Clear Sky Science · tr
Çapraz-kombinasyon stratejisi ve dinamik ağırlıklı stacking topluluğuna dayalı bir kardiyovasküler hastalık tahmin yöntemi
Kalp Risk Tahmininin Neden Önemli Olduğu
Kalp ve damar hastalıkları dünya çapında en çok can alan hastalıklar olmaya devam ediyor ve çoğu zaman belirgin bir uyarı vermeden ortaya çıkıyor. Doktorlar sigara içme, yüksek kolesterol ve yüksek kan şekeri gibi birçok risk faktörünü biliyor, ancak bu işaretleri her birey için bir araya getirmek zor; özellikle veriler karışıksa veya farklı hastaneler ve nüfuslardan geliyorsa. Bu çalışma, birçok tahmin modelini birleştiren ve her birine ne kadar güvenileceğini otomatik olarak öğrenen yeni bir bilgisayar tabanlı yöntem sunuyor; amaç mevcut araçlardan daha doğru ve daha erken kardiyovasküler hastalık riski tespit etmek.
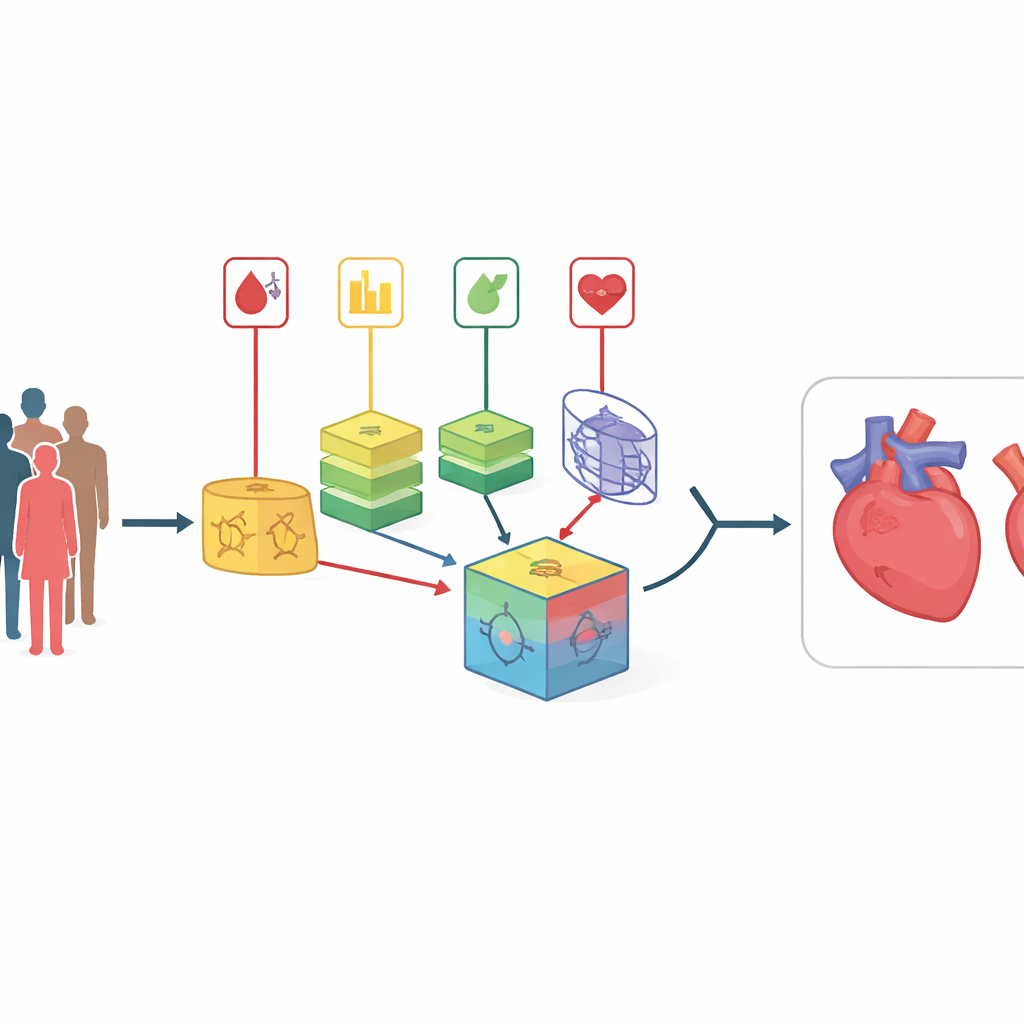
Basit Risk Skorlarının Ötesine Bakmak
İyi bilinen klinik skorlar gibi geleneksel kalp risk hesaplayıcıları, ölçümler ile hastalık arasında oldukça basit, doğrusal ilişkiler varsayar. Oysa gerçeklik, kolesterol, kan basıncı ve glukoz gibi faktörlerin karmaşık etkileşimler içinde olduğu karışık bir ağ gibidir. Son dönem makine öğrenimi yaklaşımları bu tür kalıpları ortaya çıkarabilir, ancak tekil modeller genellikle opak “kara kutu” gibi davranır ve yeni hasta gruplarına uygulandığında başarısız olabilir. Mevcut birleşik model yaklaşımları çoğunlukla bir kez belirlenen sabit ağırlıklara dayanır; bu da hasta popülasyonları veya veri kalitesi zaman içinde değiştiğinde uyum sağlamayı yavaşlatır.
