Clear Sky Science · ja
交差組み合わせ戦略と動的重み付きスタッキングアンサンブルに基づく心血管疾患予測法
心臓リスク予測が重要な理由
心血管系の病気は依然として世界の主要な死因であり、多くの場合明確な前触れなしに発症します。喫煙、高コレステロール、高血糖など多くのリスク因子は知られていますが、これらの手がかりを各個人について総合して評価するのは難しく、特にデータが雑然としていたり異なる病院や集団から集められた場合はなおさらです。本研究は、多数の予測モデルを組み合わせ、それぞれのモデルをどれだけ信頼するかを自動的に学習する新しい計算手法を提示し、既存の手法よりも正確かつ早期に心血管疾患リスクを検出することを目指しています。
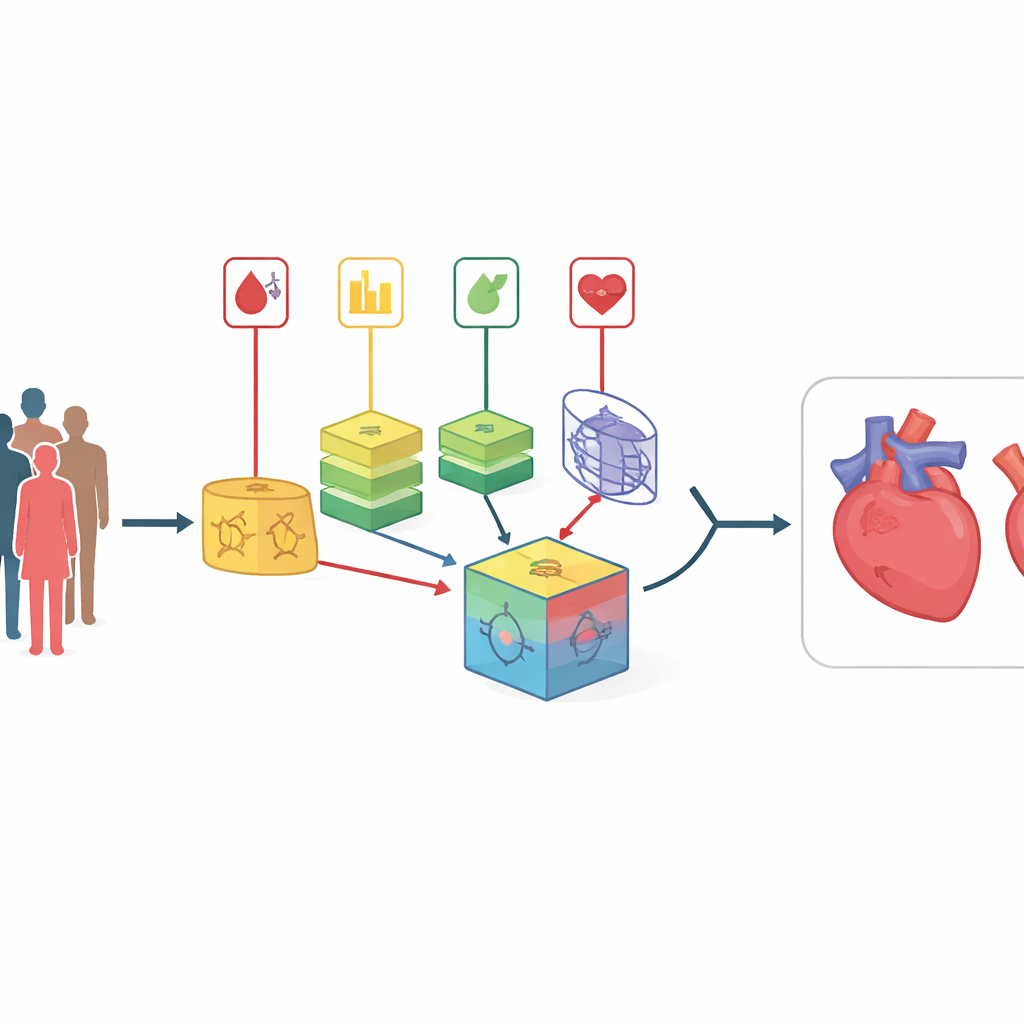
単純なリスクスコアを超えて見る
よく知られた臨床スコアのような従来の心リスク計算法は、測定値と疾患の間に比較的単純で直線的な関係があると仮定します。しかし実際には、体はコレステロール、血圧、血糖などの因子が複雑に相互作用する絡み合った網のように振る舞います。最近の機械学習アプローチはそのようなパターンを明らかにできますが、単一モデルは不透明な「ブラックボックス」のようになりがちで、新しい患者集団に適用したときに性能が低下することがあります。既存のモデル結合手法はしばしば一度決められた固定重みを用いるため、患者集団やデータ品質が時間とともに変化した際に適応が遅れます。
同じ患者を多面的に見る
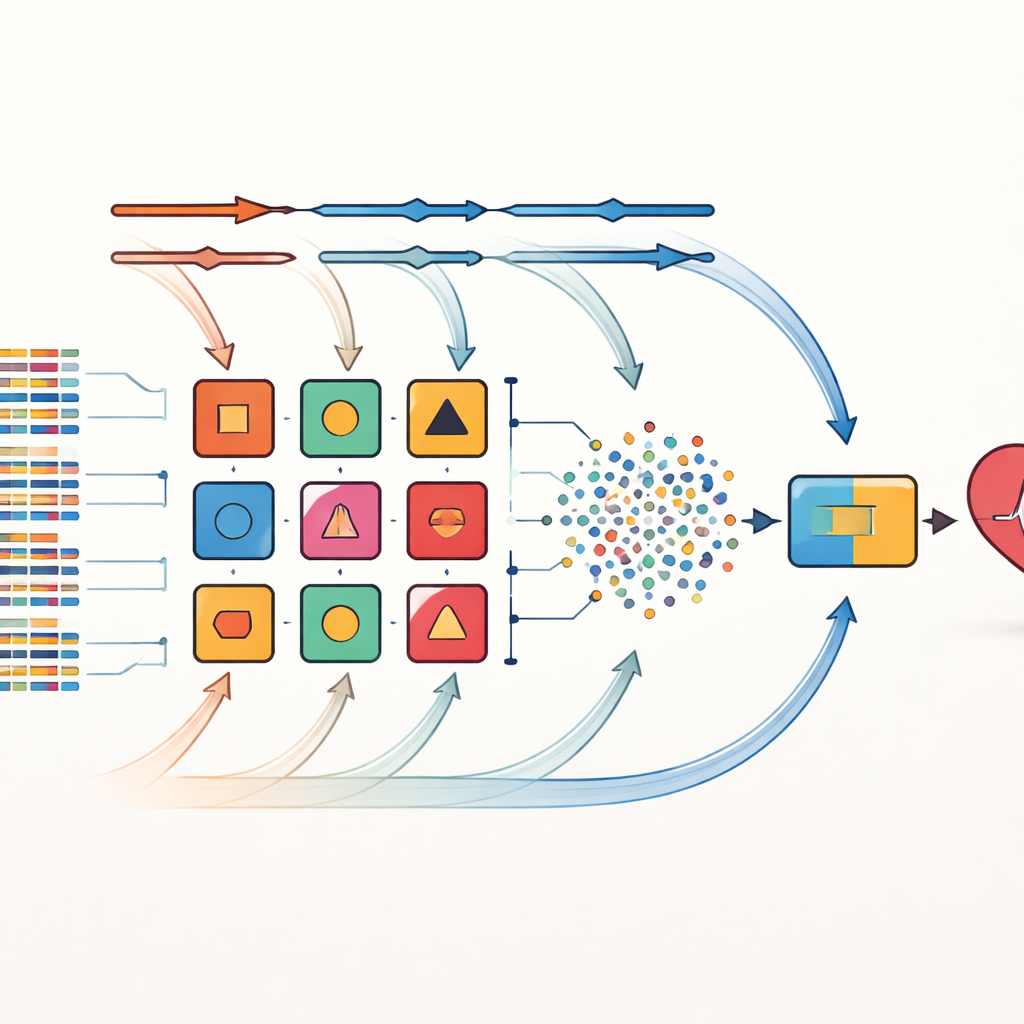
