Clear Sky Science · it
Un metodo di predizione delle malattie cardiovascolari basato su una strategia di combinazione incrociata e su un ensemble impilato con pesi dinamici
Perché la predizione del rischio cardiaco è importante
Le malattie del cuore e dei vasi sanguigni restano le principali cause di morte a livello globale, spesso manifestandosi senza segnali evidenti. I medici conoscono molti fattori di rischio — come il fumo, il colesterolo alto e l’iperglicemia — ma intrecciare questi indizi per ogni singolo individuo è complesso, soprattutto quando i dati sono disordinati o provengono da ospedali e popolazioni diverse. Questo studio presenta un nuovo metodo informatico che combina molti modelli di predizione e apprende automaticamente quanto fidarsi di ciascuno, con l’obiettivo di individuare il rischio cardiovascolare in modo più accurato e precoce rispetto agli strumenti attuali.
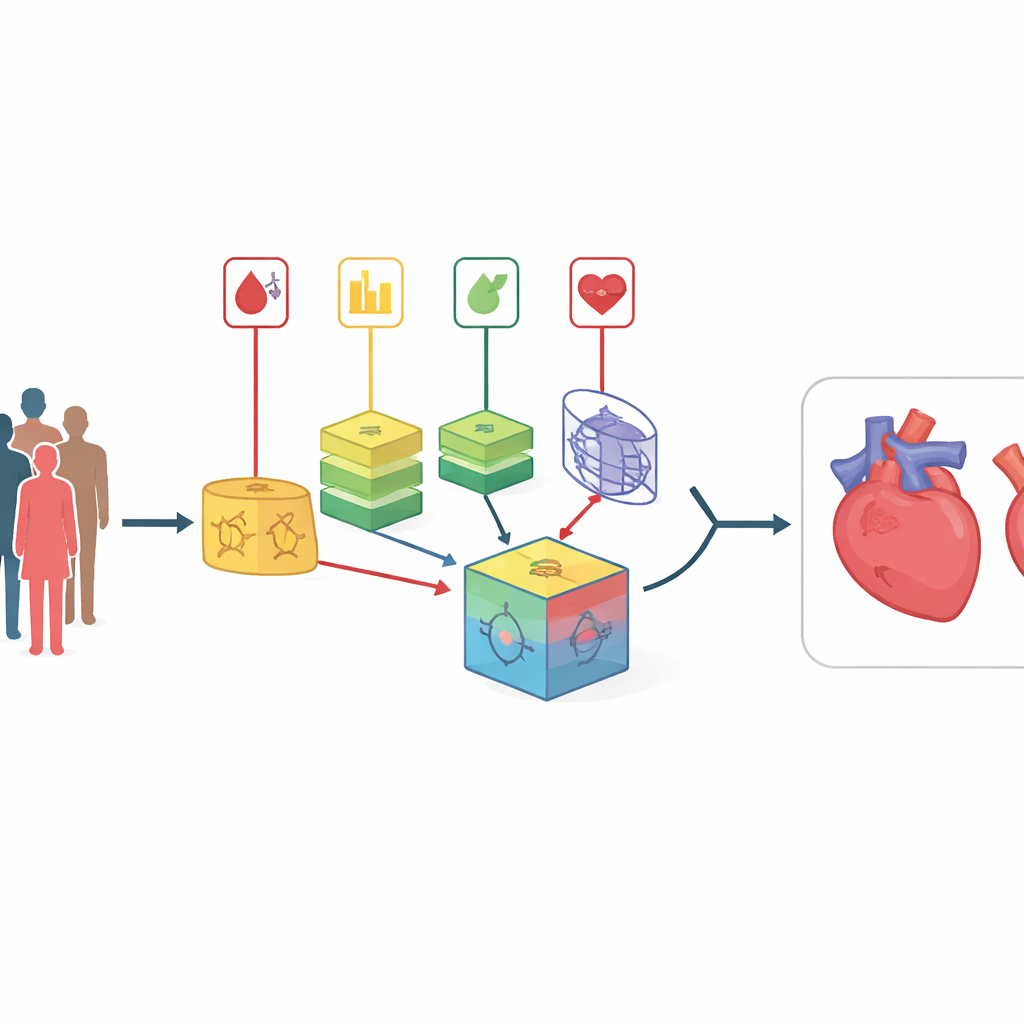
Oltre i semplici punteggi di rischio
I calcolatori di rischio cardiaco tradizionali, come noti punteggi clinici, assumono relazioni piuttosto semplici e lineari tra le misure e la malattia. In realtà il corpo si comporta più come una rete intricata, dove fattori come colesterolo, pressione sanguigna e glucosio interagiscono in modi complessi. Gli approcci recenti di machine learning possono scoprire tali schemi, ma i singoli modelli tendono a comportarsi come “scatole nere” opache e possono fallire quando applicati a nuovi gruppi di pazienti. Gli approcci esistenti che combinano modelli spesso si basano su pesi fissi determinati una sola volta e mai aggiornati, il che li rende lenti ad adattarsi quando la popolazione dei pazienti o la qualità dei dati cambiano nel tempo.
