Clear Sky Science · nl
Een studie over een multimodale objectdetectie-algoritme voor infrarood‑zichtbare fusie gebaseerd op cross‑modal information bottleneck en minimum redundancy transformation
Helder zien in het donker
Moderne auto’s, straatcamera’s en beveiligingsrobots moeten steeds vaker mensen en objecten herkennen in regen, mist en de diepste nacht. Zichtbare‑lichtcamera’s—net als onze ogen—hebben moeite wanneer de scène donker is of vol verblindingen, terwijl infraroodcamera’s warmte oppikken maar vaak detail missen. Dit artikel presenteert een nieuwe manier om zichtbare en infrarode beelden te combineren, of te “fuseren”, zodat systemen voetgangers betrouwbaarder kunnen detecteren onder moeilijke omstandigheden, met minder valse alarmen en gemiste doelen.
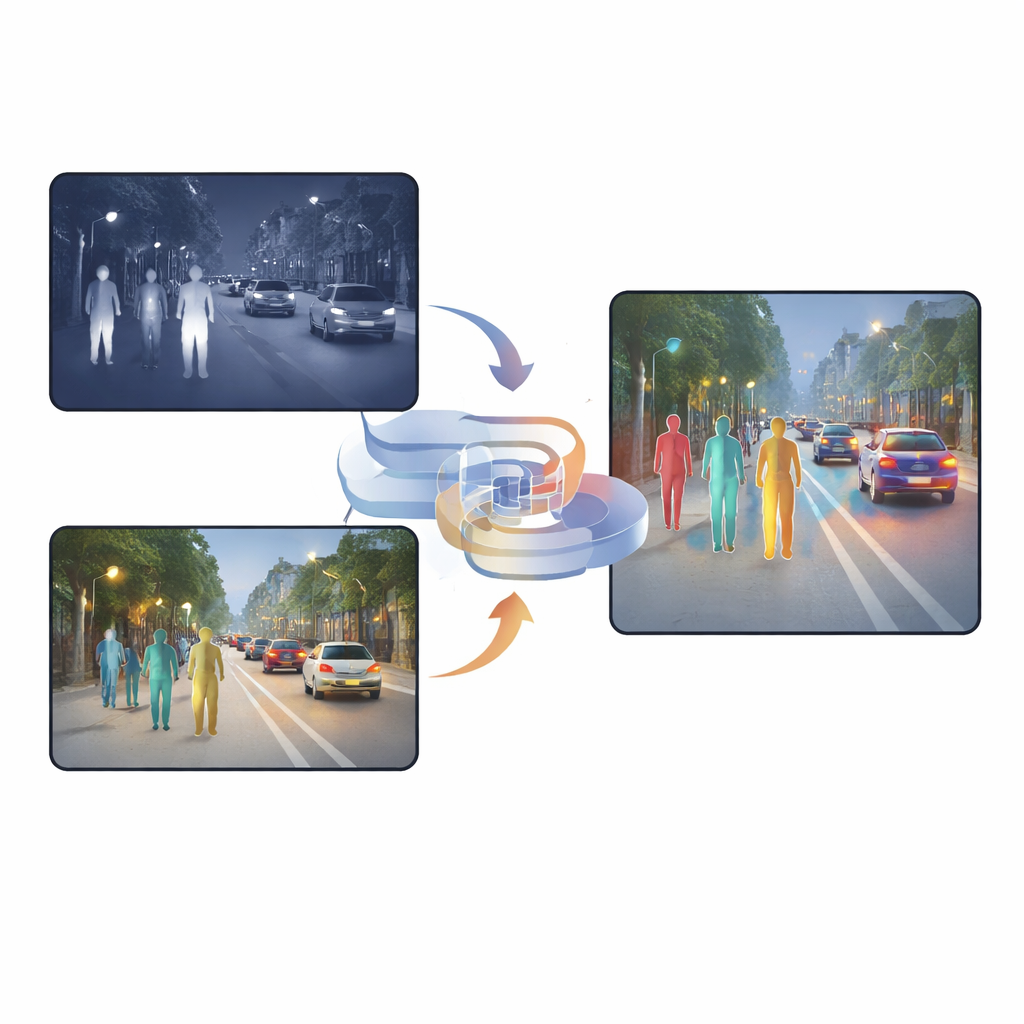
Waarom twee soorten zicht beter zijn dan één
Zichtbare camera’s leggen rijke texturen, kleuren en fijne details vast overdag, maar hun prestaties vallen sterk terug ’s nachts of bij hevig licht. Infraroodcamera’s daarentegen zien warmte, waardoor mensen opvallen zelfs in duisternis, mist of tegenlicht. Infra‑beelden zijn echter vaak onscherp en missen scherpe randen. Veel bestaande systemen stapelen deze twee beeldtypen simpelweg of gebruiken attentie‑mechanismen die per pixel beslissen welke camera meer vertrouwen verdient. Hoewel die methoden helpen, bevatten ze nog veel dubbele of tegenstrijdige informatie, en het gefuseerde resultaat kan verwarrend zijn voor het detectienetwerk, vooral bij plotselinge lichtveranderingen of gedeeltelijk verborgen objecten.
