Clear Sky Science · fr
Évaluer les capacités de pensée divergente des LLM pour la génération d’idées scientifiques avec un contexte minimal
Pourquoi c’est important pour les amateurs de science
Une grande partie de l’enthousiasme autour de l’IA moderne provient de son apparente brillance aux tests et examens. Mais les percées scientifiques ne résultent que rarement de la réussite de quiz ; elles commencent par des idées étranges et incomplètes, suscitées par un mot ou une intuition. Cet article pose une question terre-à-terre aux conséquences majeures : si l’on donne aux grands modèles de langage d’aujourd’hui juste un très léger indice — un seul mot-clé scientifique — peuvent-ils réellement brainstormer des idées de recherche nouvelles et plausibles, et en quoi cette « étincelle créative » se rapporte-t-elle aux mesures habituelles d’intelligence artificielle ?
Des machines résolvant des tests aux compagnons d’idées
La plupart des benchmarks actuels traitent l’IA comme un super-étudiant : on fournit aux modèles un contexte riche — résumés complets ou descriptions de problèmes — puis on les note sur leur capacité à trouver la bonne réponse. Ce dispositif mesure surtout la pensée convergente : la réduction d’options vers une solution unique. Les auteurs soutiennent que les premières étapes de la recherche scientifique sont très différentes. Un chercheur commence souvent avec presque rien d’autre qu’un mot-thème, puis associe librement des dizaines de questions et de directions possibles. Pour capter ce type de pensée divergente chez les machines, ils introduisent LiveIdeaBench, un nouveau benchmark qui réduit délibérément le contexte à un seul mot-clé scientifique — comme « microscopie » ou « prévision météorologique » — et demande aux modèles de proposer des idées de recherche courtes et concrètes.
Comment fonctionne le nouveau benchmark
LiveIdeaBench couvre 1180 mots-clés scientifiques populaires répartis sur 22 domaines, de la physique à la médecine en passant par les sciences sociales. Pour chaque mot-clé, plus de 40 modèles de langue de premier plan sont sollicités pour générer des idées scientifiques compactes. Un panel dynamique de modèles performants sert ensuite de « juges » qui évaluent chaque idée selon cinq dimensions inspirées de la créativité : son originalité, sa faisabilité apparente, la clarté de son expression, le nombre d’idées distinctes que le modèle peut produire à partir du même indice (fluidité), et la cohérence de ses performances à travers des sujets très différents (flexibilité). Plusieurs juges attribuent une note à chaque idée, et les scores sont moyennés pour réduire les biais individuels des modèles. Le benchmark est mis à jour régulièrement, tant pour les mots-clés utilisés que pour les modèles évalués, afin de suivre la frontière mouvante de la science et des capacités en IA. 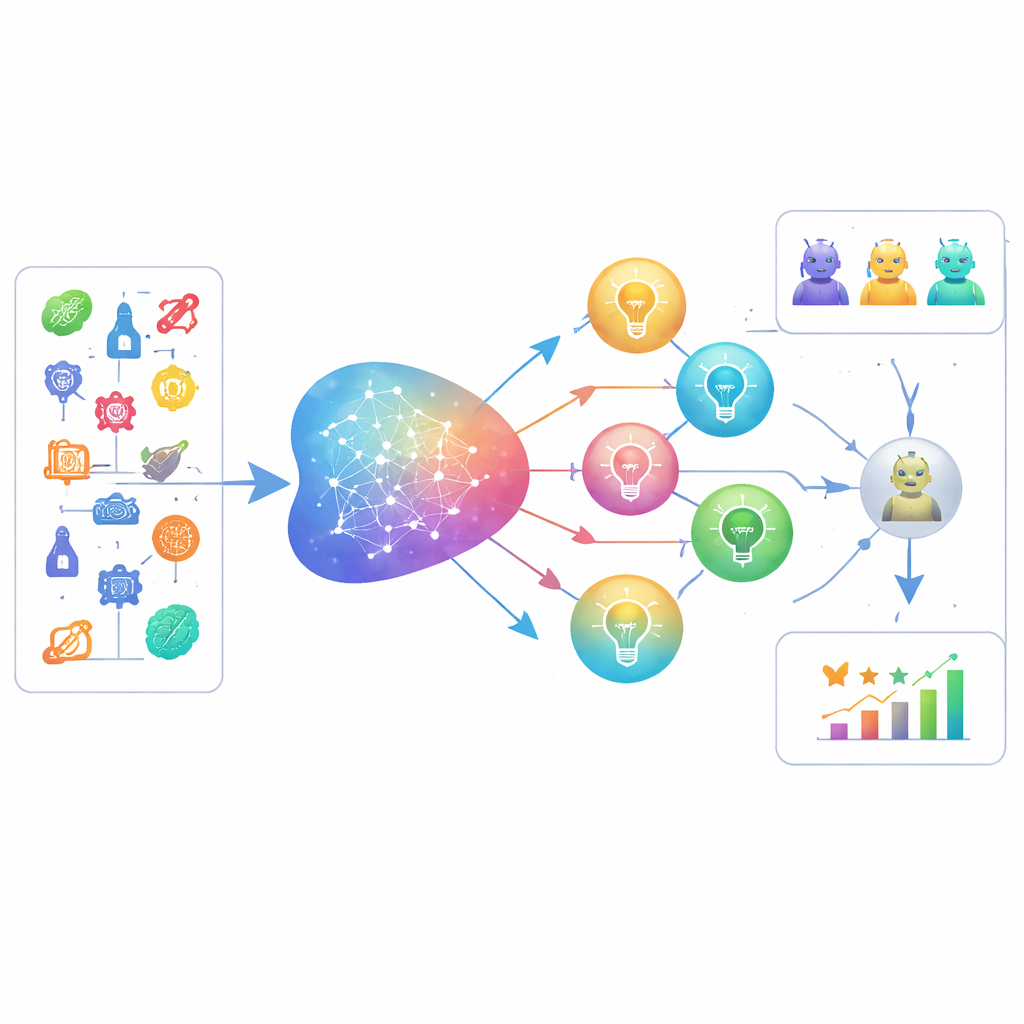
