Clear Sky Science · en
A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble
Why Heart Risk Prediction Matters
Heart and blood vessel diseases remain the top killers worldwide, often striking without clear warning. Doctors know many risk factors—such as smoking, high cholesterol, and high blood sugar—but weaving these clues together for each individual is challenging, especially when data are messy or come from different hospitals and populations. This study presents a new computer-based method that combines many prediction models and automatically learns how much to trust each one, aiming to spot cardiovascular disease risk more accurately and earlier than current tools.
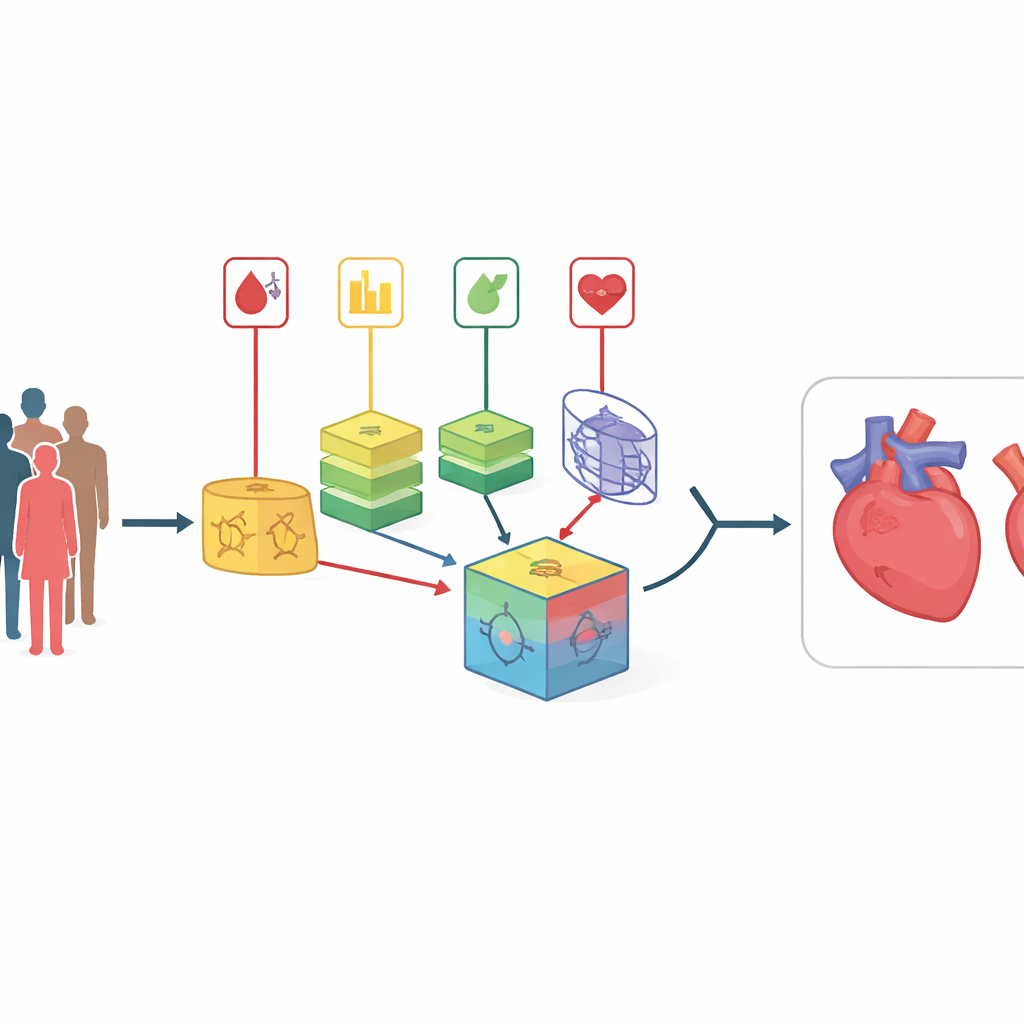
Looking Beyond Simple Risk Scores
Traditional heart risk calculators, like well-known clinical scores, assume fairly simple, straight-line relationships between measurements and disease. In reality, the body behaves more like a tangled web, where factors such as cholesterol, blood pressure, and glucose interact in complex ways. Recent machine-learning approaches can uncover such patterns, but single models tend to behave like opaque “black boxes” and may fail when applied to new groups of patients. Existing combined-model approaches often rely on fixed weightings determined once and never updated, which makes them slow to adapt when patient populations or data quality change over time.
Mixing Many Views of the Same Patient
The authors tackle these limitations with a strategy they call cross-combination. Instead of betting on one way to choose important risk factors, they apply eight different feature-selection methods to the same datasets. These methods include simple statistical filters, procedures that repeatedly test which variables matter most, and techniques that are tightly linked to specific learning algorithms. Each selected feature set is then paired with one of 14 diverse classifiers, ranging from simple probability-based models to decision trees and neural networks. In total, 112 candidate prediction models are created, each offering a slightly different “view” of the relationships between patient characteristics and heart disease.
Letting Model Weights Evolve Over Time
From this large pool, the ten best-performing models are chosen to form an ensemble. Here the key innovation is a dynamic weighted stacking framework. Initially, each base model is given equal influence. During training, the system repeatedly tests how well each model does on different folds of the data and adjusts its weight in response to errors—models that perform better gain more influence, while weaker ones are gradually down-weighted. The outputs of these tuned base models are blended into a new set of signals that feed a final decision-maker based on the k-nearest neighbors approach, which excels at recognizing local patterns without assuming a specific data shape. This adaptive process allows the ensemble to adjust to shifts in data distribution, such as when a new hospital or patient mix is introduced.