Het ruisfilter: behoud het essentiële
De auteurs stellen een nieuw detectiekader voor dat zich richt op wat de twee camera’s gemeen hebben en weggooit wat niet nodig is. Centraal staat een Cross‑modal Information Bottleneck, een module die de gezamenlijke zicht‑infraroodgegevens opzettelijk door een smalle “kanaal” perst en daarna reconstrueert waar beide gezichtspunten overeenkomen. Tijdens dit proces leert het netwerk alleen die patronen te behouden die echt helpen bij het herkennen van objecten, terwijl cameraspecifieke eigenaardigheden en ruis worden weggefilterd. Het haalt apart naar voren wat uniek is voor zichtbare beelden en wat uniek is voor infraroodbeelden, en combineert die vervolgens gecontroleerd zodat de sterke punten van elke camera behouden blijven zonder het gedeelde beeld te overspoelen.
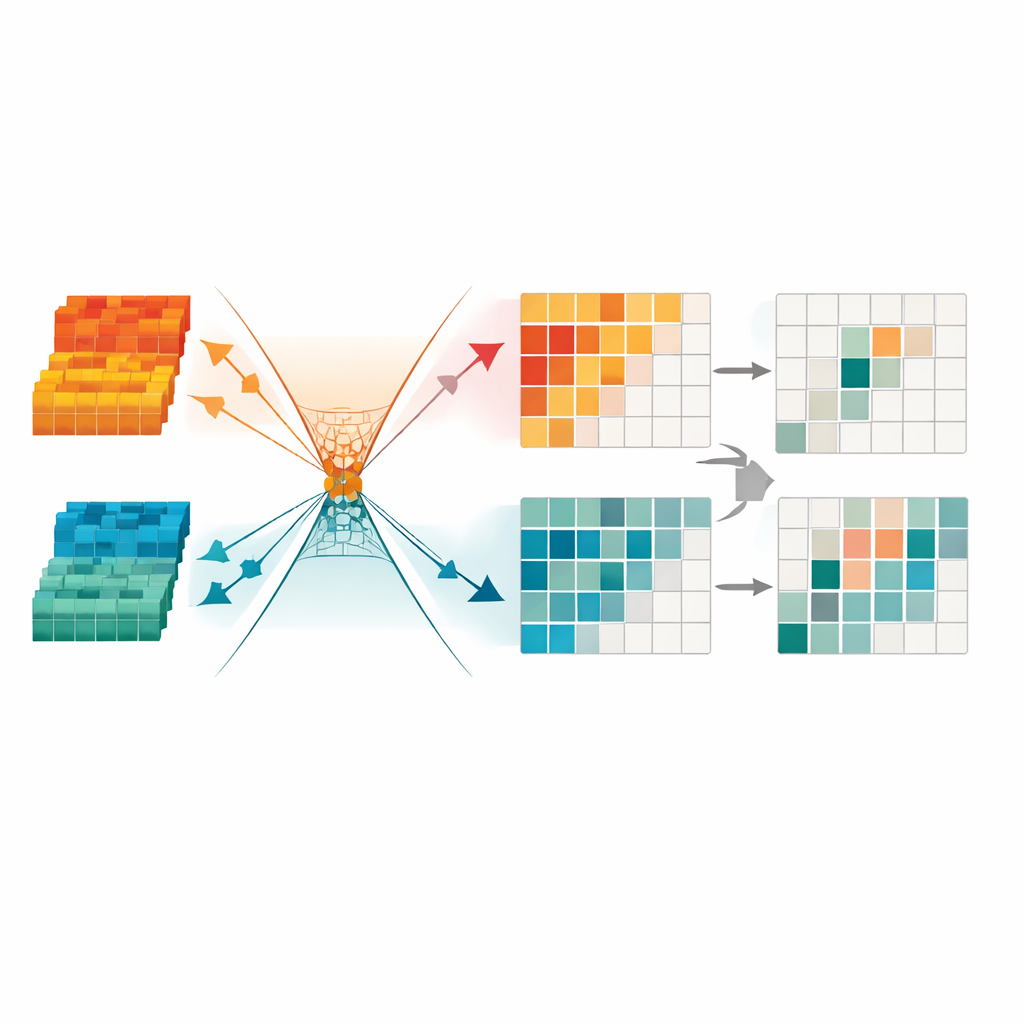
Redundante signalen wegknippen voor scherper inzicht
Om de informatie verder op te schonen, introduceert het kader een Minimum Redundancy Transformation‑module. Dit onderdeel behandelt de gefuseerde data als een verzameling kanalen en regio’s en maskeert automatisch die delen die onstabiel lijken, weinig detail bevatten of worden gedomineerd door lichtartefacten. Het gebruikt ook wiskundige beperkingen om nuttige structuur en resterende redundantie in verschillende “richtingen” van de interne representatie te dwingen, waardoor het voor het netwerk makkelijker wordt om patronen te negeren die niet bijdragen aan detectie. Het eindresultaat is een compacte, sparsere representatie die duidelijke objectranden en consistente vormen benadrukt — bijzonder belangrijk om voetgangers ’s nachts of in drukke stedelijke scènes te detecteren.
De methode op de proef gesteld
