Clear Sky Science · ru
Оценка способностей больших языковых моделей к дивергентному мышлению для генерации научных идей при минимальном контексте
Почему это важно для обычных любителей науки
Большая часть восторга вокруг современных ИИ связана с их явной успешностью в тестах и экзаменах. Но научные прорывы редко возникают из решения викторин; они начинаются с странных, наполовину сформированных идей, вызванных одним словом или интуицией. В этой работе задают приземлённый вопрос с серьёзными последствиями: если дать современным большим языковым моделям лишь крошечный намёк — одно научное ключевое слово — смогут ли они действительно сгенерировать свежие, правдоподобные исследовательские идеи, и как этот «искус творения» соотносится с обычными мерами интеллекта ИИ?
От машин, решающих тесты, к компаньонам для идей
Большинство современных бенчмарков рассматривают ИИ как супер-студента: моделям дают богатый контекст — например полные аннотации или описания задач — и затем оценивают, находят ли они правильный ответ. Такая постановка в основном измеряет конвергентное мышление: сведение вариантов к единственному решению. Авторы утверждают, что начальные этапы науки выглядят совсем иначе. Учёный часто начинает почти с ничего, имея лишь слово-тему, и затем свободно ассоциирует десятки возможных вопросов и направлений. Чтобы зафиксировать такой тип дивергентного мышления в машинах, они представляют LiveIdeaBench — новый бенчмарк, который намеренно сводит контекст к одному научному ключевому слову — например «микроскопия» или «прогнозирование погоды» — и просит модели предложить краткие, конкретные исследовательские идеи.
Как работает новый бенчмарк
LiveIdeaBench охватывает 1180 популярных научных ключевых слов в 22 областях — от физики до медицины и социальных наук. Для каждого слова более 40 ведущих языковых моделей получают подсказку с просьбой сгенерировать компактные научные идеи. Динамическая панель лучших моделей затем выступает в роли «судей», оценивающих каждую идею по пяти параметрам, вдохновлённым представлениями о креативности: оригинальность, кажущаяся осуществимость, ясность выражения, сколько различных идей модель может выдать по одному и тому же сигналу (поток идей, fluency) и насколько стабильно модель работает на очень разных темах (гибкость). Несколько судей оценивают каждую идею, а баллы усредняются, чтобы снизить индивидуальные предубеждения моделей. Бенчмарк обновляется регулярно — как в части ключевых слов, так и в части оцениваемых моделей — поэтому он следует за движущимся фронтом современной науки и возможностей ИИ. 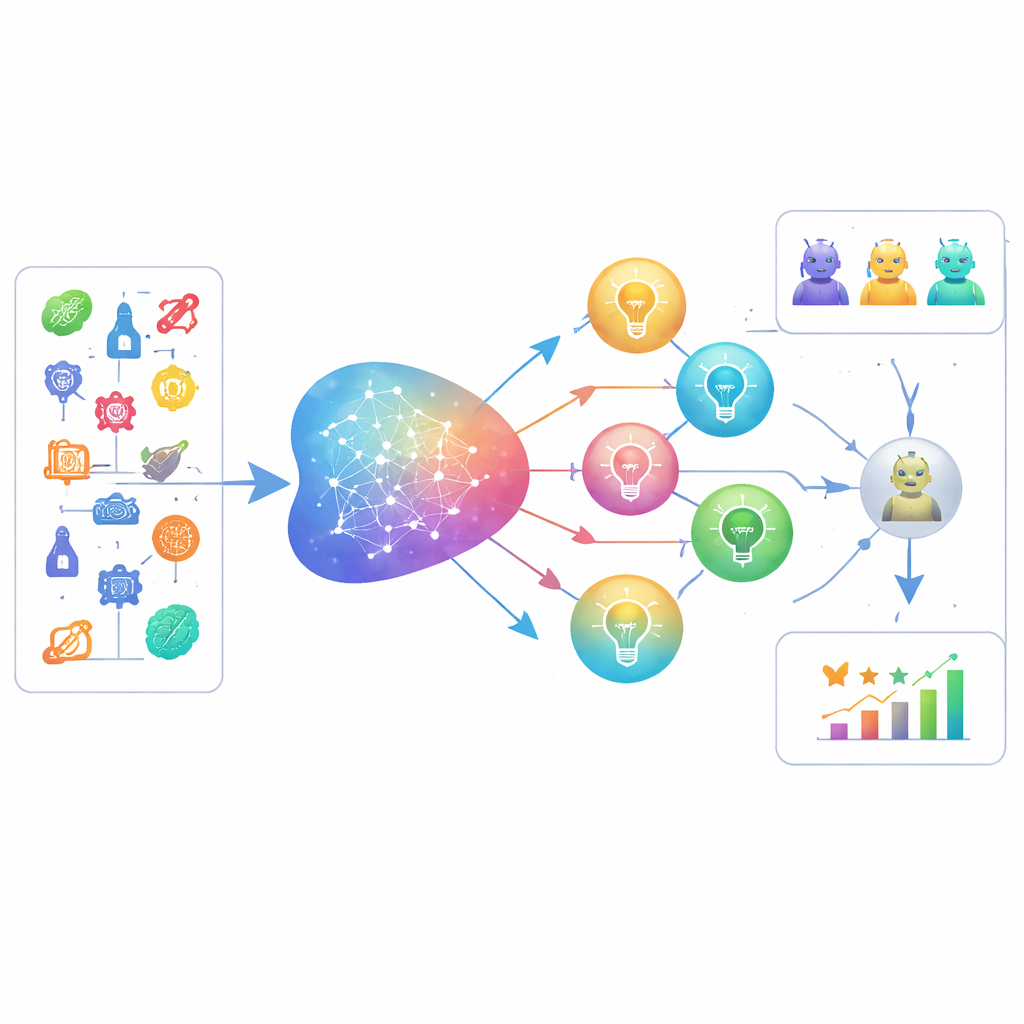
