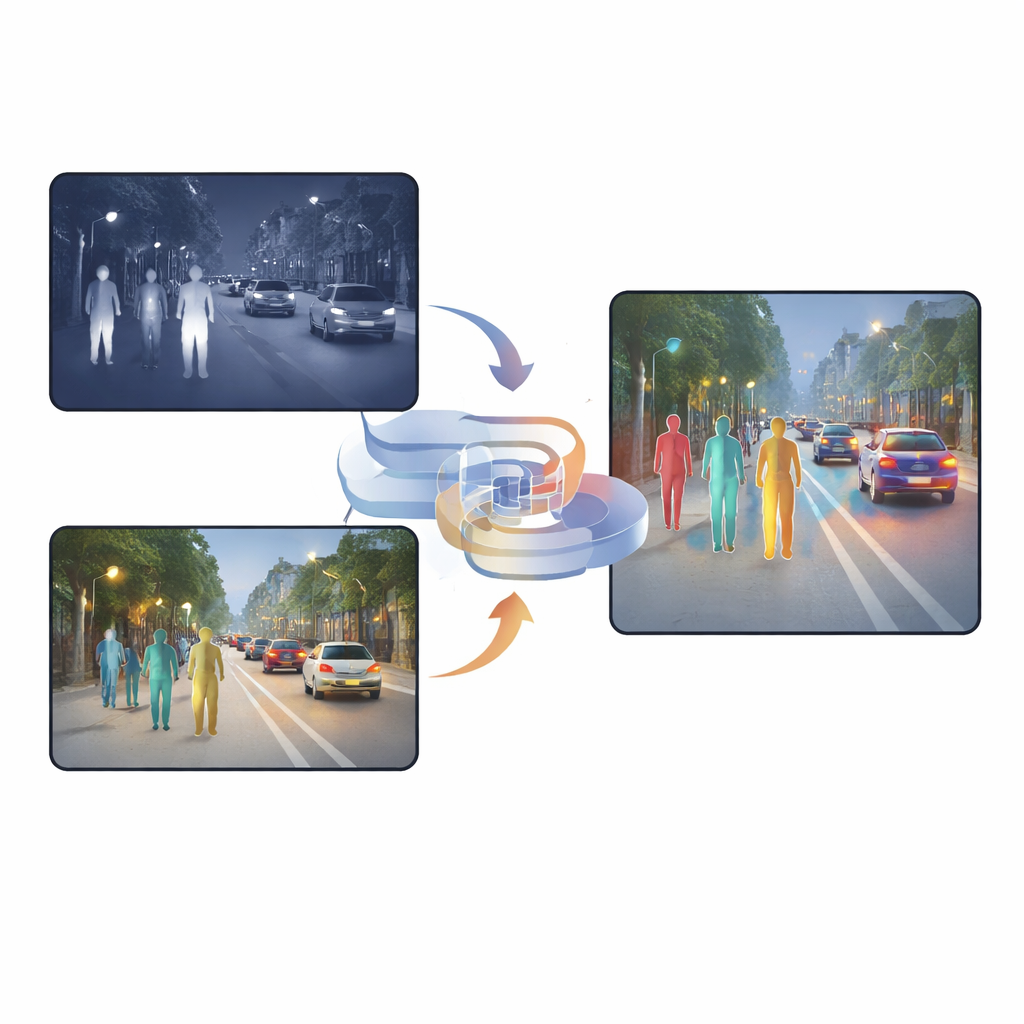
Why Two Kinds of Vision Are Better Than One
Visible cameras capture rich textures, colors, and fine details during the day, but their performance drops sharply at night or under harsh lighting. Infrared cameras, by contrast, see heat, so people stand out even in darkness, fog, or backlighting. However, infrared images are often blurry and lack sharp edges. Many existing systems simply stack these two types of images together or use attention mechanisms that decide, pixel by pixel, which camera to trust more. While these methods help, they still carry a lot of duplicated or conflicting information, and the fused result can be confusing for the detection network, especially when light changes suddenly or objects are partly hidden.
Filtering Out the Noise, Keeping the Essentials
The authors propose a new detection framework that focuses on what the two cameras have in common and throws away what is not needed. At its core is a Cross-modal Information Bottleneck, a module that deliberately squeezes the joint visible–infrared data through a narrow “channel” and then reconstructs what both views agree on. During this process, the network learns to keep only those patterns that truly help to recognize objects, while discarding camera-specific quirks and noise. It separately teases out what is unique to visible images and what is unique to infrared ones, then recombines them in a controlled way so that each camera’s strengths are preserved without overwhelming the shared view.
