Clear Sky Science · pt
Avaliação das capacidades de pensamento divergente de LLMs para geração de ideias científicas com contexto mínimo
Por que isso importa para os fãs de ciência do dia a dia
Muito do entusiasmo em torno da IA moderna vem de sua aparente brilhância em testes e exames. Mas avanços científicos raramente surgem de responder perguntas de prova; eles começam com ideias estranhas e semiformadas provocadas por uma única palavra ou intuição. Este artigo faz uma pergunta prática com grandes consequências: quando você dá aos grandes modelos de linguagem de hoje apenas uma pista mínima — uma palavra-chave científica isolada — eles conseguem realmente gerar ideias de pesquisa novas e plausíveis, e como essa "faísca criativa" se relaciona com as medidas usuais de inteligência em IA?
De máquinas que resolvem testes a companhias de ideias
A maioria dos benchmarks atuais trata a IA como um superaluno: modelos recebem um contexto rico — como resumos completos ou descrições de problemas — e então são avaliados se encontram a resposta certa. Essa configuração mede principalmente o pensamento convergente: reduzir opções a uma única solução. Os autores argumentam que as etapas iniciais da ciência são bem diferentes. Um cientista frequentemente começa com quase nada além de uma palavra-tema, e então associa livremente dezenas de perguntas e direções possíveis. Para capturar esse tipo de pensamento divergente em máquinas, eles apresentam o LiveIdeaBench, um novo benchmark que deliberadamente reduz o contexto a apenas uma palavra-chave científica — como “microscopia” ou “previsão do tempo” — e pede aos modelos que sugiram ideias de pesquisa curtas e concretas.
Como o novo benchmark funciona
O LiveIdeaBench abrange 1180 palavras-chave científicas populares em 22 áreas, da física à medicina e ciências sociais. Para cada palavra-chave, mais de 40 modelos de linguagem de ponta são solicitados a gerar ideias científicas compactas. Um painel dinâmico de modelos de alto desempenho então atua como "juízes" que avaliam cada ideia segundo cinco dimensões inspiradas na criatividade: quão original ela é, se parece factível, quão claramente é expressa, quantas ideias distintas o modelo consegue produzir a partir do mesmo estímulo (fluência), e quão consistentemente ele pode performar em tópicos muito diferentes (flexibilidade). Múltiplos juízes pontuam cada ideia, e as notas são médias para reduzir viés individual do modelo. O benchmark é atualizado regularmente, tanto nas palavras-chave que utiliza quanto nos modelos avaliados, para acompanhar a fronteira em movimento da ciência e da capacidade em IA. 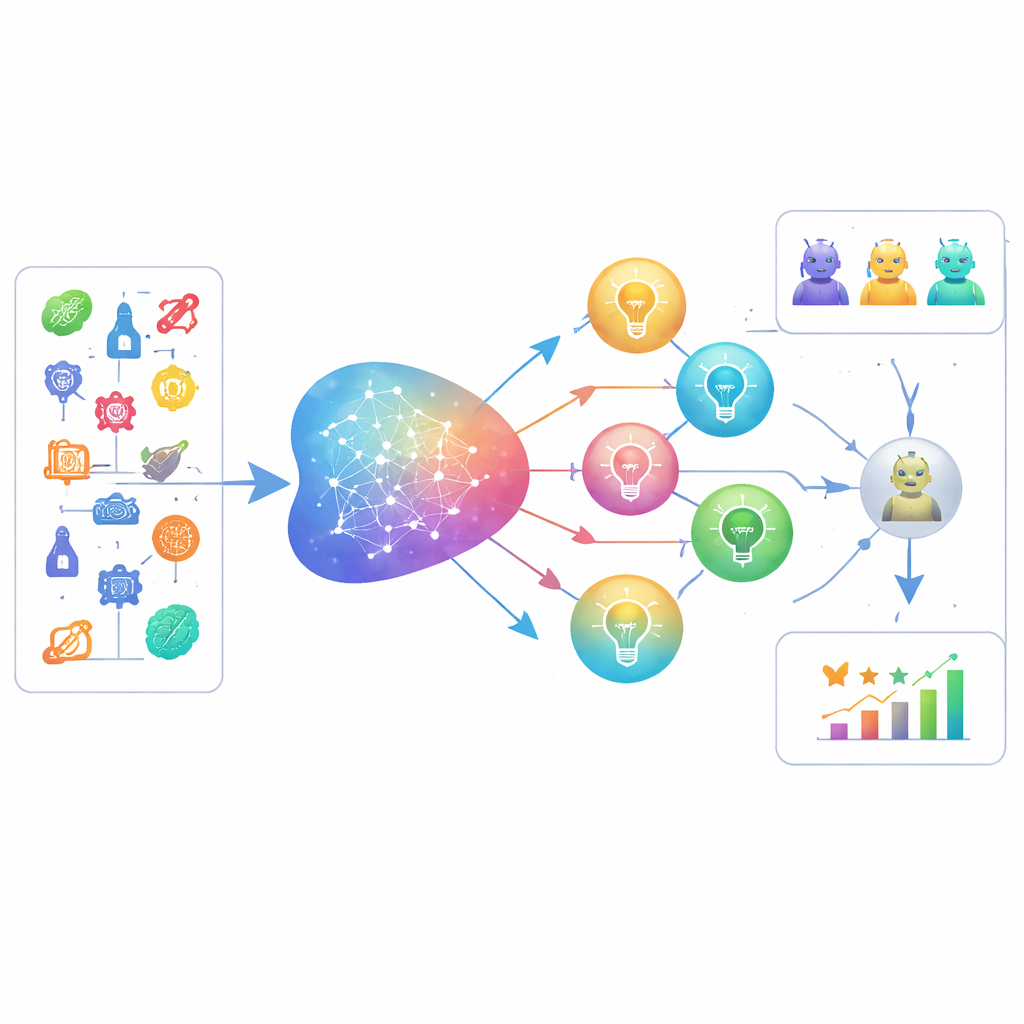
