Clear Sky Science · ja
最小の文脈で科学的アイデアを生成するためのLLMの発散的思考能力の評価
なぜ一般の科学ファンにとって重要なのか
現代のAIに対する興奮の多くは、試験やテストで見せる卓越した能力に由来します。しかし科学的ブレークスルーは、クイズの解答から生まれることは稀で、むしろ一語や直感に触発された奇妙で未完のアイデアから始まります。本論文は日常的でありながら重大な問いを投げかけます:今日の大規模言語モデルに対してほんのわずかなヒント――単一の科学キーワードだけ――を与えたとき、本当に新規でもっともらしい研究アイデアをブレインストームできるのか。そしてその「創造の火花」は、通常のAI知能測定とどう関連するのか?
テスト解答マシンからアイデアの伴走者へ
現在の多くのベンチマークはAIを優秀な学生のように扱います:モデルに充実した文脈(要旨や問題文など)を与えて正答を導けるかを評価します。そうした設定は主に収束的思考――選択肢を絞り込んで単一解に到達する力――を測ります。著者らは、科学の初期段階はこれと大きく異なると論じます。研究者はしばしばほとんど何もない状態、単語一つから出発し、そこから数十の問いや方向性を自由連想します。機械にこの種の発散的思考を捉えさせるため、著者らはLiveIdeaBenchを導入します。これは文脈を意図的に単一の科学キーワード――「顕微鏡法」や「気象予測」など――にまで削ぎ落とし、モデルに短く具体的な研究アイデアを提案させる新しいベンチマークです。
新ベンチマークの仕組み
