Clear Sky Science · ru
Исследование алгоритма мультимодального обнаружения объектов на основе инфракрасно-видимой фузии с информационным узким местом между модальностями и трансформацией минимальной избыточности
Четче видеть в темноте
Современным автомобилям, уличным камерам и охранным роботам всё чаще приходится замечать людей и предметы в дождь, туман и глубокую ночь. Камеры видимого спектра — как и наши глаза — испытывают трудности при слабом освещении или сильных бликах, тогда как инфракрасные камеры фиксируют тепло, но часто теряют детали. В этой статье предложен новый способ объединения, или «слияния», видимых и инфракрасных изображений, чтобы машины могли надёжнее обнаруживать пешеходов в сложных условиях, с меньшим количеством ложных тревог и пропусков.
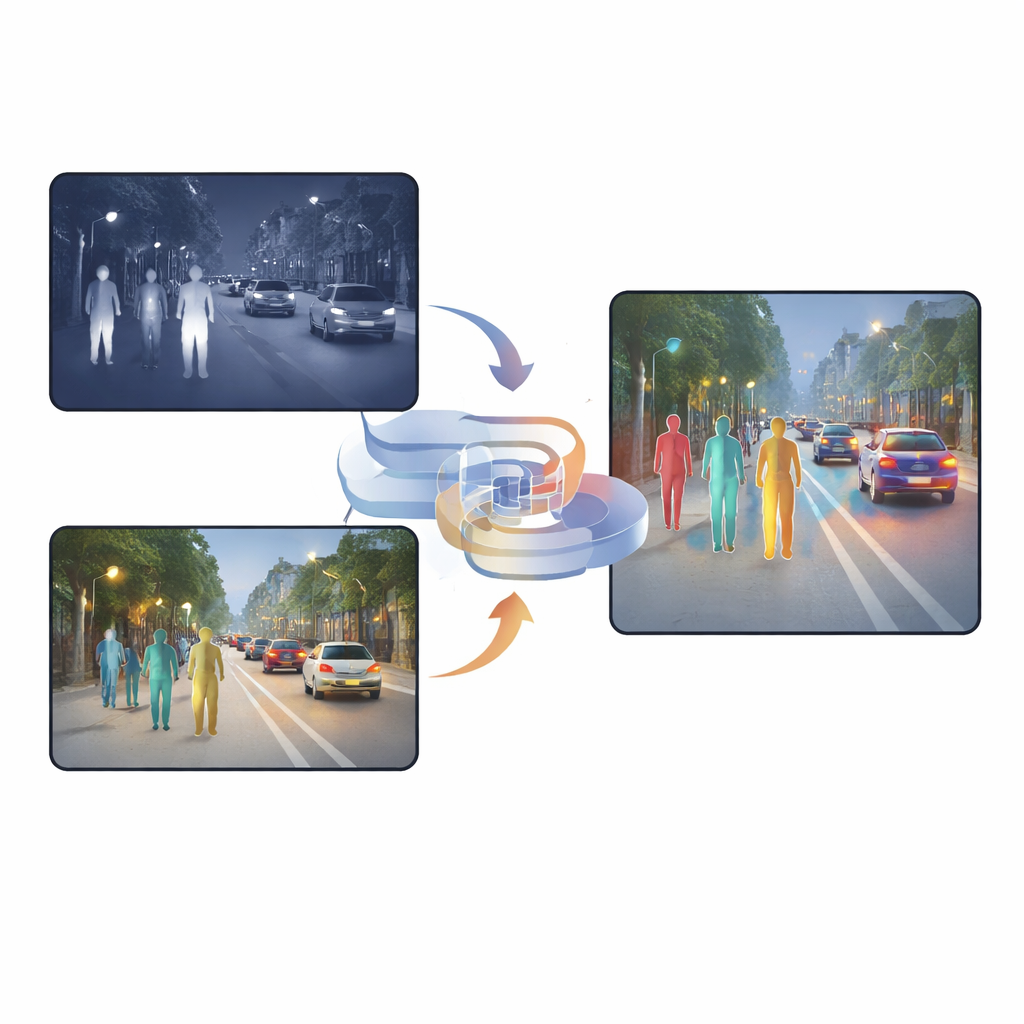
Почему два вида зрения лучше одного
Камеры видимого света захватывают богатые текстуры, цвета и мелкие детали в дневное время, но их эффективность резко падает ночью или при резком освещении. Инфракрасные камеры, напротив, видят тепло, поэтому люди выделяются даже в темноте, тумане или при встречной засветке. Однако инфракрасные изображения часто размыты и лишены чётких контуров. Многие существующие системы просто объединяют эти два типа изображений или используют механизмы внимания, которые решают, по пикселю, какому сенсору больше доверять. Такие подходы помогают, но по-прежнему содержат много дублирующейся или противоречивой информации, и результирующее слияние может сбивать детектор с толку, особенно при резких изменениях освещения или частичной сокрытости объектов.
