Clear Sky Science · sv
En metod för att förutsäga kardiovaskulär sjukdom baserad på kors‑kombinationsstrategi och dynamisk viktad stacking‑ensemble
Varför bedömning av hjärtrisk är viktig
Sjukdomar i hjärta och blodkärl är fortfarande de största dödsorsakerna globalt och slår ofta till utan tydliga varningssignaler. Läkare känner till många riskfaktorer — som rökning, högt kolesterol och högt blodsocker — men att väva ihop dessa ledtrådar för varje individ är utmanande, särskilt när data är röriga eller kommer från olika sjukhus och patientgrupper. Denna studie presenterar en ny datorbaserad metod som kombinerar många prediktionsmodeller och automatiskt lär sig hur mycket varje modell ska litas på, med målet att upptäcka risken för kardiovaskulär sjukdom mer precist och tidigare än nuvarande verktyg.
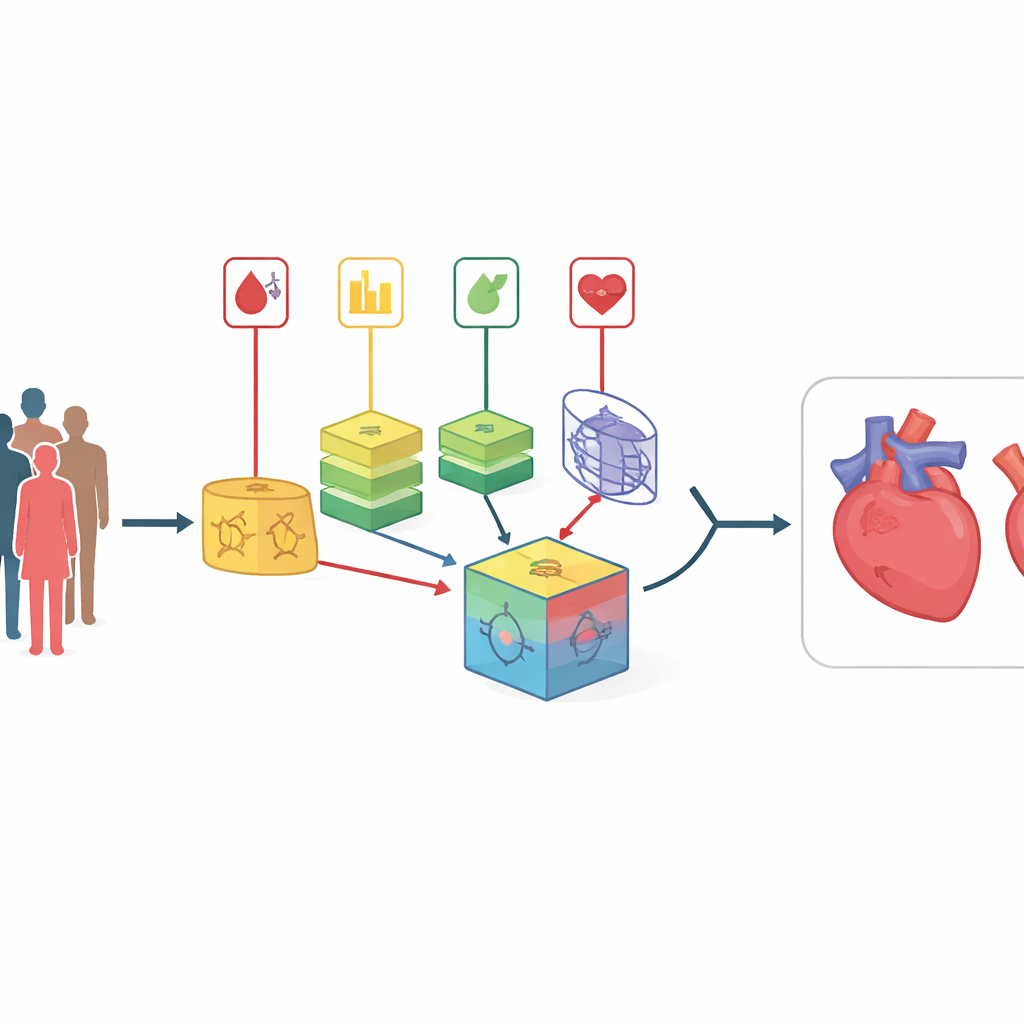
Mer än enkla riskpoäng
Traditionella hjärtriskkalkylatorer, som välkända kliniska poängsystem, antar ofta relativt enkla, linjära relationer mellan mätvärden och sjukdom. I verkligheten beter sig kroppen snarare som ett invecklat nätverk där faktorer som kolesterol, blodtryck och glukos samverkar på komplexa sätt. Nyare maskininlärningsmetoder kan upptäcka sådana mönster, men enskilda modeller tenderar att vara ogenomskinliga ”svarta lådor” och kan misslyckas när de tillämpas på nya patientgrupper. Befintliga kombinerade‑modellmetoder förlitar sig ofta på fasta vikter som bestäms en gång och aldrig uppdateras, vilket gör dem långsamma att anpassa sig när patientpopulationer eller datakvalitet förändras över tid.