LiveIdeaBenchは、物理学から医学、社会科学まで22分野にまたがる1180の人気科学キーワードを網羅します。各キーワードについて、40を超える主要な言語モデルがコンパクトな科学的アイデアを生成するよう促されます。動的な上位モデル群が「審査員」として機能し、各アイデアを創造性に着想を得た5つの次元で評価します:独創性、実現可能性、表現の明快さ、同一キューからどれだけ多くの別個のアイデアを生み出せるか(流暢さ)、そして非常に異なるトピック間でどれだけ一貫して性能を発揮できるか(柔軟性)。複数の審査員が各アイデアを採点し、個々のモデルバイアスを下げるためにスコアは平均化されます。ベンチマークは使用するキーワードと評価するモデルの両方を定期的に更新し、科学とAI能力の移り変わる最前線を追います。 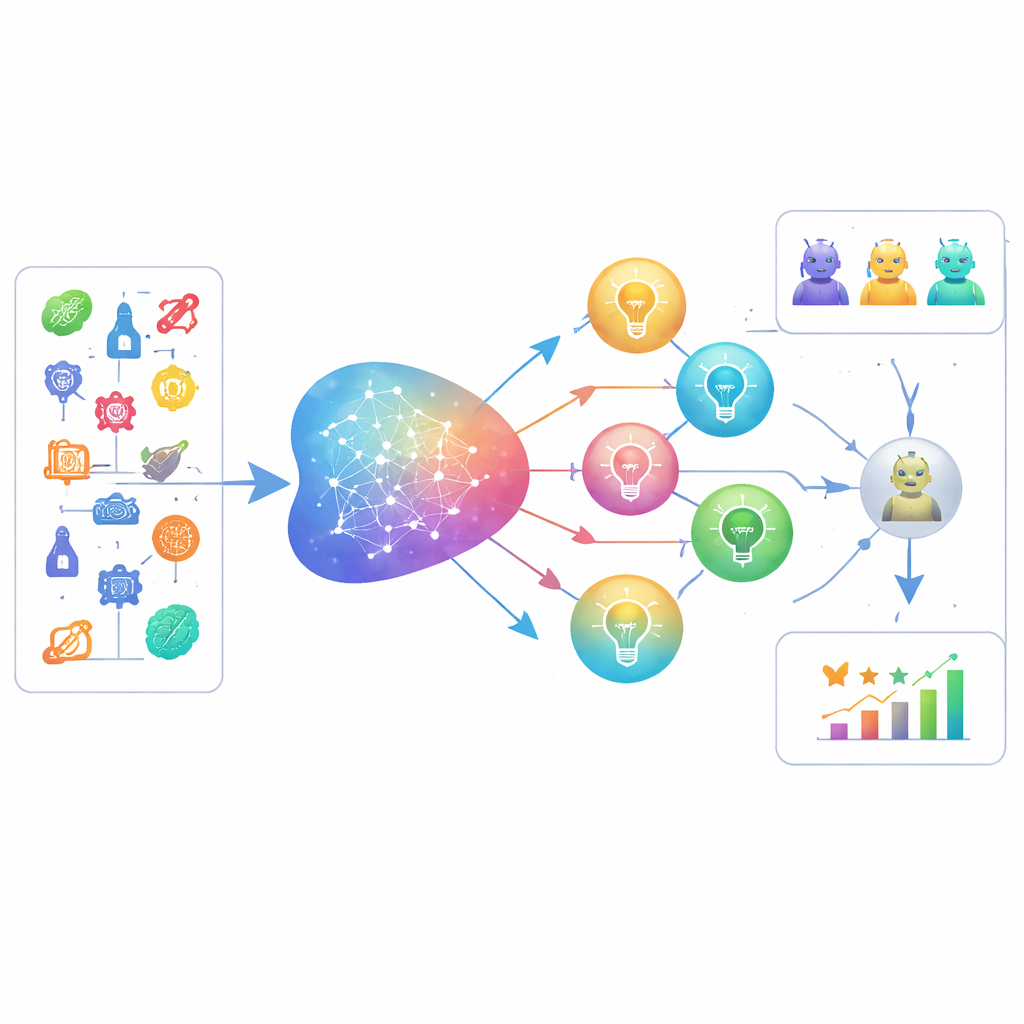
AIの創造性に関する結果の示唆
大規模なテストの結果、LiveIdeaBenchでの成績は標準的な「一般知能」ランキングとは著しく異なる様相を示しました。数学、コーディング、推論で優れることで知られるモデルの中には、最小限のヒントから多様で新規の科学的アイデアを生み出す点では目立たないものがありました。一方で、一般的なスコアは控えめでも、比較的小規模なモデルを含め発散的思考において驚くほど強さを見せるものもあり、創造性関連指標で上位モデルに匹敵あるいは凌ぐこともありました。研究はまた、大胆さと安全性(実現可能性)の間にトレードオフがあることを示します:非常に独創的な方向を提示するモデルは実現可能性で弱くなる傾向があり、逆に実務的だが驚きに欠けるアイデアを好むモデルもあります。重要な点として、より長く詳しい回答が必ずしもより良いアイデアにつながるわけではなく、単なる語数の多さは品質と弱くしか相関しませんでした。
評価メカニズムの中身を覗く
