Clear Sky Science · fr
Une étude sur un algorithme de détection d'objets multimodal par fusion infrarouge-visible basé sur le goulot d'information intermodal et la transformation de redondance minimale
Voir clairement dans l'obscurité
Les voitures modernes, les caméras de rue et les robots de sécurité doivent de plus en plus repérer des personnes et des objets sous la pluie, le brouillard ou en pleine nuit. Les caméras en lumière visible — comme nos yeux — peinent lorsque la scène est sombre ou pleine d'éblouissements, tandis que les caméras infrarouges détectent la chaleur mais manquent souvent de détails. Cet article présente une nouvelle méthode pour combiner, ou « fusionner », les images visibles et infrarouges afin que les machines puissent détecter les piétons de façon plus fiable dans des conditions difficiles, avec moins de fausses alertes et de cibles manquées.
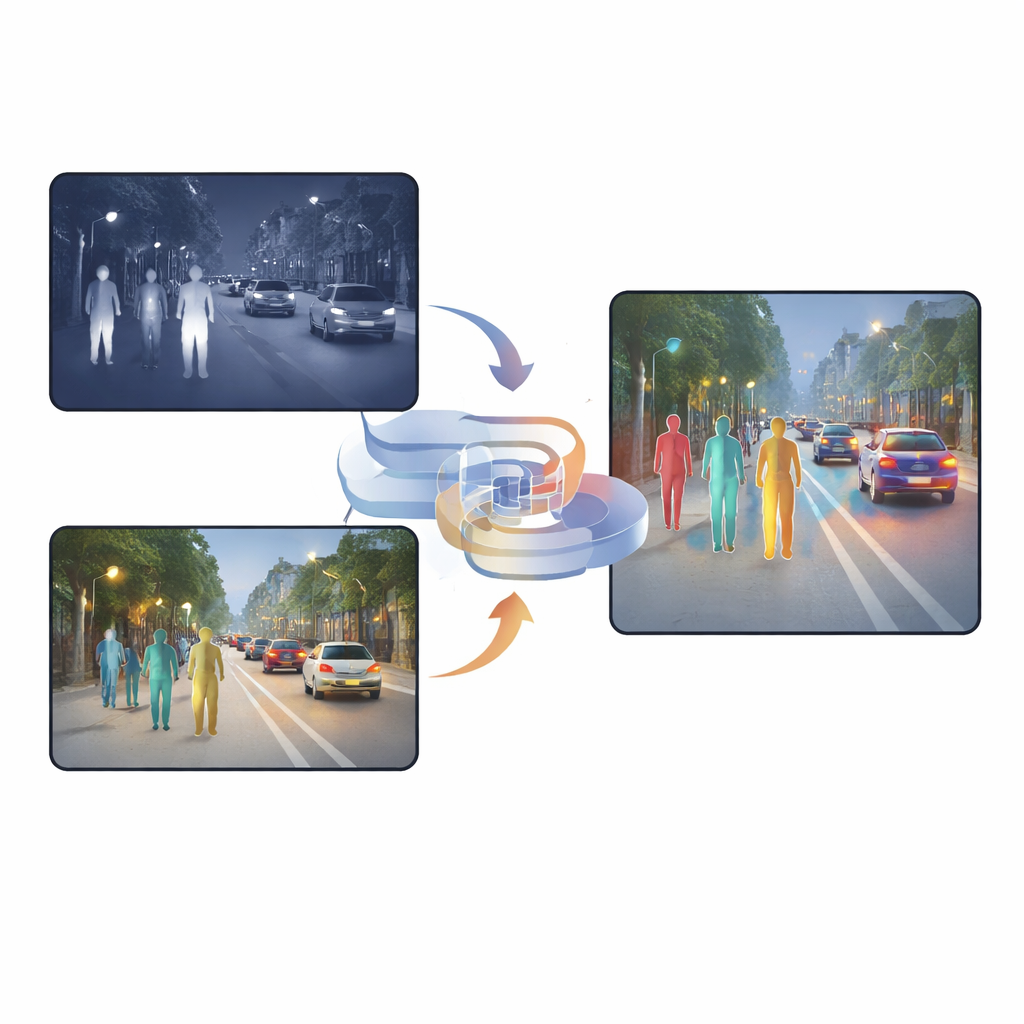
Pourquoi deux types de vision valent mieux qu’un
Les caméras visibles capturent des textures riches, des couleurs et de fins détails en journée, mais leurs performances chutent nettement la nuit ou sous un éclairage agressif. Les caméras infrarouges, en revanche, voient la chaleur : les personnes ressortent même dans l'obscurité, le brouillard ou en contre-jour. Cependant, les images infrarouges sont souvent floues et manquent de contours nets. De nombreux systèmes existants se contentent d'empiler ces deux types d'images ou d'utiliser des mécanismes d'attention qui décident pixel par pixel quelle caméra privilégier. Bien que ces méthodes soient utiles, elles conservent encore beaucoup d'informations dupliquées ou conflictuelles, et le résultat fusionné peut embrouiller le réseau de détection, surtout lorsque la lumière change brusquement ou que des objets sont partiellement masqués.