Mischiare molte prospettive sullo stesso paziente
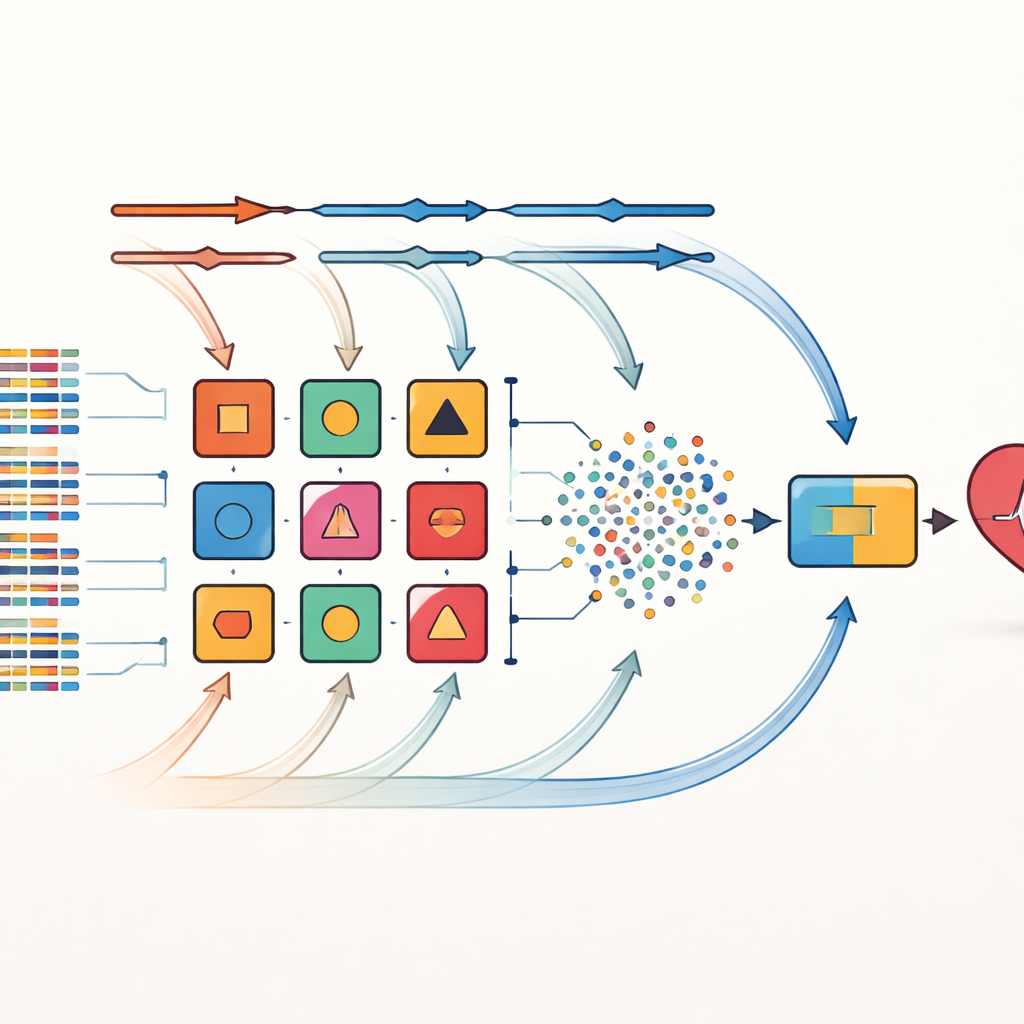
Gli autori affrontano questi limiti con una strategia chiamata combinazione incrociata. Invece di puntare su un unico modo di scegliere le caratteristiche importanti, applicano otto diverse metodologie di selezione delle feature agli stessi set di dati. Questi metodi includono filtri statistici semplici, procedure che testano ripetutamente quali variabili sono più rilevanti e tecniche strettamente collegate a specifici algoritmi di apprendimento. Ogni insieme di feature selezionate viene quindi abbinato a uno dei 14 classificatori diversi, che spaziano da modelli probabilistici semplici ad alberi decisionali e reti neurali. In totale vengono creati 112 modelli candidati di predizione, ciascuno dei quali offre una “visione” leggermente diversa delle relazioni tra le caratteristiche del paziente e le malattie cardiache.