Что показывают результаты о креативности ИИ
Масштабные тесты авторов показывают, что результаты на LiveIdeaBench заметно отличаются от рейтингов на стандартных лидербордах «общего интеллекта». Некоторые известные модели, блестяще работающие в математике, кодировании и рассуждении, не блистают в генерации разнообразных, новых научных идей по минимальным подсказкам. Другие, с умеренными общими показателями, включая сравнительно небольшие модели, демонстрируют удивительно сильное дивергентное мышление, иногда сравнимое или даже превосходящее ведущие системы по показателям, связанным с креативностью. В исследовании также обнаруживается компромисс между смелостью и безопасностью идей: модели, предлагающие очень оригинальные направления, могут уступать в осуществимости, тогда как другие предпочитают более практичные, но менее неожиданные идеи. Важно, что более длинные, более развернутые ответы не гарантируют лучших идей; простое количество слов слабо коррелирует с качеством.
Взгляд внутрь механики оценки
Чтобы приблизить экспертную проверку в масштабе, авторы опираются в большой степени на «БЯМ как судьи» (LLMs as judges). Курированная группа сильных моделей независимо оценивает оригинальность, осуществимость и ясность, а отдельный процесс проверяет, действительно ли несколько идей от одной модели по одному ключевому слову отличаются, а не являются перефразировками. Гибкость фиксируется через анализ того, как удерживаются баллы модели в её слабых областях, а не только в знакомых доменах. Команда также анализирует, как архитектура, стратегии обучения и политики безопасности влияют на творческий результат. Модели со строгими фильтрами безопасности иногда отказываются отвечать на определённые чувствительные ключевые слова, что снижает их баллы несмотря на ответственное поведение. Авторы отмечают, что использование ИИ-судей несёт риски — такие как подхалимство и слепые зоны в незнакомых научных областях — но показывают предварительное совпадение с оценками человеческих экспертов в специализированной математической области.
