Clear Sky Science · de
Bewertung der divergenten Denkfähigkeiten von LLMs zur Generierung wissenschaftlicher Ideen mit minimalem Kontext
Warum das für naturwissenschaftlich interessierte Laien wichtig ist
Ein Großteil der Faszination für moderne KI rührt von ihrer scheinbaren Brillanz bei Tests und Prüfungen. Wissenschaftliche Durchbrüche entstehen jedoch selten dadurch, dass man Quizfragen beantwortet; sie beginnen mit seltsamen, halbgeformten Ideen, ausgelöst von einem einzigen Wort oder einer Ahnung. Dieses Papier stellt eine bodenständige Frage mit weitreichenden Konsequenzen: Wenn man heutigen großen Sprachmodellen nur einen winzigen Hinweis — ein einzelnes wissenschaftliches Stichwort — gibt, können sie dann tatsächlich frische, plausible Forschungsansätze brainstormen, und wie hängt dieser „kreative Funke“ mit den üblichen Messgrößen für KI-Intelligenz zusammen?
Von prüfungsorientierten Maschinen zu Ideenpartnern
Die meisten aktuellen Benchmarks behandeln KI wie eine Super-Schülerin: Modelle erhalten reichhaltigen Kontext — etwa komplette Abstracts oder Problemstellungen — und werden dann danach bewertet, ob sie die richtige Antwort finden. Dieses Setting misst vor allem konvergentes Denken: das Eingrenzen von Optionen auf eine einzige Lösung. Die Autoren argumentieren, dass die frühen Phasen der Wissenschaft sehr anders aussehen. Ein Wissenschaftler beginnt oft mit nahezu nichts als einem Themenwort und assoziiert frei Dutzende möglicher Fragen und Richtungen. Um diese Form des divergenten Denkens in Maschinen abzubilden, führen sie LiveIdeaBench ein, einen neuen Benchmark, der den Kontext bewusst auf genau ein wissenschaftliches Stichwort reduziert — etwa „Mikroskopie“ oder „Wettervorhersage“ — und Modelle auffordert, kurze, konkrete Forschungsideen vorzuschlagen.
Wie der neue Benchmark funktioniert
LiveIdeaBench umfasst 1180 populäre wissenschaftliche Stichwörter aus 22 Feldern, von Physik über Medizin bis Sozialwissenschaften. Zu jedem Stichwort werden mehr als 40 führende Sprachmodelle aufgefordert, kompakte wissenschaftliche Ideen zu erzeugen. Ein dynamisches Panel leistungsstarker Modelle dient dann als „Juroren“, die jede Idee entlang von fünf kreativitätsinspirierten Dimensionen bewerten: Originalität, scheinbare Machbarkeit, Klarheit der Darstellung, wie viele unterschiedliche Ideen das Modell aus demselben Stichwort erzeugen kann (Fluency) und wie konsistent es über sehr verschiedene Themen hinweg performt (Flexibilität). Mehrere Juroren bewerten jede Idee, und die Noten werden gemittelt, um individuellen Modellbias zu reduzieren. Der Benchmark wird regelmäßig aktualisiert, sowohl bezüglich der verwendeten Stichwörter als auch der evaluierten Modelle, sodass er der sich bewegenden Grenze aktueller Wissenschafts- und KI-Fähigkeiten folgt. 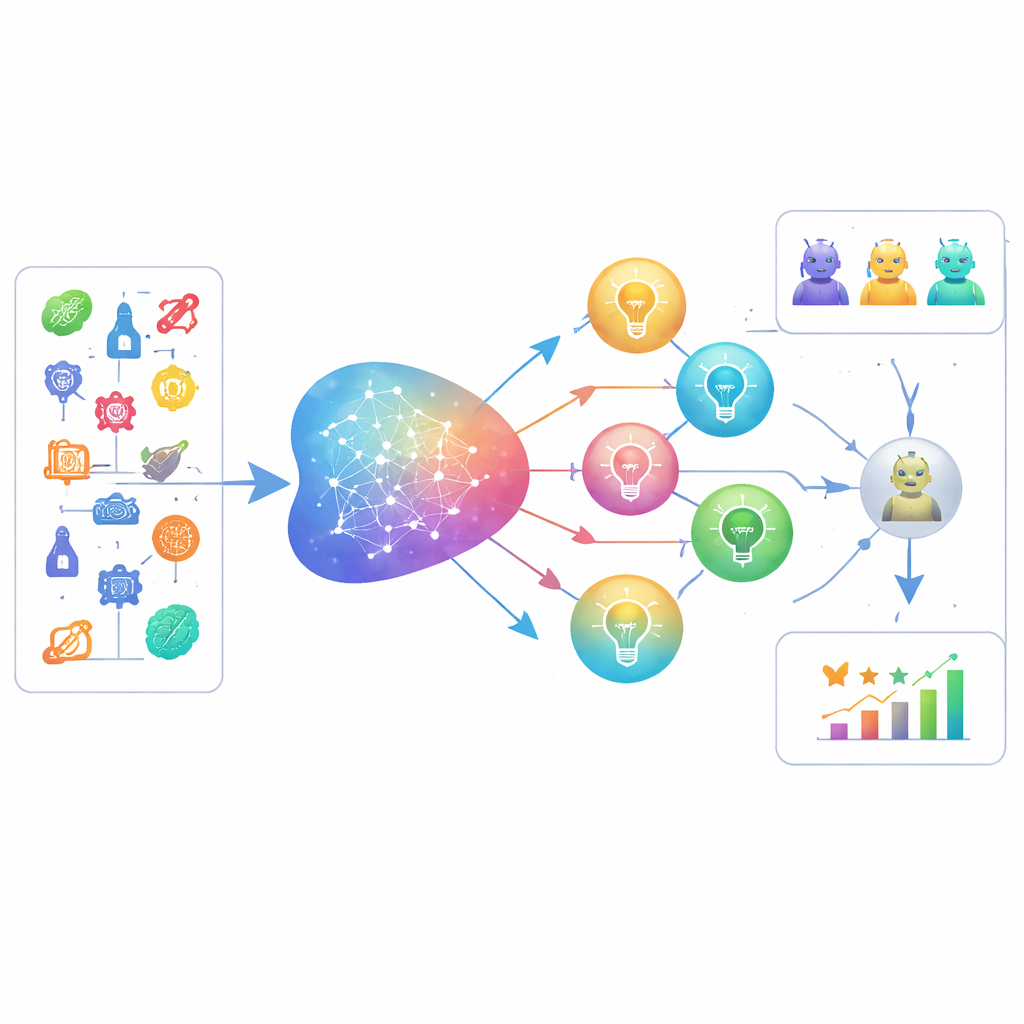