Att blanda många perspektiv på samma patient
Författarna angriper dessa begränsningar med en strategi de kallar kors‑kombination. Istället för att satsa på ett enda sätt att välja viktiga riskfaktorer använder de åtta olika funktion‑urvalsmetoder på samma dataset. Dessa metoder inkluderar enkla statistiska filter, procedurer som upprepade gånger testar vilka variabler som är viktigast, och tekniker som är tätt kopplade till specifika inlärningsalgoritmer. Varje valt funktionsset paras sedan med en av 14 olika klassificerare, från enkla sannolikhetsbaserade modeller till beslutsträd och neurala nätverk. Totalt skapas 112 kandidatprediktionsmodeller, vardera som erbjuder en något annorlunda ”blick” över sambanden mellan patientegenskaper och hjärtsjukdom.
Låta modellvikter utvecklas över tid
Från denna stora pool väljs de tio bäst presterande modellerna för att bilda en ensemble. Huvudnyheten här är ett dynamiskt viktat stacking‑ramverk. Inledningsvis ges varje basmodell lika stort inflytande. Under träningen testar systemet upprepade gånger hur väl varje modell presterar på olika foldar av datan och justerar dess vikt utifrån fel — modeller som presterar bättre får mer inflytande, medan svagare modeller successivt nedviktas. Utgångarna från dessa finjusterade basmodeller blandas till en ny uppsättning signaler som matas till en slutgiltig beslutsfattare baserad på k‑närmaste‑grannar‑metoden, vilken är bra på att känna igen lokala mönster utan att anta en specifik datadistribution. Denna adaptiva process gör att ensemblet kan anpassa sig till skiftningar i datadistributionen, till exempel när ett nytt sjukhus eller en ny patientmix introduceras.
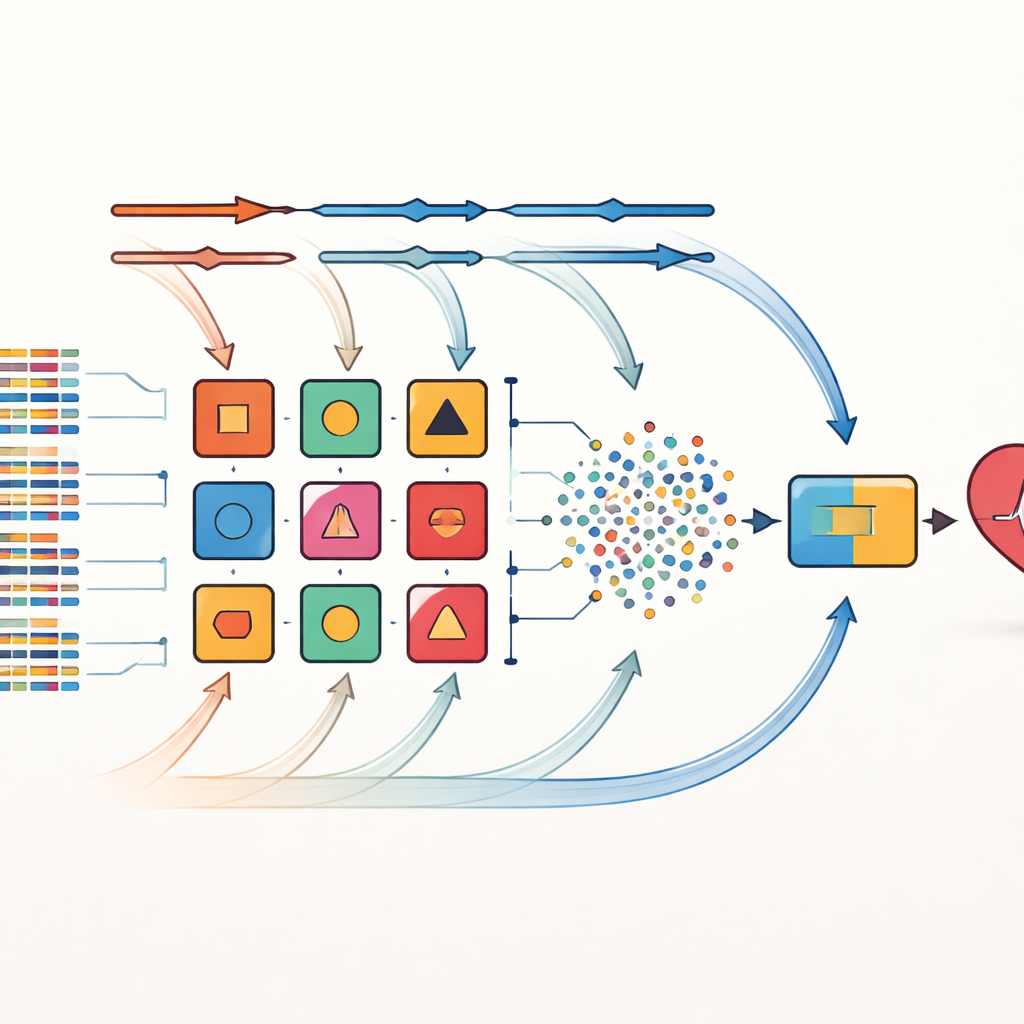
Testning på verkliga hjärtdatamängder
Metoden utvärderades på tre välkända kardiovaskulära dataset: en liten, balanserad sjukhusmängd från Cleveland, en större och starkt obalanserad befolkningsstudie från Framingham, och ett mycket stort dataset med 70 000 poster innehållande både numerisk och kategorisk information. Forskarna rengjorde data noggrant, kompletterade saknade värden där det var lämpligt och hanterade avvikande observationer. Över alla tre dataset uppnådde deras kombinerade modell