Clear Sky Science · pl
Metoda przewidywania chorób sercowo-naczyniowych oparta na strategii krzyżowej kombinacji i dynamicznym ważonym zestawieniu
Dlaczego przewidywanie ryzyka sercowego ma znaczenie
Choroby serca i naczyń krwionośnych pozostają główną przyczyną zgonów na całym świecie, często pojawiając się bez wyraźnych ostrzeżeń. Lekarze znają wiele czynników ryzyka — takich jak palenie, wysoki poziom cholesterolu czy podwyższony poziom cukru we krwi — ale połączenie tych wskazówek dla konkretnej osoby jest trudne, zwłaszcza gdy dane są niekompletne lub pochodzą z różnych szpitali i populacji. W badaniu przedstawiono nową metodę komputerową, która łączy wiele modeli predykcyjnych i automatycznie uczy się, ile ufać każdemu z nich, dążąc do dokładniejszego i wcześniejszego wykrywania ryzyka chorób sercowo-naczyniowych niż dostępne obecnie narzędzia.
Wyjście poza proste wyniki ryzyka
Tradycyjne kalkulatory ryzyka sercowego, jak dobrze znane kliniczne skale, zakładają dość proste, liniowe zależności między pomiarami a chorobą. W rzeczywistości organizm zachowuje się raczej jak splątana sieć, w której czynniki takie jak cholesterol, ciśnienie krwi i glukoza wchodzą w złożone interakcje. Nowoczesne podejścia oparte na uczeniu maszynowym potrafią odkrywać takie wzorce, ale pojedyncze modele często funkcjonują jak nieprzezroczyste „czarne skrzynki” i mogą zawodzić przy zastosowaniu do nowych grup pacjentów. Istniejące metody łączenia modeli często opierają się na stałych wagach ustalonych raz i nigdy nieaktualizowanych, co utrudnia adaptację, gdy zmieniają się populacje pacjentów lub jakość danych w czasie.
Mieszanie wielu spojrzeń na tego samego pacjenta
Autorzy rozwiązują te ograniczenia za pomocą strategii nazwanej krzyżową kombinacją. Zamiast polegać na jednym sposobie wyboru istotnych cech, stosują osiem różnych metod selekcji cech na tych samych zbiorach danych. Metody te obejmują proste filtry statystyczne, procedury wielokrotnie testujące, które zmienne mają znaczenie, oraz techniki ściśle powiązane z konkretnymi algorytmami uczenia. Każdy wybrany zestaw cech łączy się następnie z jednym z 14 różnych klasyfikatorów, od prostych modeli opartych na prawdopodobieństwie po drzewa decyzyjne i sieci neuronowe. Łącznie powstaje 112 kandydackich modeli predykcyjnych, z których każdy oferuje nieco inne „spojrzenie” na zależności między cechami pacjenta a chorobą serca.
Pozwalanie wagom modeli ewoluować w czasie
Z tej dużej puli wybieranych jest dziesięć najlepiej działających modeli, które tworzą zespół. Kluczową innowacją jest tutaj ramy dynamicznego ważonego zestawienia (dynamic weighted stacking). Początkowo każdy model bazowy ma równy wpływ. Podczas treningu system wielokrotnie ocenia, jak dobrze dany model radzi sobie na różnych podziałach danych i dostosowuje jego wagę w odpowiedzi na błędy — modele działające lepiej zyskują większy wpływ, podczas gdy słabsze są stopniowo deprecjonowane. Wyjścia tych dostrojonych modeli bazowych są łączone w nowy zestaw sygnałów, które trafiają do ostatecznego decydenta opartego na podejściu k-najbliższych sąsiadów, które świetnie rozpoznaje lokalne wzorce bez zakładania konkretnego kształtu rozkładu danych. Ten adaptacyjny proces pozwala zespołowi dostosowywać się do zmian w rozkładzie danych, na przykład gdy do systemu dołącza nowy szpital lub zmienia się mieszanka pacjentów.