専門家レビューを大規模に近似するため、著者らは「審査員としてのLLM」に大きく依存します。厳選された強力なモデル群が独立に独創性、実現可能性、明快さを評価し、別途のプロセスで同一モデル・同一キーワードから出た複数案が真に異なるものか単なる言い換えに過ぎないかを検証します。柔軟性は、馴染みのある領域だけでなく、モデルの弱い分野におけるスコアの維持状況を観察することで捉えられます。チームはまた、アーキテクチャ、訓練戦略、セーフティ方針が創造的出力に与える影響を分析します。厳格な安全フィルタを持つモデルは特定のセンシティブなキーワードに対して回答を拒むことがあり、責任ある挙動にもかかわらずスコアが下がる場合があります。著者らはAI審査員の使用が追随しがたい媚びや未踏の科学領域における盲点といったリスクを伴うことを指摘しつつ、特殊な数学領域で人間の専門家との予備的一致を示しています。
AI支援による発見の未来への含意
専門外の読者にとっての核心的な結論はシンプルで力強い:テストに強いことが自動的に新しい科学のブレインストーミングに適したパートナーであることを意味しません。発散的思考――単一のヒントから多数の意味のある研究アイデアを派生させる能力――は現行のベンチマークが大部分無視している、部分的に独立したスキルとして浮かび上がります。 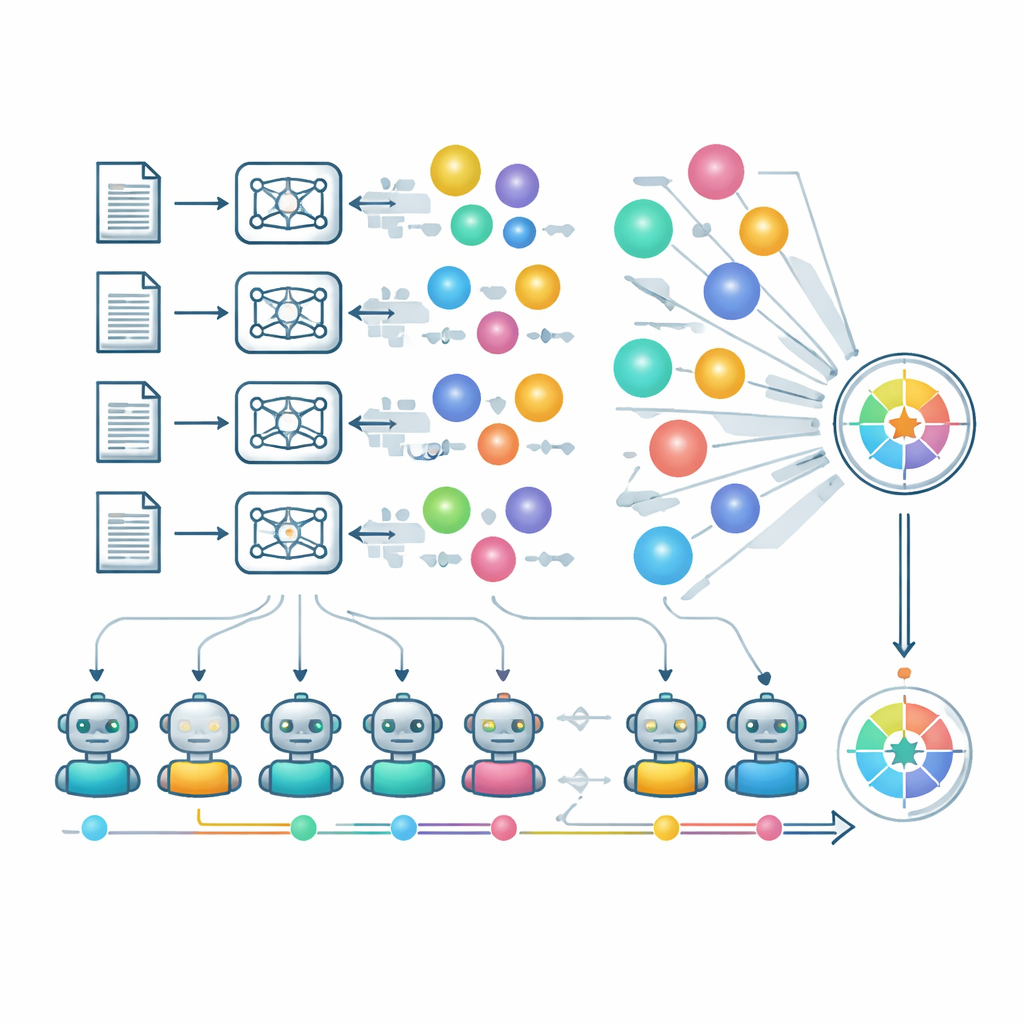
引用: Ruan, K., Wang, X., Hong, J. et al. Evaluating LLMs' divergent thinking capabilities for scientific idea generation with minimal context. Nat Commun 17, 3625 (2026). https://doi.org/10.1038/s41467-026-70245-1
キーワード: AIの創造性, 発散的思考, 科学的アイデア生成, 大規模言語モデル, ベンチマーキング