Последствия для будущего ИИ-ассистированного открытия
Для неспециалиста основной вывод прост и важен: успехи в тестах не делают ИИ автоматически хорошим партнёром для мозгового штурма новых научных идей. Дивергентное мышление — способность порождать множество разных, содержательных исследовательских идей по единому намёку — выступает как отчасти независимый навык, который текущие бенчмарки во многом игнорируют. 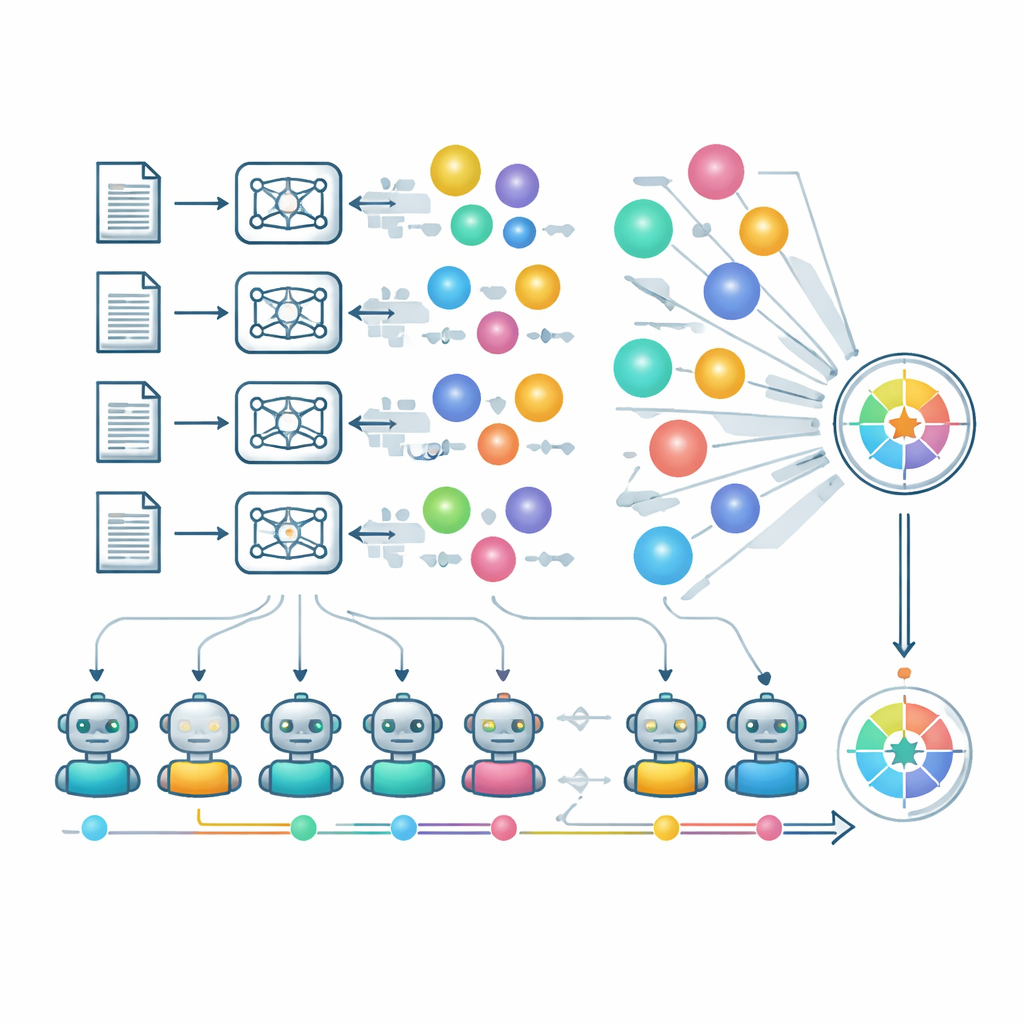
Цитирование: Ruan, K., Wang, X., Hong, J. et al. Evaluating LLMs' divergent thinking capabilities for scientific idea generation with minimal context. Nat Commun 17, 3625 (2026). https://doi.org/10.1038/s41467-026-70245-1
Ключевые слова: креативность ИИ, дивергентное мышление, генерация научных идей, большие языковые модели, бенчмаркинг