Clear Sky Science · de
Eine Methode zur Vorhersage von Herz-Kreislauf-Erkrankungen basierend auf einer Kreuz-Kombinations-Strategie und dynamischem gewichteten Stacking-Ensemble
Warum die Vorhersage des Herzrisikos wichtig ist
Herz- und Gefäßerkrankungen bleiben weltweit die häufigste Todesursache und treten oft ohne deutliche Vorwarnung auf. Ärztinnen und Ärzte kennen viele Risikofaktoren — etwa Rauchen, hohe Cholesterinwerte und hoher Blutzucker — doch diese Hinweise für jede einzelne Person zusammenzuführen ist schwierig, insbesondere wenn die Daten unvollständig sind oder aus verschiedenen Krankenhäusern und Populationen stammen. Diese Studie stellt eine neue computerbasierte Methode vor, die viele Vorhersagemodelle kombiniert und automatisch lernt, wie viel Vertrauen jedem Modell geschenkt werden sollte. Ziel ist es, das Risiko für Herz-Kreislauf-Erkrankungen genauer und früher zu erkennen als mit aktuellen Werkzeugen.
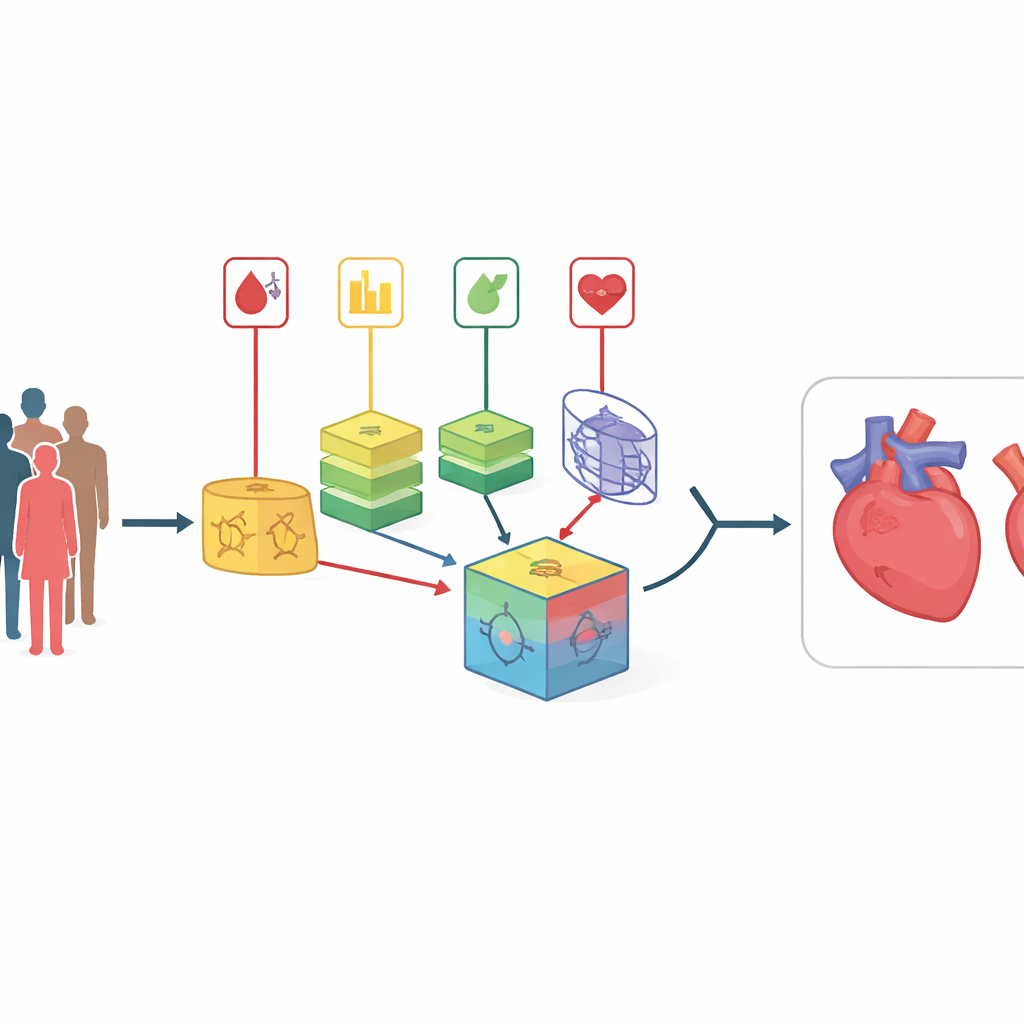
Über einfache Risikoscores hinausblicken
Traditionelle Herzrisiko-Rechner, wie bekannte klinische Scores, setzen meist auf relativ einfache, lineare Beziehungen zwischen Messwerten und Erkrankung. In Wirklichkeit verhält sich der Körper eher wie ein verwobenes Netz, in dem Faktoren wie Cholesterin, Blutdruck und Glukose auf komplexe Weise miteinander interagieren. Moderne Ansätze des maschinellen Lernens können solche Muster aufdecken, aber Einzelmodelle verhalten sich oft wie undurchsichtige „Black Boxes“ und können bei neuen Patientengruppen versagen. Bestehende Ansätze mit kombinierten Modellen beruhen häufig auf festen Gewichtungen, die einmal bestimmt und dann nicht mehr angepasst werden — das erschwert die Anpassung, wenn sich Patientengruppen oder die Datenqualität im Laufe der Zeit verändern.