Отсечение шума, сохранение сущности
Авторы предлагают новую схему обнаружения, которая фокусируется на том, что общо у двух камер, и отбрасывает лишнее. В её основе — кросс-модальное информационное узкое место, модуль, намеренно сжимающий совместные видимо-инфракрасные данные через узкий «канал», а затем восстанавливающий то, в чём соглашаются оба вида. В этом процессе сеть учится сохранять только те закономерности, которые действительно помогают распознавать объекты, одновременно отбрасывая характерные для конкретного сенсора артефакты и шум. Отдельно выделяется то, что уникально для видимых изображений, и то, что уникально для инфракрасных, затем эти компоненты контролируемо объединяются, чтобы сильные стороны каждой камеры сохранялись, не заглушая общее представление.
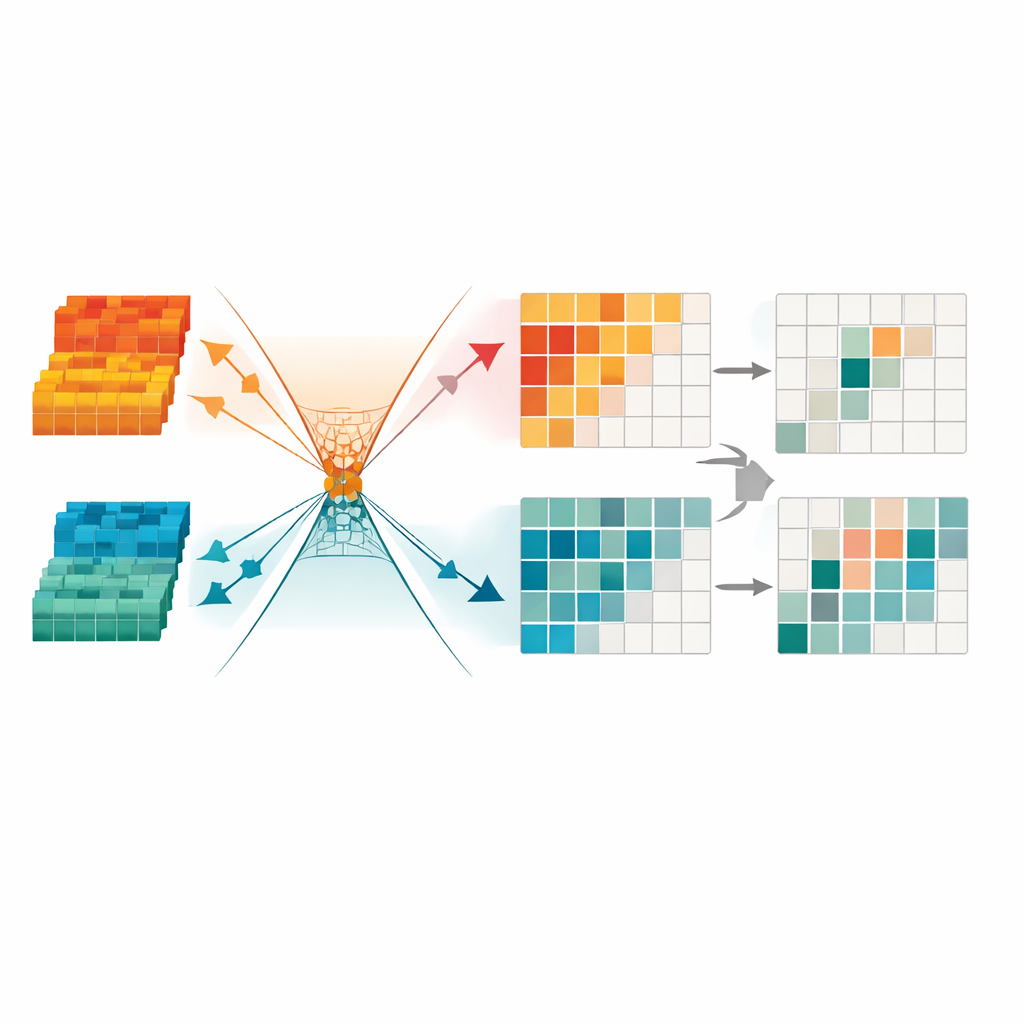
Сокращение избыточных сигналов для более чёткого фокуса
Чтобы ещё больше очистить информацию, в рамках предложенной схемы введён модуль трансформации минимальной избыточности. Этот компонент рассматривает слитые данные как набор каналов и областей и автоматически маскирует те, которые кажутся нестабильными, бедными деталями или доминируют за счёт артефактов освещения. Он также использует математические ограничения, чтобы вынудить полезную структуру и оставшуюся избыточность располагаться в разных «направлениях» внутреннего пространства, что облегчает сети игнорирование шаблонов, не помогающих в детекции. В результате получается компактное, разреженное представление, выделяющее чёткие границы объектов и согласованные формы — особенно важно для распознавания пешеходов ночью или в загруженной городской среде.
Проверка метода на практике