högre noggrannhet och bättre diskriminering mellan sjuka och friska patienter än någon av de enskilda modellerna och flera nyare avancerade metoder. Till exempel nådde den på Cleveland‑datan cirka 98 procent noggrannhet med en nästan perfekt förmåga att skilja dem med och utan hjärtsjukdom, och den förbättrade även prestandan på de obalanserade och storskaliga dataseten.
Att öppna upp prediktionssvarta lådan
För att göra systemet mer acceptabelt i klinisk praxis använde teamet SHAP, en modern förklarbarhetsteknik, för att uppskatta hur mycket varje insatsfaktor bidrar till en prediktion. I stället för bara rapportera att en patient har hög risk kan modellen ange att rökning, lipidnivåer eller blodglukos var stora drivkrafter bakom slutsatsen. Intressant nog överensstämmer de mest inflytelserika funktionerna som modellen identifierade med nuvarande preventiva riktlinjer i Kina, som pekar ut rökning, onormala blodfetter och diabetes som viktiga modifierbara drivkrafter för kardiovaskulär sjukdom. Faktorer som ålder och blodtryck är fortfarande viktiga, men inom dessa dataset bidrog de något mindre till det slutliga beslutet än livsstils‑ och metaboliska markörer.
Vad detta betyder för vardagshälsa
För icke‑specialister är huvudslutsatsen att smartare, mer flexibla datoriserade modeller kan skärpa läkares förmåga att förutse hjärtproblem innan de orsakar irreversibla skador. Genom att kombinera många mindre modeller och ständigt ombalansera deras inflytande hanterar den föreslagna metoden bättre brusiga, obalanserade och föränderliga medicinska data. Samtidigt hjälper användningen av förklarbarhetsverktyg att hålla fokus på bekanta riskfaktorer — särskilt rökning, kolesterol och blodsocker — som patienter och kliniker faktiskt kan påverka. Även om ytterligare testning i verkliga kliniska miljöer och på rikare datatyper fortfarande behövs, pekar detta arbete mot prediktionssystem som både är mer precisa och mer transparenta för att vägleda förebyggande insatser mot kardiovaskulär sjukdom.
Citering: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
Nyckelord: förutsägelse av kardiovaskulär sjukdom, ensembleinlärning, maskininlärning inom medicin, riskfaktorer, modellförklarbarhet