Viele Blickwinkel auf denselben Patienten mischen
Die Autoren begegnen diesen Einschränkungen mit einer Strategie, die sie Kreuz-Kombination nennen. Statt auf eine einzige Methode zur Auswahl wichtiger Merkmale zu setzen, wenden sie acht verschiedene Feature-Selection-Verfahren auf dieselben Datensätze an. Diese Methoden umfassen einfache statistische Filter, Verfahren, die wiederholt testen, welche Variablen am wichtigsten sind, sowie Techniken, die eng an bestimmte Lernalgorithmen gebunden sind. Jede ausgewählte Merkmalsmenge wird anschließend mit einem von 14 unterschiedlichen Klassifikatoren kombiniert, von einfachen wahrscheinlichkeitstheoretischen Modellen über Entscheidungsbäume bis hin zu neuronalen Netzen. Insgesamt entstehen 112 Kandidatenmodelle, die jeweils eine leicht unterschiedliche „Sicht“ auf die Zusammenhänge zwischen Patientenmerkmalen und Herzkrankheiten bieten.
Modellgewichte im Zeitverlauf entwickeln lassen
Aus diesem großen Pool werden die zehn leistungsfähigsten Modelle ausgewählt, um ein Ensemble zu bilden. Die zentrale Neuerung ist hier ein dynamisches, gewichtetet Stacking-Framework. Anfangs erhält jedes Basismodell denselben Einfluss. Während des Trainings prüft das System wiederholt, wie gut jedes Modell in verschiedenen Datenfaltungen abschneidet, und passt die Gewichte anhand der Fehler an — besser performende Modelle gewinnen an Einfluss, schwächere werden schrittweise herabgewichtet. Die Ausgaben dieser feinabgestimmten Basismodelle werden zu neuen Signalen kombiniert, die an einen finalen Entscheider auf Basis des k-nächsten-Nachbarn-Ansatzes übergeben werden. Dieser zeichnet sich dadurch aus, lokale Muster zu erkennen, ohne eine bestimmte Form der Datenverteilung anzunehmen. Dieser adaptive Prozess erlaubt es dem Ensemble, sich an Verschiebungen in der Datenverteilung anzupassen, etwa wenn ein neues Krankenhaus ergänzt wird oder sich die Patientenmischung ändert.
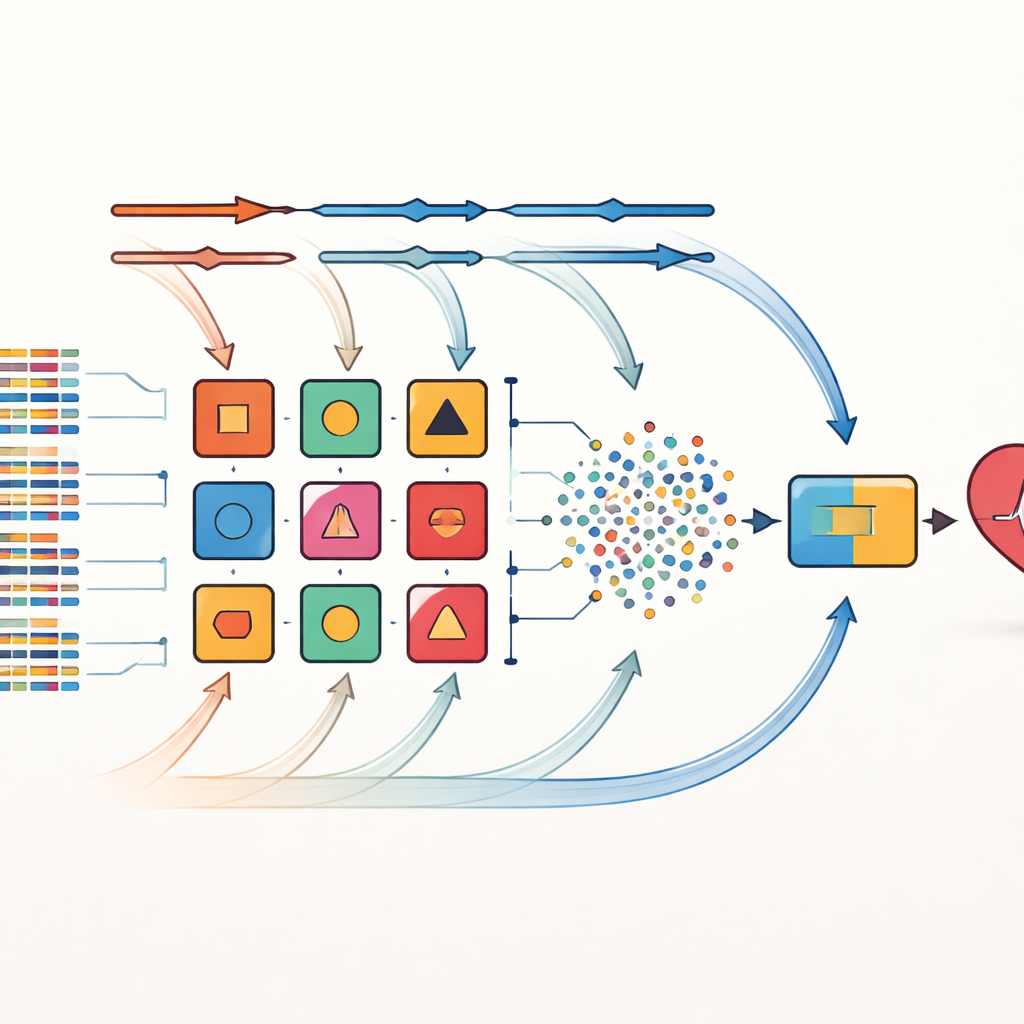
Test auf realen Herz-Datensätzen
Die Methode wurde an drei bekannten kardiovaskulären Datensätzen evaluiert: einem kleinen, ausgeglichenen Krankenhaussatz aus Cleveland, einer größeren und stark unausgeglichenen Gemeinschaftsstudie aus Framingham sowie einem sehr großen Datensatz mit 70.000 Datensätzen, der numerische und kategoriale Informationen enthält. Die Forschenden bereinigten die Daten sorgfältig, imputierten fehlende Werte, wo es sinnvoll war, und gingen mit Ausreißern um. Über alle drei Datensätze hinweg erreichte