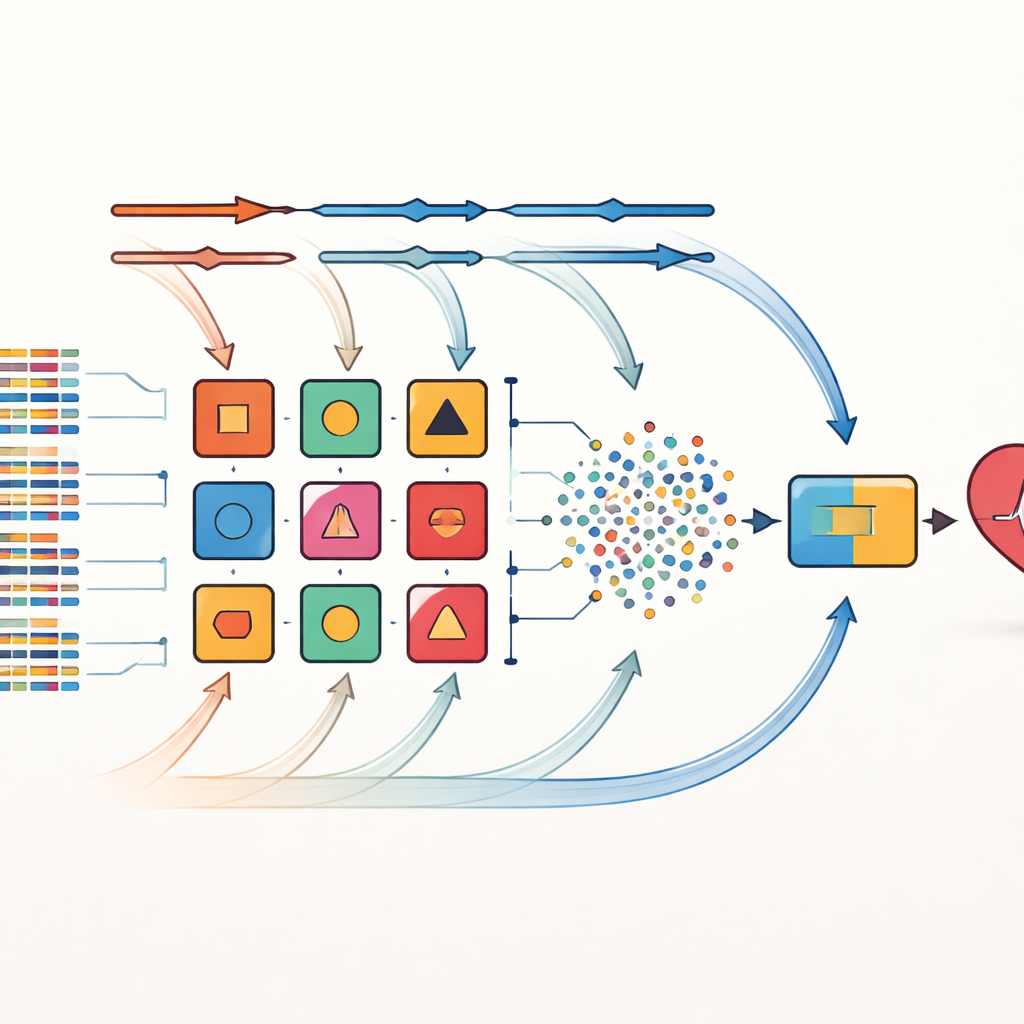
Testing on Real-World Heart Datasets
The method was evaluated on three well-known cardiovascular datasets: a small, balanced hospital set from Cleveland, a larger and highly imbalanced community study from Framingham, and a very large dataset of 70,000 records with both numerical and categorical information. The researchers carefully cleaned the data, filled in missing values where appropriate, and dealt with outliers. Across all three datasets, their combined model achieved higher accuracy and better discrimination between diseased and healthy patients than any of the individual models and several recent advanced methods. For example, on the Cleveland data it reached about 98 percent accuracy with an almost perfect ability to separate those with and without heart disease, and it also improved performance on the imbalanced and large-scale datasets.
Opening the Black Box of Predictions
To make the system more acceptable in clinical practice, the team used SHAP, a modern interpretability technique, to measure how much each input factor contributes to a prediction. Instead of only reporting that a patient is at high risk, the model can indicate that smoking behavior, lipid levels, or blood glucose were major drivers of that conclusion. Interestingly, the most influential features identified by the model match current prevention guidelines in China, which single out smoking, abnormal blood fats, and diabetes as key modifiable drivers of cardiovascular disease. Factors like age and blood pressure still matter, but within these datasets they contributed somewhat less to the final decision than lifestyle and metabolic markers.
What This Means for Everyday Health
For non-specialists, the main takeaway is that smarter, more flexible computer models can sharpen doctors’ ability to foresee heart problems before they cause irreversible damage. By combining many smaller models and constantly rebalancing their influence, the proposed approach copes better with noisy, imbalanced, and changing medical data. At the same time, its use of interpretability tools helps keep the focus on familiar risk factors—especially smoking, cholesterol, and blood sugar—that patients and clinicians can actually change. Although further testing in real clinical settings and on richer types of data is still needed, this work points toward prediction systems that are both more accurate and more transparent in guiding cardiovascular prevention.
Citation: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
Keywords: cardiovascular disease prediction, ensemble learning, machine learning in medicine, risk factors, model interpretability