Aynı Hastaya Birden Çok Bakış Açısını Karıştırmak
Yazarlar bu sınırlamaları çapraz-kombinasyon adını verdikleri bir stratejiyle ele alıyorlar. Önemli risk faktörlerini seçmek için tek bir yönteme bağlı kalmak yerine, aynı veri kümelerine sekiz farklı özellik seçimi yöntemi uyguluyorlar. Bu yöntemler basit istatistiksel filtreler, hangi değişkenlerin en çok önem taşıdığını tekrar tekrar test eden prosedürler ve belirli öğrenme algoritmalarıyla sıkı bağlantılı teknikleri içeriyor. Her seçilmiş özellik seti daha sonra basitten olasılığa dayalı modellere, karar ağaçlarına ve sinir ağlarına kadar uzanan 14 çeşitli sınıflayıcıdan biriyle eşleştiriliyor. Toplamda, hasta özellikleri ile kalp hastalığı arasındaki ilişkilere biraz farklı “bakış”lar sunan 112 aday tahmin modeli oluşturuluyor.
Model Ağırlıklarının Zaman İçinde Evrilmesine İzin Vermek
Bu büyük havuzdan en iyi performans gösteren on model seçilerek bir topluluk oluşturuluyor. Buradaki ana yenilik dinamik ağırlıklı stacking çerçevesi. Başlangıçta her temel modele eşit etki veriliyor. Eğitim sırasında sistem, her bir modelin verinin farklı katlarında nasıl performans gösterdiğini tekrar tekrar test ediyor ve hatalara karşılık olarak ağırlığını ayarlıyor—daha iyi performans gösteren modeller daha fazla etki kazanırken, zayıf olanlar kademeli olarak ağırlık kaybediyor. Bu ayarlanmış temel modellerin çıktıları, k-en yakın komşu yaklaşımına dayanan nihai karar vericiyi besleyen yeni bir sinyal setine karıştırılıyor; bu yöntem belirli bir veri şekli varsaymadan yerel kalıpları tanımada başarılı. Bu uyarlanabilir süreç, yeni bir hastane veya hasta karışımı eklendiğinde olduğu gibi veri dağılımındaki kaymalara topluluğun uyum sağlamasını mümkün kılıyor.
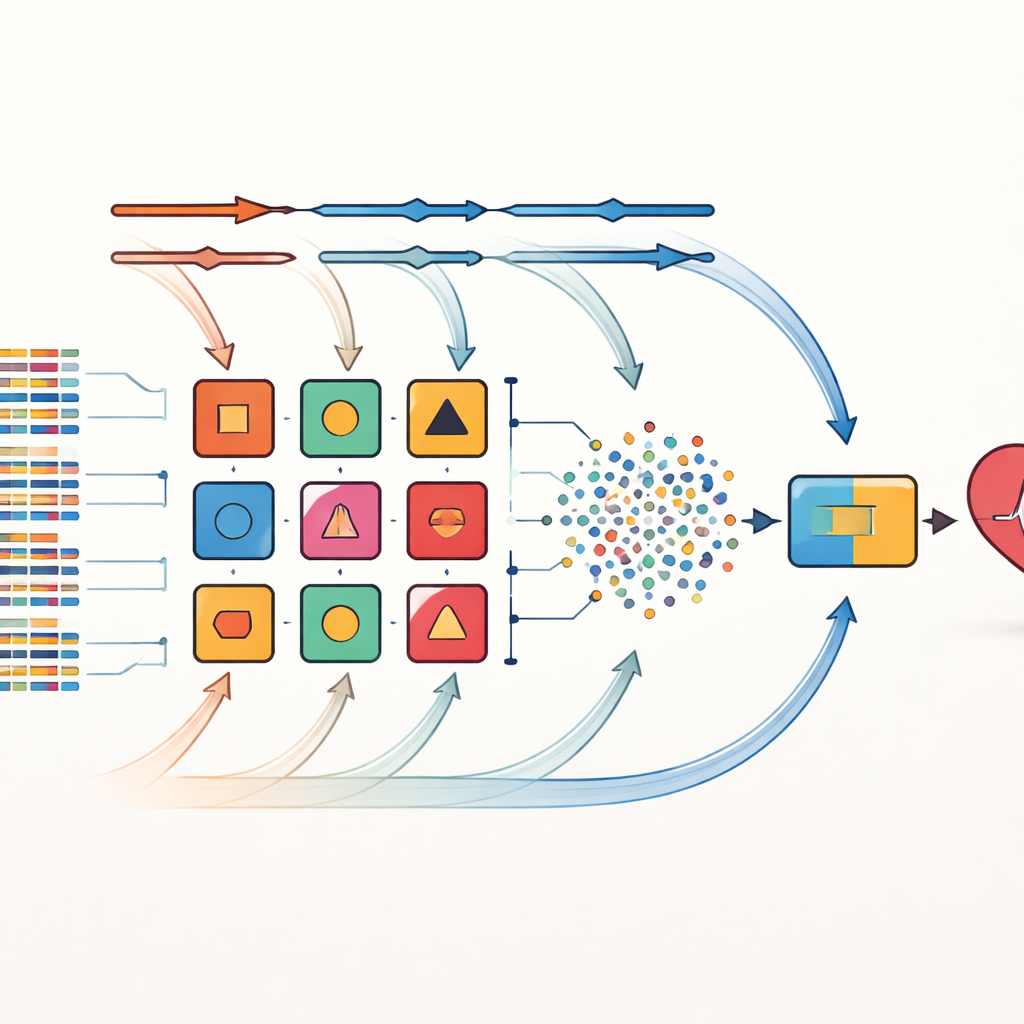
Gerçek Dünya Kalp Veri Setlerinde Test Etme
Yöntem üç tanınmış kardiyovasküler veri setinde değerlendirildi: Cleveland’dan küçük, dengeli bir hastane seti; Framingham’dan daha büyük ve oldukça dengesiz bir toplum çalışması; ve sayısal ile kategorik bilgileri içeren 70.000 kayıtlı çok büyük bir veri kümesi. Araştırmacılar verileri dikkatle temizlediler, uygun yerlerde eksik değerleri doldurdular ve aykırı değerlerle ilgilendiler. Üç veri kümesinin tümünde birleşik modelleri, herhangi