ihr kombiniertes Modell eine höhere Genauigkeit und eine bessere Trennschärfe zwischen kranken und gesunden Patienten als jedes der Einzelmodelle und mehrere jüngere fortgeschrittene Methoden. Beispielsweise erzielte es auf den Cleveland-Daten etwa 98 Prozent Genauigkeit mit einer nahezu perfekten Fähigkeit, Personen mit und ohne Herzkrankheit zu trennen, und verbesserte zugleich die Leistung bei den unausgeglichenen und großskaligen Datensätzen.
Die Black Box der Vorhersagen öffnen
Um das System für den klinischen Einsatz akzeptabler zu machen, nutzte das Team SHAP, eine moderne Interpretierbarkeitsmethode, um zu messen, wie stark jeder Eingabefaktor zu einer Vorhersage beiträgt. Anstatt nur mitzuteilen, dass ein Patient ein hohes Risiko hat, kann das Modell angeben, dass etwa Rauchen, Lipidwerte oder Blutzucker die Haupttreiber dieser Einschätzung waren. Interessanterweise stimmen die vom Modell identifizierten einflussreichsten Merkmale mit aktuellen Präventionsleitlinien in China überein, die Rauchen, abnorme Blutfettwerte und Diabetes als zentrale veränderbare Treiber für Herz-Kreislauf-Erkrankungen hervorheben. Faktoren wie Alter und Blutdruck sind weiterhin wichtig, trugen in diesen Datensätzen jedoch etwas weniger zur finalen Entscheidung bei als Lebensstil- und Stoffwechselmarker.
Was das für die tägliche Gesundheit bedeutet
Für Nicht-Fachleute ist die wichtigste Erkenntnis, dass intelligentere, flexiblere Computermodelle Ärzten helfen können, Herzprobleme früher zu erkennen, bevor sie irreversible Schäden verursachen. Durch die Kombination vieler kleinerer Modelle und das ständige Ausbalancieren ihres Einflusses bewältigt der vorgeschlagene Ansatz Rauschen, Datenungleichgewicht und veränderliche medizinische Daten besser. Gleichzeitig sorgt der Einsatz von Interpretierbarkeitswerkzeugen dafür, dass der Fokus auf vertrauten Risikofaktoren — insbesondere Rauchen, Cholesterin und Blutzucker — erhalten bleibt, die Patientinnen, Patienten und Kliniker tatsächlich beeinflussen können. Obwohl weitergehende Tests in realen klinischen Umgebungen und mit reichhaltigeren Datentypen noch nötig sind, weist diese Arbeit in Richtung Vorhersagesysteme, die sowohl genauer als auch transparenter in der Anleitung der kardiovaskulären Prävention sind.
Zitation: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
Schlüsselwörter: Vorhersage von Herz-Kreislauf-Erkrankungen, Ensemble-Lernen, Maschinelles Lernen in der Medizin, Risikofaktoren, Modellinterpretierbarkeit