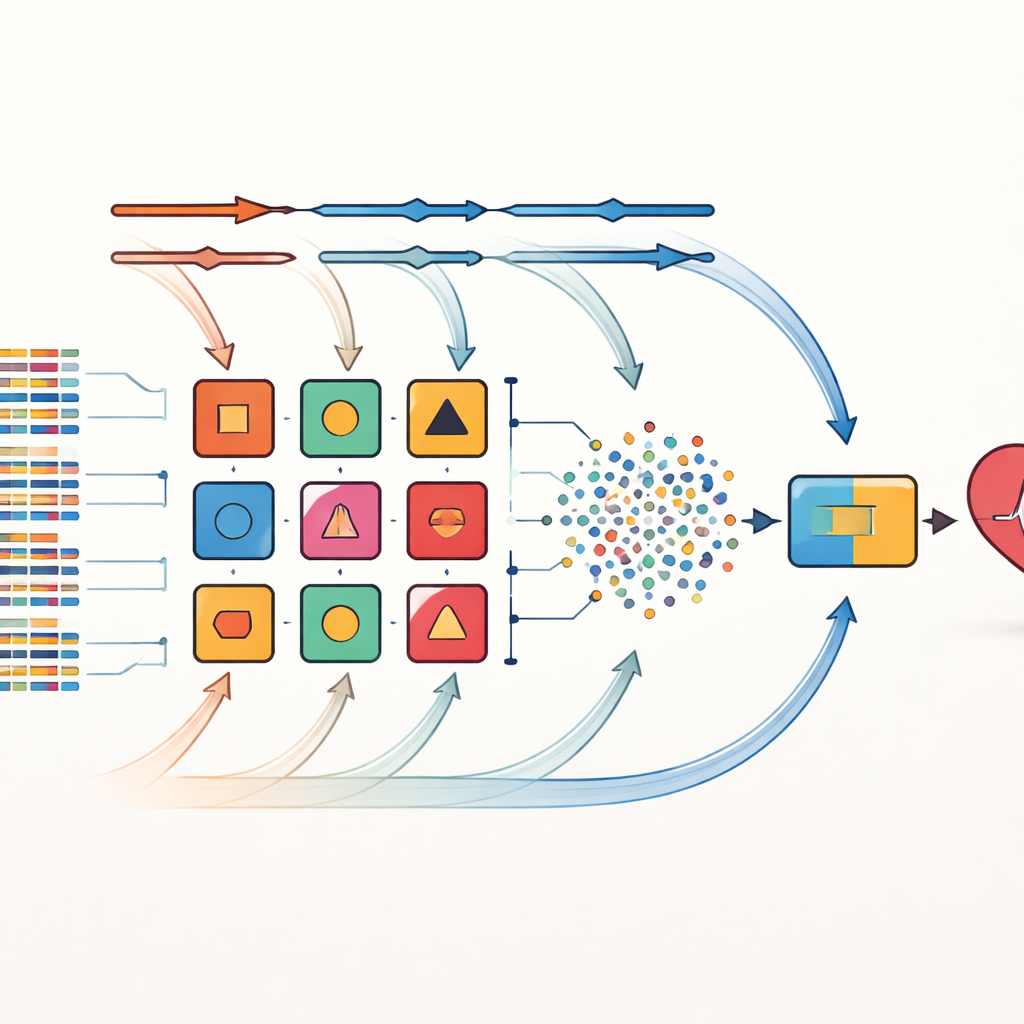
Testy na rzeczywistych zbiorach danych dotyczących serca
Metodę oceniono na trzech znanych zbiorach danych dotyczących układu sercowo-naczyniowego: niewielkim, zrównoważonym zbiorze szpitalnym z Cleveland, większym i silnie niezrównoważonym badaniu społecznościowym z Framingham oraz bardzo dużym zbiorze 70 000 rekordów zawierającym zarówno dane numeryczne, jak i kategoryczne. Badacze starannie oczyszczali dane, uzupełniali brakujące wartości tam, gdzie było to stosowne, i radzili sobie z wartościami odstającymi. We wszystkich trzech zbiorach ich model zespołowy osiągnął wyższą trafność i lepszą zdolność rozróżniania pacjentów chorych i zdrowych niż którykolwiek z pojedynczych modeli oraz kilka niedawnych zaawansowanych metod. Na przykład dla danych z Cleveland osiągnął około 98 procent trafności z niemal doskonałą zdolnością oddzielenia osób z chorobą serca od tych bez niej, a także poprawił wyniki na zbiorach niezrównoważonych i dużych rozmiarów.
Otwarcie czarnej skrzynki predykcji
Aby system był bardziej akceptowalny w praktyce klinicznej, zespół zastosował SHAP, nowoczesną technikę interpretowalności, aby zmierzyć, jak bardzo każdy czynnik wejściowy przyczynia się do predykcji. Zamiast jedynie stwierdzać, że pacjent ma wysokie ryzyko, model może wskazać, że głównymi czynnikami tego wniosku były zachowania związane z paleniem, poziomy lipidów lub glukozy we krwi. Co ciekawe, najbardziej wpływowe cechy zidentyfikowane przez model pokrywają się z obowiązującymi wytycznymi zapobiegania w Chinach, które wskazują palenie, nieprawidłowe tłuszcze we krwi i cukrzycę jako kluczowe modyfikowalne czynniki napędzające choroby sercowo-naczyniowe. Czynniki takie jak wiek i ciśnienie krwi nadal mają znaczenie, ale w tych zbiorach danych miały nieco mniejszy wkład w ostateczną decyzję niż wskaźniki związane ze stylem życia i metabolizmem.
Co to oznacza dla codziennego zdrowia
Dla osób spoza specjalności główny wniosek jest taki, że inteligentniejsze, bardziej elastyczne modele komputerowe mogą poprawić zdolność lekarzy do przewidywania problemów sercowych, zanim spowodują one nieodwracalne uszkodzenia. Poprzez łączenie wielu mniejszych modeli i ciągłe równoważenie ich wpływu, proponowane podejście lepiej radzi sobie z hałaśliwymi, niezrównoważonymi i zmieniającymi się danymi medycznymi. Równocześnie wykorzystanie narzędzi do interpretowalności pomaga skupić się na znanych czynnikach ryzyka — zwłaszcza paleniu, cholesterolu i cukrze we krwi — które pacjenci i klinicyści mogą realnie zmieniać. Chociaż potrzebne są dalsze testy w rzeczywistych warunkach klinicznych i na bogatszych typach danych, praca ta wskazuje kierunek w stronę systemów predykcyjnych, które są jednocześnie dokładniejsze i bardziej przejrzyste w wspieraniu zapobiegania chorobom sercowo-naczyniowym.
Cytowanie: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
Słowa kluczowe: prognozowanie chorób sercowo-naczyniowych, uczenie zespołowe, uczenie maszynowe w medycynie, czynniki ryzyka, interpretowalność modelu