bir tekil modelden ve birkaç güncel gelişmiş yöntemden daha yüksek doğruluk ve hasta-hasta olmayan ayrım yeteneği gösterdi. Örneğin, Cleveland verisinde yaklaşık %98 doğruluk ve kalp hastalığı olanlarla olmayanları neredeyse kusursuz ayrıştırma kabiliyeti elde etti ve dengesiz ile büyük ölçekli veri setlerinde de performansı artırdı.
Tahminlerin Kara Kutusunu Açmak
Sistemin klinik uygulamada daha kabul edilebilir olmasını sağlamak için ekip, her bir girdi faktörünün bir tahmine ne kadar katkıda bulunduğunu ölçmek üzere modern bir yorumlanabilirlik tekniği olan SHAP’i kullandı. Model sadece bir hastanın yüksek riskte olduğunu bildirmekle kalmayıp, bu sonuca sigara kullanımı, lipid düzeyleri veya kan şekeri gibi hangi faktörlerin büyük etkide bulunduğunu da gösterebiliyor. İlginç bir şekilde, modelin belirlediği en etkili özellikler, Çin’deki güncel önleme yönergeleriyle uyumlu; bu yönergeler sigara içmeyi, anormal kan yağlarını ve diyabeti kardiyovasküler hastalıkların başlıca değiştirilebilir tetikleyicileri olarak öne çıkarıyor. Yaş ve kan basıncı gibi faktörler hâlâ önemli, ancak bu veri setleri içinde nihai karara yaşam tarzı ve metabolik belirteçlerin katkısı bir miktar daha ağır basmış.
Günlük Sağlık İçin Anlamı
Uzman olmayanlar için ana sonuç şudur: Daha akıllı, daha esnek bilgisayar modelleri, doktorların geri dönüşü olmayan zararlardan önce kalp sorunlarını öngörme yeteneğini keskinleştirebilir. Birçok küçük modeli birleştirip sürekli olarak etkilerini yeniden dengeleyerek önerilen yaklaşım, gürültülü, dengesiz ve değişken tıbbi verilerle daha iyi başa çıkıyor. Aynı zamanda yorumlanabilirlik araçları kullanması, odak noktasını hastalar ve klinisyenlerin gerçekten değiştirebileceği tanıdık risk faktörleri—özellikle sigara, kolesterol ve kan şekeri—üzerinde tutmaya yardımcı oluyor. Gerçek klinik ortamlarda ve daha zengin veri türlerinde ek testlere hâlâ ihtiyaç olmasına rağmen, bu çalışma hem daha doğru hem de kardiyovasküler önleme için rehberlikte daha şeffaf olan tahmin sistemlerine işaret ediyor.
Atıf: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
Anahtar kelimeler: kardiyovasküler hastalık tahmini, topluluk öğrenmesi, tıpta makine öğrenimi, risk faktörleri, model yorumlanabilirliği