Éliminer le bruit, conserver l'essentiel
Les auteurs proposent un nouveau cadre de détection qui se concentre sur ce que les deux caméras ont en commun et élimine ce qui n'est pas nécessaire. Au cœur se trouve un Goulot d'Information Intermodal, un module qui comprime délibérément les données conjointes visible–infrarouge à travers un « canal » étroit puis reconstruit ce sur quoi les deux vues sont d'accord. Pendant ce processus, le réseau apprend à ne garder que les motifs qui aident réellement à reconnaître les objets, tout en écartant les particularités et le bruit propres à chaque caméra. Il extrait séparément ce qui est unique aux images visibles et ce qui est propre aux infrarouges, puis les recombine de manière contrôlée afin que les forces de chaque caméra soient préservées sans submerger la vue partagée.
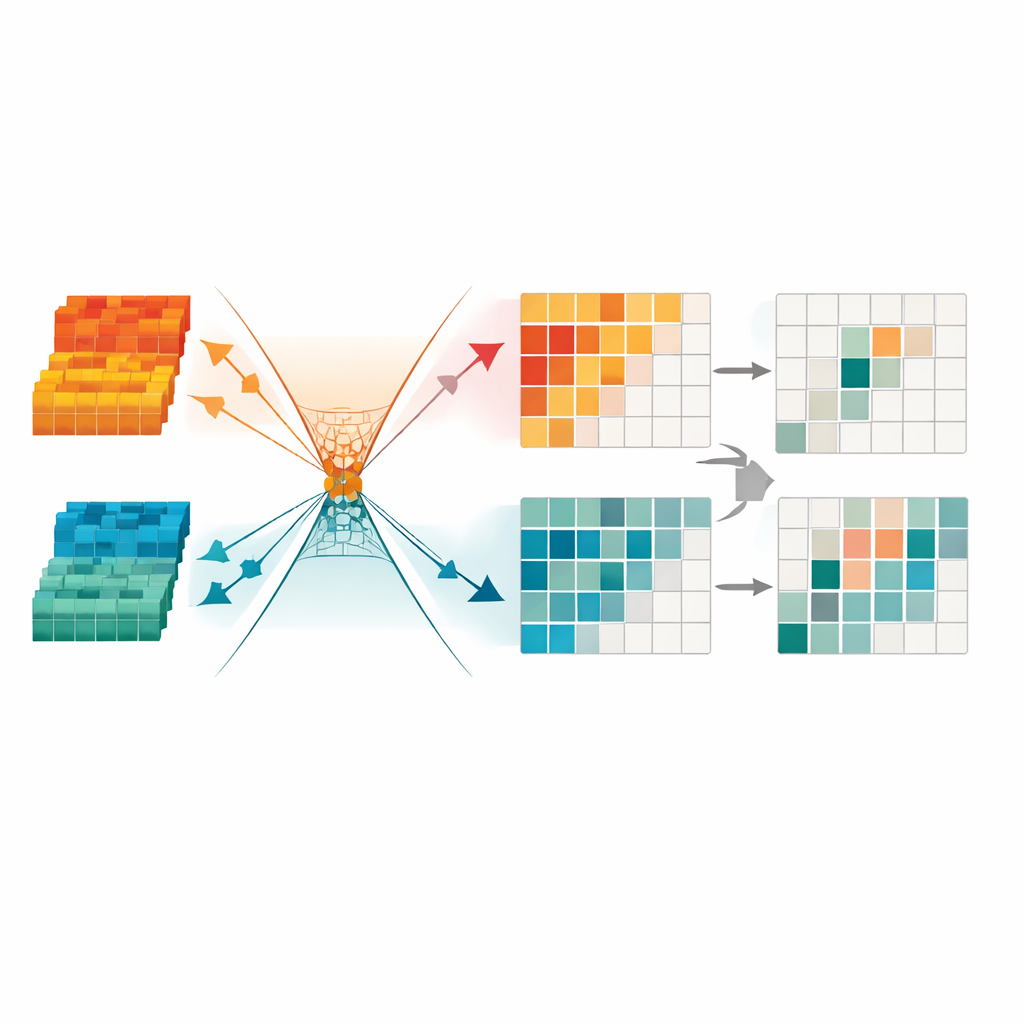
Élaguer les signaux redondants pour une focalisation plus nette
Pour épurer davantage l'information, le cadre introduit un module de Transformation de Redondance Minimale. Ce composant traite les données fusionnées comme un ensemble de canaux et de régions, et masque automatiquement celles qui paraissent instables, pauvres en détails ou dominées par des artefacts d'éclairage. Il utilise aussi des contraintes mathématiques pour forcer la structure utile et la redondance résiduelle à occuper des « directions » différentes dans son espace interne, ce qui facilite pour le réseau l'ignorance des motifs non pertinents pour la détection. Le résultat final est une représentation compacte et parcimonieuse qui met en évidence des contours d'objets nets et des formes cohérentes, particulièrement importante pour repérer des piétons la nuit ou dans des scènes urbaines encombrées.
Mettre la méthode à l'épreuve