O que os resultados revelam sobre a criatividade da IA
Os testes em larga escala dos autores mostram que o desempenho no LiveIdeaBench difere notavelmente dos rankings em placares padrão de "inteligência geral". Alguns modelos bem conhecidos que se destacam em matemática, programação e raciocínio não brilham ao gerar ideias científicas variadas e novas a partir de prompts mínimos. Outros com pontuações gerais modestas, incluindo modelos comparativamente pequenos, mostram pensamento divergente surpreendentemente forte, às vezes igualando ou até superando sistemas líderes em medidas relacionadas à criatividade. O estudo também identifica uma troca entre ousadia e segurança das ideias: modelos que sugerem direções muito originais podem ser mais fracos em factibilidade, enquanto outros preferem ideias mais práticas, porém menos surpreendentes. Importante, respostas mais longas e elaboradas não produzem consistentemente melhores ideias; o mero volume de palavras tem relação fraca com qualidade.
Uma visão dos mecanismos de avaliação
Para aproximar a revisão de especialistas em escala, os autores dependem fortemente de "LLMs como juízes." Um grupo selecionado de modelos fortes avalia independentemente originalidade, factibilidade e clareza, e um processo separado verifica se múltiplas ideias do mesmo modelo e palavra-chave são realmente diferentes ou apenas reformulações. A flexibilidade é capturada analisando como as pontuações de um modelo se mantêm em suas áreas mais fracas, não apenas em domínios familiares. A equipe também analisa como arquitetura, estratégias de treinamento e políticas de segurança influenciam o resultado criativo. Modelos com filtros de segurança mais rígidos às vezes se recusam a responder para certas palavras-chave sensíveis, prejudicando suas pontuações apesar de um comportamento responsável. Os autores observam que usar juízes de IA traz riscos — como bajulação e pontos cegos em territórios científicos menos familiares —, mas mostram concordância preliminar com especialistas humanos em um domínio matemático especializado.