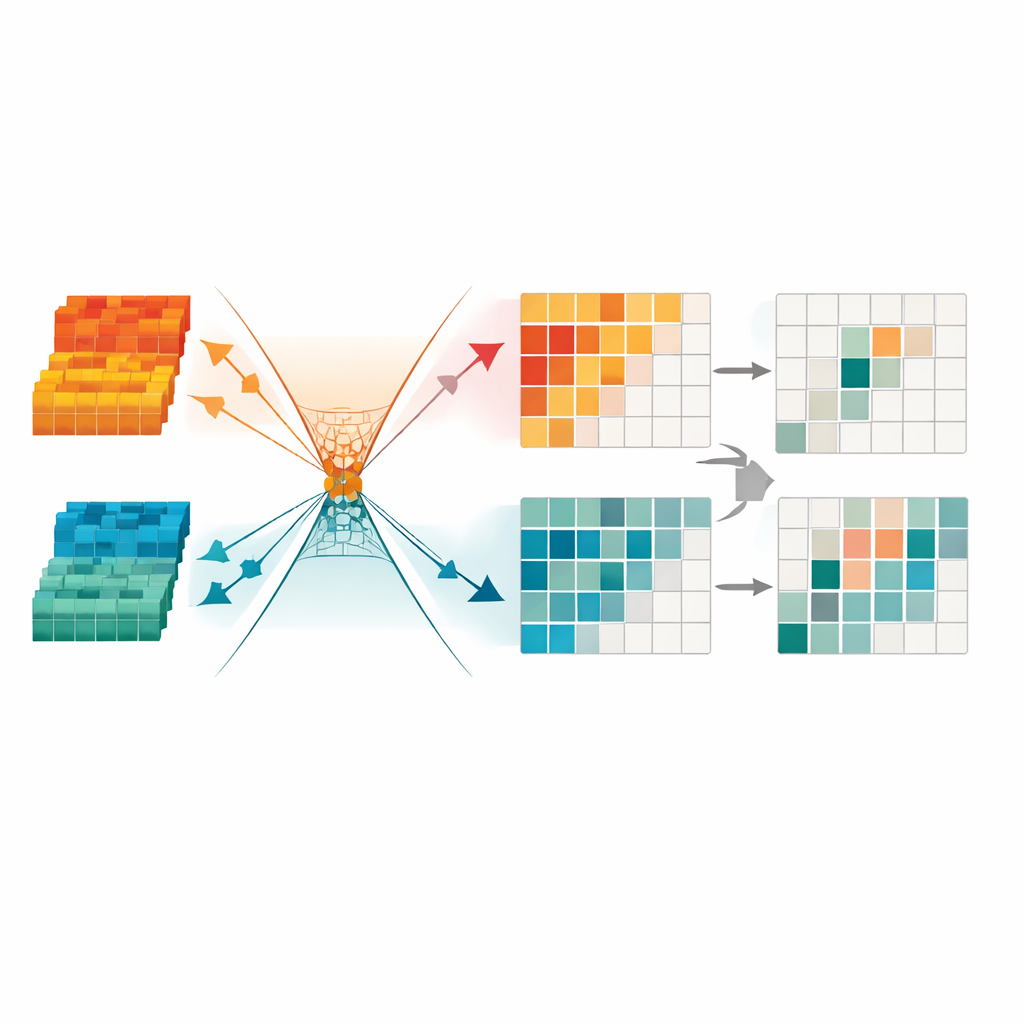
Trimming Redundant Signals for Sharper Focus
To further clean up the information, the framework introduces a Minimum Redundancy Transformation module. This component treats the fused data like a collection of channels and regions, and automatically masks those that appear unstable, low in detail, or dominated by lighting artifacts. It also uses mathematical constraints to force useful structure and leftover redundancy into different “directions” in its internal space, making it easier for the network to ignore patterns that do not help with detection. The end result is a compact, sparse representation that highlights clear object boundaries and consistent shapes, particularly important for spotting pedestrians at night or in cluttered urban scenes.
Putting the Method to the Test
The researchers evaluate their approach on two widely used datasets of paired visible and infrared images, KAIST and LLVIP, which include crowded streets under both normal and low-light conditions. Their method is built on a modern transformer-based detector and trained in two stages: first, each camera branch is stabilized separately; then, fusion is fine-tuned so the two work together smoothly. Across both datasets, the new framework outperforms leading visible-only, infrared-only, and fused methods, especially in strict localization measures that require very accurate bounding boxes. It also remains more reliable when images are artificially corrupted with noise, harsh brightness changes, or synthetic occlusions that block parts of pedestrians, showing that the model is robust to real-world disturbances.
What This Means for Safer Machines
In simple terms, this work teaches detection systems to listen to both cameras but not to let them talk over each other. By compressing and reorganizing the information from visible and infrared images, the proposed method keeps the shared, meaningful cues and cuts away much of the redundancy and noise. This leads to clearer recognition of people in difficult scenes, from dimly lit streets to heavily cluttered backgrounds. The authors suggest that the same principles could be extended to video, multi-object tracking, and even future systems that mix images with language, helping machines see—and understand—the world more reliably in all kinds of lighting.
Citation: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
Keywords: infrared-visible fusion, multimodal object detection, pedestrian detection, low-light imaging, sensor fusion robustness