Was die Ergebnisse über KI-Kreativität verraten
Die umfangreichen Tests der Autoren zeigen, dass die Leistung auf LiveIdeaBench auffällig anders aussieht als die Ranglisten auf standardmäßigen „Allgemeinintelligenz“-Leaderboards. Manche bekannte Modelle, die in Mathematik, Programmierung und logischem Schließen glänzen, zeigen sich weniger stark darin, aus minimalen Stichworten vielfältige, neuartige wissenschaftliche Ideen zu generieren. Andere mit moderaten allgemeinen Scores, darunter vergleichsweise kleine Modelle, zeigen überraschend ausgeprägtes divergentes Denken und erreichen in kreativitätsbezogenen Maßen mitunter die Leistung führender Systeme oder übertreffen sie sogar. Die Studie findet außerdem einen Zielkonflikt zwischen Kühnheit und Sicherheit: Modelle, die sehr originelle Richtungen vorschlagen, schneiden möglicherweise schlechter bei der Machbarkeit ab, während andere praktischere, aber weniger überraschende Ideen bevorzugen. Wichtig ist, dass längere, ausführlichere Antworten nicht verlässlich bessere Ideen liefern; die bloße Menge an Worten steht nur schwach mit Qualität in Beziehung.
Blick in die Bewertungsmechanik
Um Expertenbewertung in großem Maßstab zu approximieren, setzen die Autoren stark auf „LLMs als Juroren“. Eine kuratierte Gruppe starker Modelle bewertet unabhängig Originalität, Machbarkeit und Klarheit, und ein separater Prozess überprüft, ob mehrere Ideen desselben Modells und Stichworts wirklich unterschiedlich sind oder nur Umschreibungen darstellen. Flexibilität wird erfasst, indem man betrachtet, wie stabil die Scores eines Modells in seinen schwächeren Bereichen sind, nicht nur in vertrauten Domänen. Das Team analysiert zudem, wie Architektur, Trainingsstrategien und Sicherheitsrichtlinien die kreative Ausgabe beeinflussen. Modelle mit strengeren Sicherheitsfiltern verweigern manche Antworten für bestimmte sensible Stichwörter und verschlechtern dadurch ihre Scores trotz verantwortlichem Verhalten. Die Autoren weisen darauf hin, dass der Einsatz von KI-Juroren Risiken birgt — etwa Gefälligkeit und blinde Flecken in unbekanntem wissenschaftlichem Terrain — zeigen jedoch eine vorläufige Übereinstimmung mit menschlichen Expertinnen und Experten in einem spezialisierten Mathematikbereich.