Ce que révèlent les résultats sur la créativité de l’IA
Les tests à grande échelle des auteurs montrent que les classements sur LiveIdeaBench diffèrent sensiblement des palmarès habituels d’« intelligence générale ». Certains modèles bien connus, excellant en mathématiques, en programmation et en raisonnement, ne brillent pas lorsqu’il s’agit de générer des idées scientifiques variées et nouvelles à partir d’invites minimales. D’autres, avec des scores généraux modestes, y compris des modèles relativement petits, montrent une pensée divergente étonnamment forte, égalant parfois voire surpassant les systèmes leaders sur des mesures liées à la créativité. L’étude identifie aussi un compromis entre audace et sécurité des idées : les modèles qui proposent des directions très originales peuvent être moins solides sur la faisabilité, tandis que d’autres privilégient des idées plus pratiques mais moins surprenantes. Fait important, des réponses plus longues et plus élaborées ne produisent pas systématiquement de meilleures idées ; le volume brut de mots est faiblement corrélé à la qualité.
Regarder sous le capot de l’évaluation
Pour approcher une revue experte à grande échelle, les auteurs s’appuient largement sur des « LLM comme juges ». Un groupe sélectionné de modèles puissants note indépendamment l’originalité, la faisabilité et la clarté, et un processus distinct vérifie si plusieurs idées d’un même modèle et d’un même mot-clé sont réellement différentes ou simplement des reformulations. La flexibilité est mesurée en examinant la tenue des scores d’un modèle dans ses domaines plus faibles, pas seulement dans ses domaines familiers. L’équipe analyse également comment l’architecture, les stratégies d’entraînement et les politiques de sécurité influent sur la production créative. Les modèles avec des filtres de sécurité plus stricts refusent parfois de répondre à certains mots-clés sensibles, ce qui pénalise leurs scores malgré un comportement responsable. Les auteurs notent que l’usage de juges IA comporte des risques — tels que la filiation flatteuse et des angles morts dans des domaines scientifiques peu familiers — mais montrent un accord préliminaire avec des experts humains dans un domaine mathématique spécialisé.