Implicações para o futuro da descoberta assistida por IA
Para um não especialista, a conclusão principal é simples, mas poderosa: ser bom em testes não torna automaticamente uma IA um bom parceiro para brainstorming de nova ciência. O pensamento divergente — a habilidade de gerar muitas ideias de pesquisa diferentes e significativas a partir de uma única pista — emerge como uma habilidade parcialmente independente que os benchmarks atuais em grande parte ignoram. 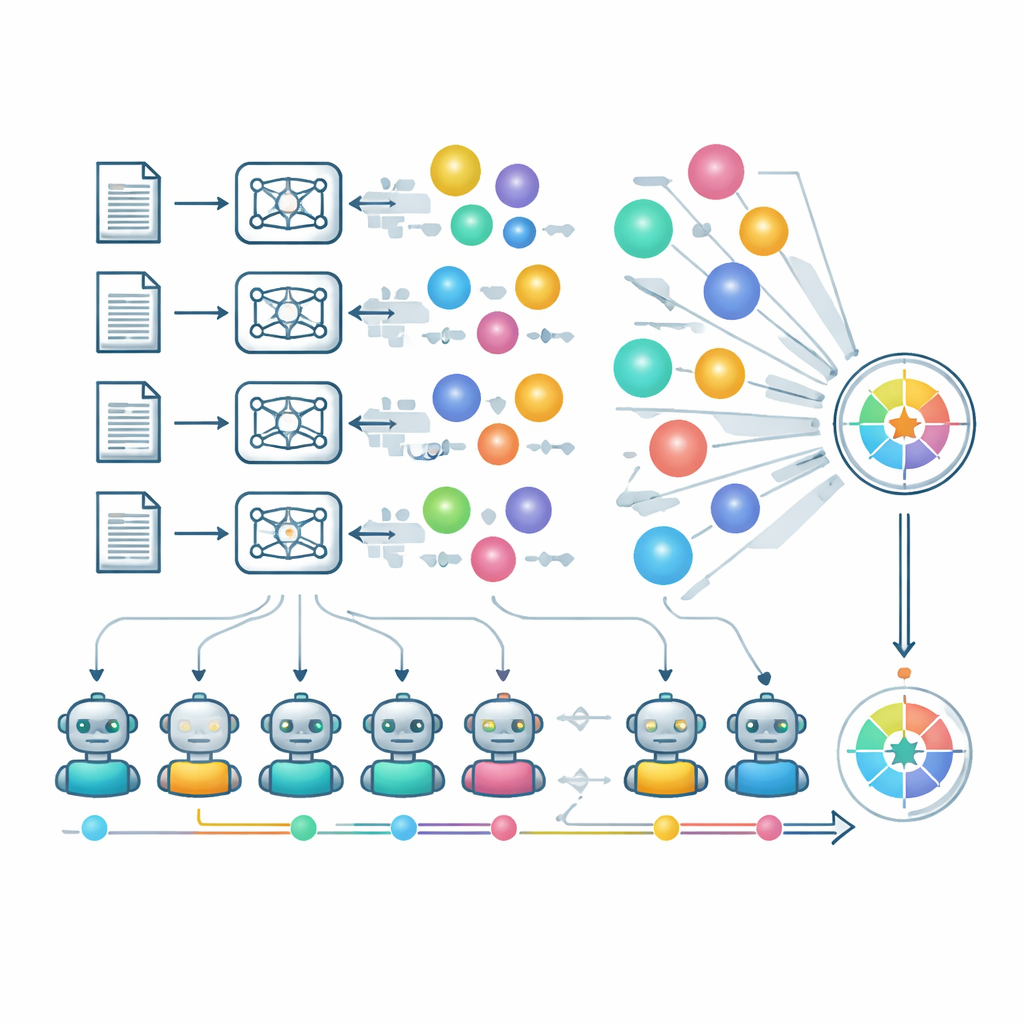
Citação: Ruan, K., Wang, X., Hong, J. et al. Evaluating LLMs' divergent thinking capabilities for scientific idea generation with minimal context. Nat Commun 17, 3625 (2026). https://doi.org/10.1038/s41467-026-70245-1
Palavras-chave: criatividade em IA, pensamento divergente, geração de ideias científicas, grandes modelos de linguagem, avaliação comparativa