Folgen für die Zukunft KI-unterstützter Entdeckungen
Für Nicht-Fachleute ist die Kernbotschaft einfach, aber bedeutsam: Gut in Tests zu sein macht eine KI nicht automatisch zu einer guten Partnerin fürs Brainstorming neuer Wissenschaft. Divergentes Denken — die Fähigkeit, aus einem einzigen Hinweis viele unterschiedliche, sinnvolle Forschungsansätze abzuleiten — erweist sich als teilweise unabhängige Fähigkeit, die von aktuellen Benchmarks weitgehend ignoriert wird. 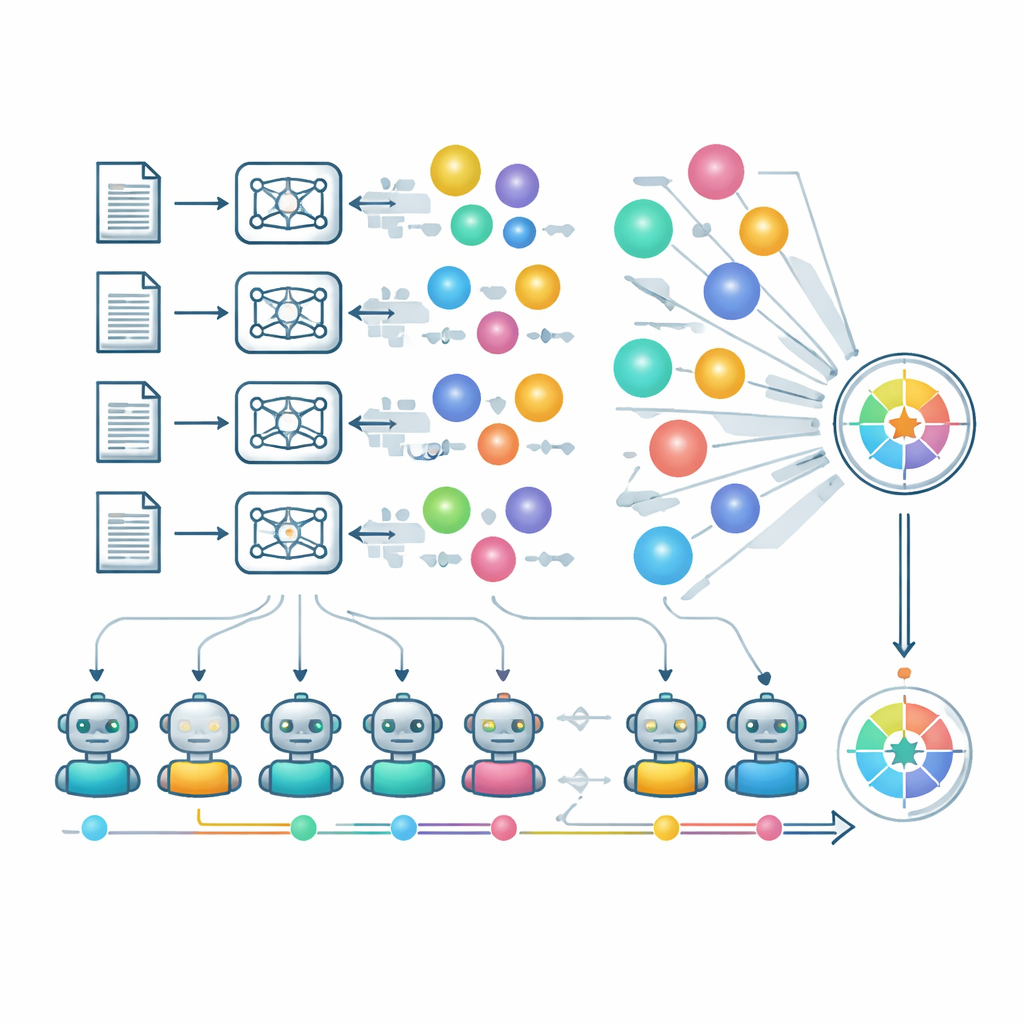
Zitation: Ruan, K., Wang, X., Hong, J. et al. Evaluating LLMs' divergent thinking capabilities for scientific idea generation with minimal context. Nat Commun 17, 3625 (2026). https://doi.org/10.1038/s41467-026-70245-1
Schlüsselwörter: KI-Kreativität, divergentes Denken, Generierung wissenschaftlicher Ideen, große Sprachmodelle, Benchmarking