Clear Sky Science · zh
在最少上下文下评估大型语言模型的发散性思维能力以生成科学创意
这对普通科学爱好者为何重要
当代人工智能引起广泛关注,很大程度上来自于其在考试和测验中的出色表现。但科学突破很少源自答对测验题;它们常常始于由一个词或一个直觉触发的奇怪、半成形的想法。本文提出了一个务实但影响深远的问题:当你只给当今的大型语言模型一个微小提示——一个孤立的科学关键词——它们能否真正头脑风暴出新颖且可信的研究点子,这种“创造火花”与常规的人工智能智力衡量指标有何关联?
从解题机器到创意伙伴
目前大多数基准测试将人工智能视为超级学生:模型被提供丰富的上下文——比如完整的摘要或问题描述——然后按能否找到正确答案来评分。这种设置主要衡量收敛性思维:把选项缩小到单一解答。作者认为科学的早期阶段截然不同。科学家往往几乎从无开始,只有一个主题词,然后自由联想出数十个可能的问题和方向。为在机器中捕捉这种发散性思维,他们推出了LiveIdeaBench——一个刻意将上下文简化为仅有一个科学关键词(例如“显微镜学”或“天气预报”)并要求模型提出简短、具体研究点子的全新基准。
新基准如何运作
LiveIdeaBench覆盖22个领域中1180个热门科学关键词,横跨物理学、医学到社会科学等。对于每个关键词,超过40种领先的语言模型会被提示生成精炼的科学点子。一组表现优异的模型动态组成“裁判”小组,对每个点子沿五个受创造力启发的维度评分:原创性、可行性、表达清晰度、模型能从同一提示生成多少不同点子(流利性),以及在非常不同主题间表现稳定的能力(灵活性)。每个点子由多名裁判评分,取平均以降低单一模型偏差。该基准定期更新,无论是所用关键词还是被评估的模型,因此能够跟踪当前科学与人工智能能力的前沿。 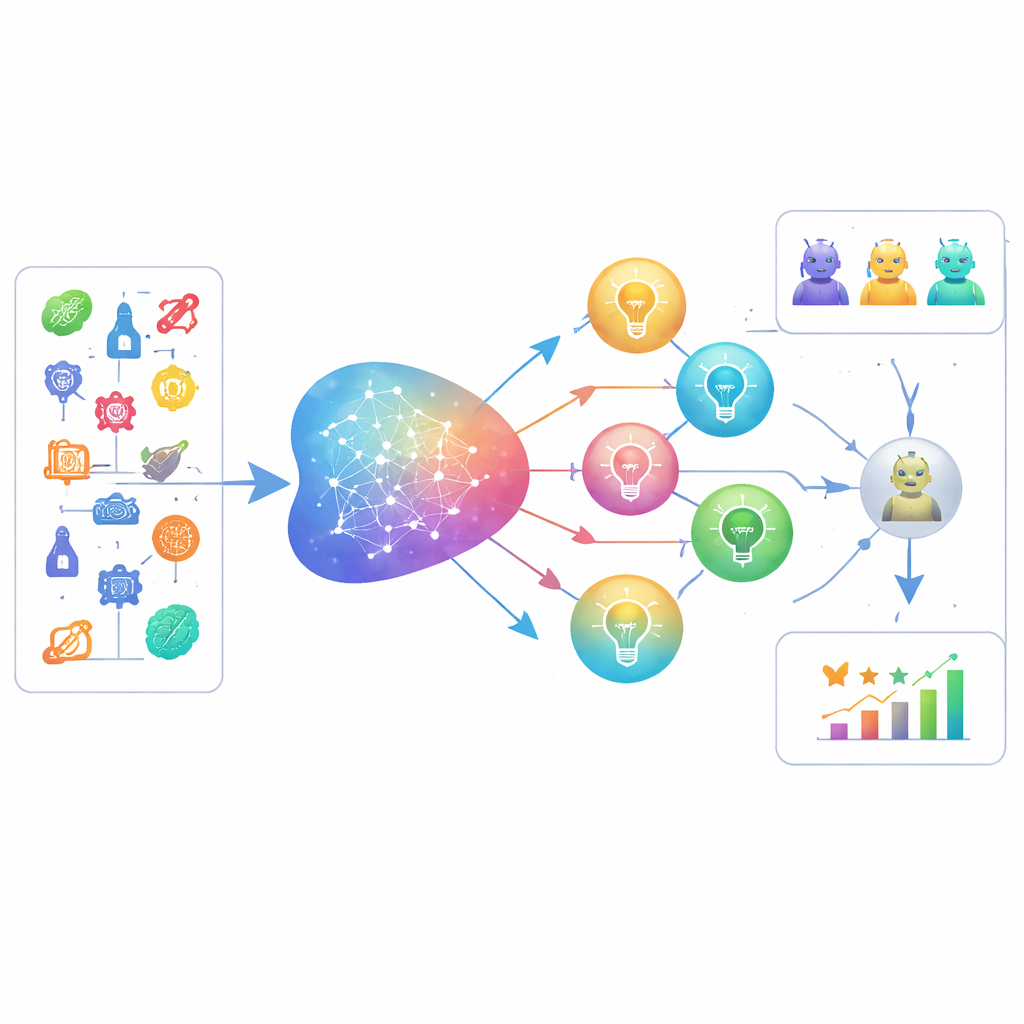
结果揭示了关于人工智能创造力的哪些信息