Исследователи оценивали свой подход на двух широко используемых наборах пар видимых и инфракрасных изображений, KAIST и LLVIP, которые включают многолюдные улицы в обычных и слабых условиях освещения. Их метод построен на современном детекторе на основе трансформера и обучается в два этапа: сначала стабилизируется каждая ветвь камеры отдельно; затем проводится донастройка слияния, чтобы обе ветви работали согласованно. На обоих наборах данных новая схема превосходит передовые методы, использующие только видимый спектр, только инфракрасный или их простое слияние, особенно по строгим метрикам локализации, требующим высокой точности ограничивающих рамок. Метод также остаётся более надёжным при искусственном искажении изображений шумом, резкими изменениями яркости или синтетическими окклюзиями, закрывающими части пешеходов, что свидетельствует о робастности модели к реальным помехам.
Что это значит для более безопасных машин
Проще говоря, эта работа учит системы обнаружения «слушать» обе камеры, но не позволять им заглушать друг друга. Сжимая и реорганизуя информацию из видимых и инфракрасных изображений, предложенный метод сохраняет общие, значимые подсказки и отсекает большую часть избыточности и шума. Это приводит к более чёткому распознаванию людей в сложных сценах — от слабо освещённых улиц до густонаселённых фонов. Авторы предполагают, что те же принципы можно распространить на видео, многообъектное отслеживание и даже будущие системы, объединяющие изображения и язык, помогая машинам видеть и понимать мир надёжнее при любом освещении.
Цитирование: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
Ключевые слова: инфракрасно-видимая фузия, мультимодальное обнаружение объектов, обнаружение пешеходов, съёмка при слабом освещении, устойчивость сенсорной фузии