Implications pour l’avenir de la découverte assistée par l’IA
Pour un non-spécialiste, la conclusion centrale est simple mais puissante : être bon aux tests ne fait pas automatiquement d’une IA un bon partenaire pour imaginer de nouvelles sciences. La pensée divergente — la capacité à générer de nombreuses idées de recherche différentes et signifiantes à partir d’un seul indice — apparaît comme une compétence en partie indépendante que les benchmarks actuels négligent en grande partie. 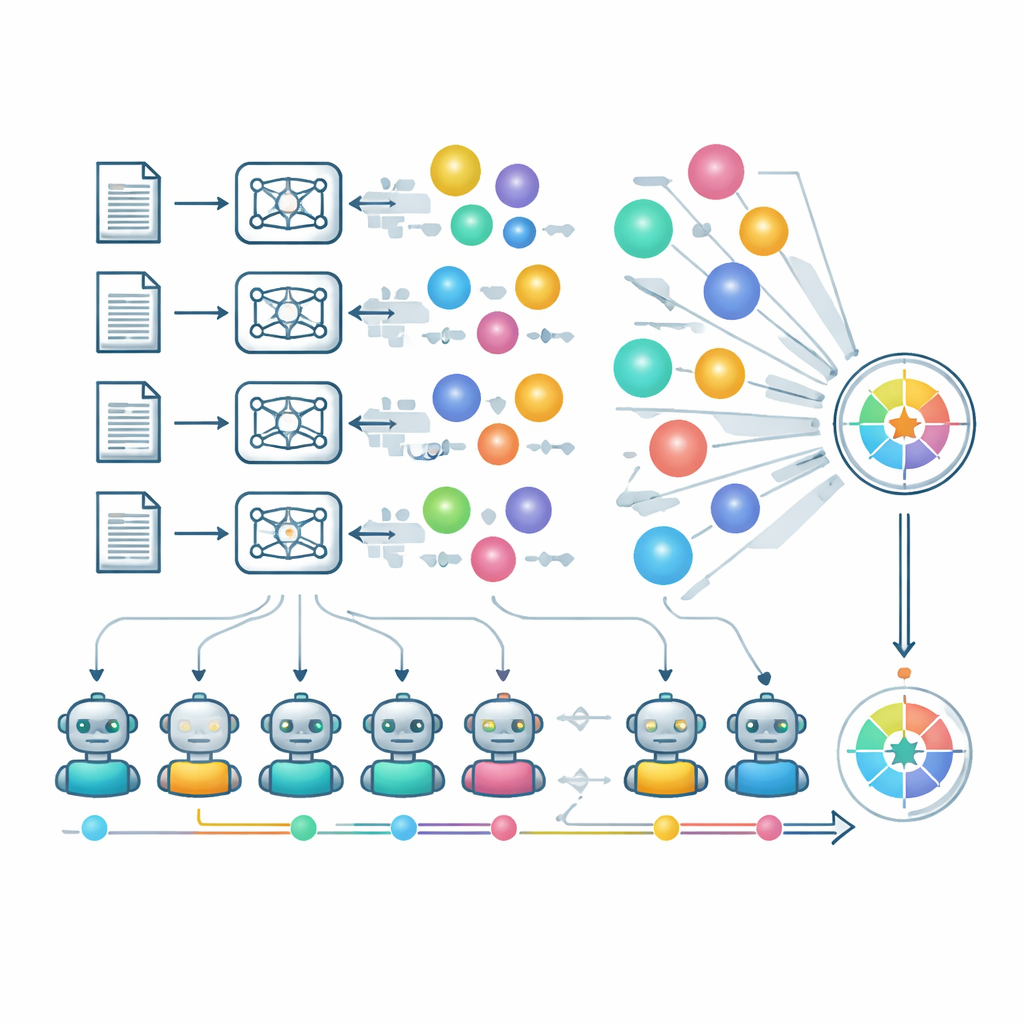
Citation: Ruan, K., Wang, X., Hong, J. et al. Evaluating LLMs' divergent thinking capabilities for scientific idea generation with minimal context. Nat Commun 17, 3625 (2026). https://doi.org/10.1038/s41467-026-70245-1
Mots-clés: créativité IA, pensée divergente, génération d’idées scientifiques, grands modèles de langage, évaluation comparative