作者的大规模测试表明,LiveIdeaBench上的表现与标准“通用智能”排行榜呈现出显著不同的排序。一些在数学、编程和推理方面表现优异的知名模型,在从极少提示生成多样、新颖科学点子时并不突出。另一些通用分数较平庸的模型——包括相对小型的模型——在发散性思维上表现出人意料的强劲,有时在与创造力相关的度量上能与领先系统相匹敌甚至超越。研究还发现了大胆性与安全性之间的权衡:提出非常原创方向的模型在可行性上可能较弱,而另一些模型则更偏向实用但不那么令人惊讶。重要的是,更长、更详尽的回答并不可靠地带来更好点子;字数多寡与质量的相关性很弱。
窥探评估机制
为在大规模上近似专家评审,作者大量依赖“以大型语言模型为裁判”。一组精选的强大模型独立评分原创性、可行性和清晰度,另有独立流程检验同一模型在同一关键词下提出的多个点子是否真正不同而非仅仅是措辞变化。灵活性通过考察模型在较弱领域的得分能否维持来刻画,而不仅看其熟悉领域的表现。团队还分析了架构、训练策略与安全策略如何影响创造性输出。带有更严格安全过滤的模型有时会拒绝对某些敏感关键词作答,尽管这是负责任的行为,却会损害其评分。作者指出使用AI裁判存在风险——例如谄媚倾向和在不熟悉科学领域的盲点——但在一个专业数学领域与人类专家的初步一致性检验中显示出一定的匹配。
对AI辅助发现未来的影响
对非专业读者而言,核心结论既简单又有力:在测试上表现好并不自动意味着该AI是进行科学头脑风暴的好伙伴。发散性思维——从单一提示衍生出许多不同且有意义的研究点子的能力——呈现为一种在一定程度上独立的技能,而现有基准在很大程度上忽视了它。 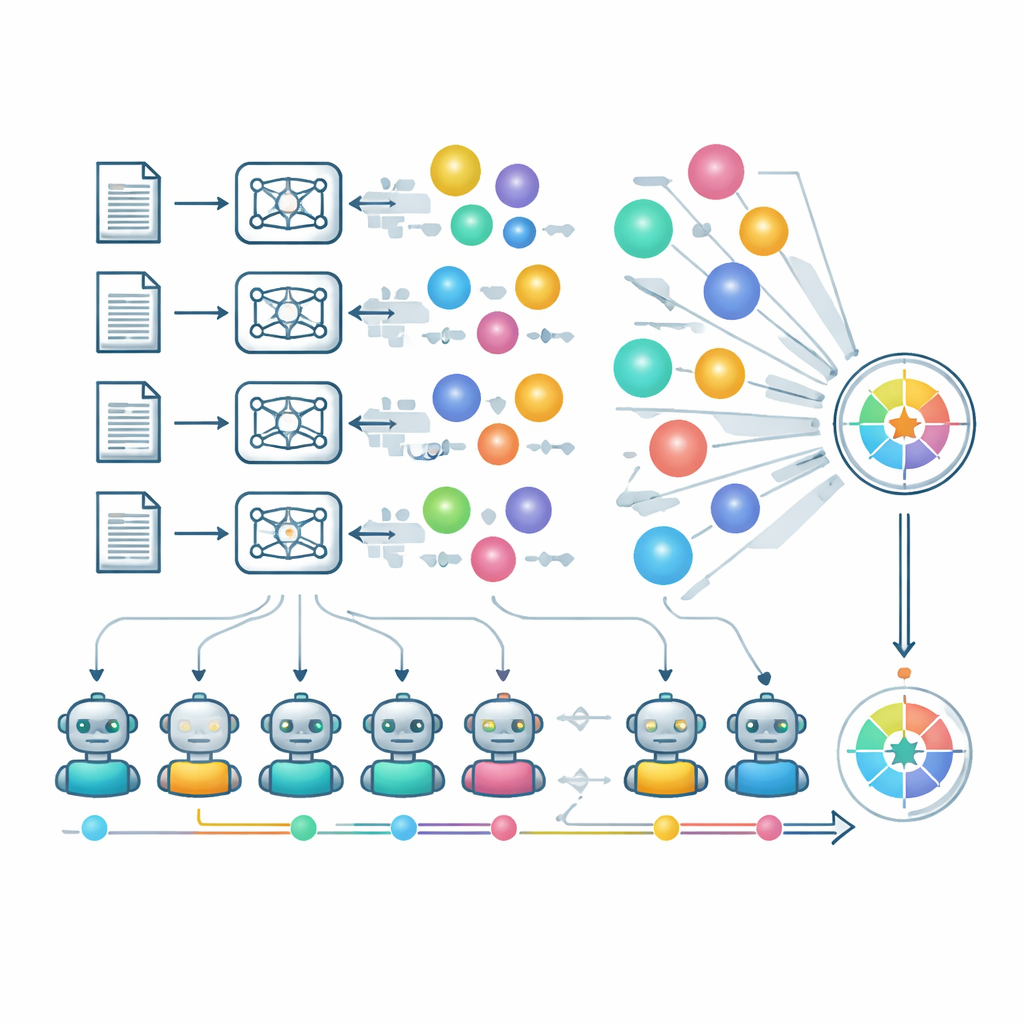
引用: Ruan, K., Wang, X., Hong, J. et al. Evaluating LLMs' divergent thinking capabilities for scientific idea generation with minimal context. Nat Commun 17, 3625 (2026). https://doi.org/10.1038/s41467-026-70245-1
关键词: 人工智能创造力, 发散性思维, 科学创意生成, 大型语言模型, 基准测试