Lasciare che i pesi dei modelli evolvano nel tempo
Da questo grande insieme, vengono scelti i dieci modelli con le migliori prestazioni per formare un ensemble. Qui l’innovazione chiave è un framework di stacking con pesi dinamici. Inizialmente ogni modello base ha la stessa influenza. Durante l’addestramento, il sistema testa ripetutamente quanto bene ciascun modello si comporta su diverse fold dei dati e ne regola il peso in risposta agli errori — i modelli più performanti acquisiscono maggiore influenza, mentre quelli più deboli vengono gradualmente svalutati. Le uscite di questi modelli base ottimizzati vengono quindi fuse in un nuovo insieme di segnali che alimentano un decisore finale basato sull’approccio k-nearest neighbors, che eccelle nel riconoscere schemi locali senza assumere una forma specifica dei dati. Questo processo adattivo permette all’ensemble di aggiustarsi a spostamenti nella distribuzione dei dati, per esempio quando viene introdotto un nuovo ospedale o una diversa composizione di pazienti.
Test su set di dati cardiaci reali
Il metodo è stato valutato su tre noti dataset cardiovascolari: un piccolo set ospedaliero bilanciato di Cleveland, un più ampio e fortemente sbilanciato studio di comunità di Framingham, e un dataset molto grande di 70.000 record con informazioni sia numeriche sia categoriali. I ricercatori hanno pulito attentamente i dati, imputato i valori mancanti dove opportuno e gestito gli outlier. Su tutti e tre i dataset, il modello combinato ha raggiunto maggiore accuratezza e migliore capacità discriminante tra pazienti malati e sani rispetto a ciascuno dei modelli individuali e a diversi metodi avanzati recenti. Per esempio, sui dati di Cleveland ha raggiunto circa il 98% di accuratezza con una capacità quasi perfetta di separare chi ha e chi non ha malattia cardiaca, migliorando inoltre le prestazioni sui dataset sbilanciati e su larga scala.
Aprire la scatola nera delle predizioni
Per rendere il sistema più accettabile nella pratica clinica, il gruppo ha utilizzato SHAP, una tecnica moderna di interpretabilità, per misurare quanto ogni fattore di input contribuisce a una predizione. Invece di limitarsi a segnalare che un paziente è ad alto rischio, il modello può indicare che il comportamento legato al fumo, i livelli lipidici o la glicemia sono stati i principali driver di quella conclusione. È interessante notare che le feature più influenti identificate dal modello corrispondono alle attuali linee guida di prevenzione in Cina, che indicano fumo, dislipidemia e diabete come principali fattori modificabili delle malattie cardiovascolari. Fattori come età e pressione sanguigna rimangono importanti, ma in questi dataset hanno contribuito in misura leggermente minore alla decisione finale rispetto a marcatori metabolici e legati allo stile di vita.
Cosa significa per la salute di tutti i giorni
Per i non specialisti, il messaggio principale è che modelli informatici più intelligenti e flessibili possono migliorare la capacità dei medici di prevedere problemi cardiaci prima che provochino danni irreversibili. Combinando molti modelli più piccoli e riequilibrandone costantemente l’influenza, l’approccio proposto gestisce meglio dati medici rumorosi, sbilanciati e in evoluzione. Allo stesso tempo, l’uso di strumenti di interpretabilità aiuta a mantenere l’attenzione su fattori di rischio familiari — in particolare fumo, colesterolo e glicemia — che pazienti e clinici possono effettivamente modificare. Pur richiedendo ulteriori test in contesti clinici reali e su tipi di dati più ricchi, questo lavoro indica una direzione verso sistemi di predizione più accurati e più trasparenti nel guidare la prevenzione cardiovascolare.
Citazione: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
Parole chiave: predizione delle malattie cardiovascolari, apprendimento ensemble, machine learning in medicina, fattori di rischio, interpretabilià del modello