Les chercheurs évaluent leur approche sur deux jeux de données largement utilisés d'images visibles et infrarouges appariées, KAIST et LLVIP, qui couvrent des rues encombrées en conditions normales et en faible luminosité. Leur méthode s'appuie sur un détecteur moderne basé sur des transformers et s'entraîne en deux étapes : d'abord, chaque branche caméra est stabilisée séparément ; ensuite, la fusion est affinée pour que les deux fonctionnent ensemble harmonieusement. Sur les deux jeux de données, le nouveau cadre dépasse les méthodes de pointe basées uniquement sur le visible, uniquement sur l'infrarouge et les méthodes fusionnées, en particulier sur les mesures de localisation strictes qui exigent des boîtes englobantes très précises. Il reste également plus fiable lorsque les images sont corrompues artificiellement par du bruit, des variations d'éclairement sévères ou des occultations synthétiques qui masquent des parties des piétons, montrant que le modèle est robuste aux perturbations du monde réel.
Ce que cela signifie pour des machines plus sûres
En termes simples, ce travail apprend aux systèmes de détection à écouter les deux caméras sans les laisser se couvrir mutuellement. En compressant et en réorganisant l'information issue des images visibles et infrarouges, la méthode proposée conserve les indices partagés et significatifs et élimine une grande partie de la redondance et du bruit. Cela conduit à une reconnaissance plus nette des personnes dans des scènes difficiles, des rues faiblement éclairées aux arrière-plans fortement encombrés. Les auteurs suggèrent que les mêmes principes pourraient être étendus à la vidéo, au suivi de multiples objets et même à de futurs systèmes qui combinent images et langage, aidant les machines à voir — et comprendre — le monde de manière plus fiable quelles que soient les conditions d'éclairage.
Citation: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
Mots-clés: fusion infrarouge-visible, détection d'objets multimodale, détection de piétons, imagerie en faible éclairage, robustesse de la fusion de capteurs