De onderzoekers evalueren hun aanpak op twee veelgebruikte datasets van gekoppelde zichtbare en infraroodbeelden, KAIST en LLVIP, die drukke straten onder zowel normale als weinig‑lichtcondities bevatten. Hun methode is gebouwd op een modern transformer‑gebaseerd detectiesysteem en wordt in twee fasen getraind: eerst wordt elke cameraketen afzonderlijk gestabiliseerd; daarna wordt de fusie fijngeslepen zodat beide soepel samenwerken. Over beide datasets presteert het nieuwe kader beter dan vooraanstaande alleen‑zichtbare, alleen‑infrarood en gefuseerde methoden, vooral bij strikte lokalisatiemaatstaven die zeer nauwkeurige begrenzingskaders vereisen. Het blijft ook betrouwbaarder wanneer beelden kunstmatig worden aangetast met ruis, sterke helderheidsveranderingen of synthetische occlusies die delen van voetgangers blokkeren, wat aantoont dat het model robuust is tegen reële storingen.
Wat dit betekent voor veiliger machines
In eenvoudige bewoordingen leert dit werk detectiesystemen naar beide camera’s te luisteren zonder ze elkaar te laten overheersen. Door de informatie uit zichtbare en infraroodbeelden te comprimeren en te herstructureren, behoudt de voorgestelde methode gedeelde, betekenisvolle signalen en snijdt veel van de redundantie en ruis weg. Dit leidt tot duidelijkere herkenning van mensen in moeilijke scènes, van schemerige straten tot sterk verstoorde achtergronden. De auteurs suggereren dat dezelfde principes kunnen worden uitgebreid naar video, multi‑object tracking en zelfs toekomstige systemen die beelden met taal combineren, zodat machines de wereld betrouwbaarder kunnen zien — en begrijpen — onder alle lichtomstandigheden.
Bronvermelding: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
Trefwoorden: infrarood‑zichtbare fusie, multimodale objectdetectie, voetgangersdetectie, weinig‑licht beeldvorming, robuustheid sensorfusie