著者らはこれらの限界に対し「交差組み合わせ(cross-combination)」と呼ぶ戦略で対処します。重要な特徴量を選ぶ一つの方法に賭ける代わりに、同じデータセットに対して8つの異なる特徴選択法を適用します。これらの方法には単純な統計フィルタ、どの変数が重要かを繰り返し検証する手続き、特定の学習アルゴリズムと強く結びつく技術が含まれます。各選択された特徴集合は14種類の多様な分類器のいずれかと組み合わされます。これらは確率ベースの単純モデルから決定木やニューラルネットワークまで幅広く、合計で112の候補予測モデルが作られ、それぞれが患者特性と心疾患の関係に関するやや異なる「視点」を提供します。
モデルの重みを時間とともに変化させる
この大きなプールから、性能の良い上位10モデルが選ばれてアンサンブルを構成します。ここでの主要な革新は動的重み付きスタッキングの枠組みです。初期状態では各ベースモデルに等しい影響力が与えられます。学習中、システムはデータの異なるフォールド上で各モデルの性能を繰り返し評価し、誤りに応じてその重みを調整します—性能の良いモデルはより大きな影響力を得て、弱いモデルは徐々に重みを下げられます。こうして調整されたベースモデルの出力は新しい信号群に統合され、最終的な意思決定器にはk近傍法が用いられます。k近傍法は特定のデータ形状を仮定せず局所的なパターンを認識するのに優れており、この適応的プロセスにより新しい病院や異なる患者構成が導入された場合などのデータ分布の変化に対応できます。
実世界の心疾患データでの検証
手法は3つのよく知られた心血管データセットで評価されました:小規模でバランスの取れたクリーブランドの病院データ、より大規模で極めて不均衡なフラミンガムの地域調査データ、そして数値とカテゴリ情報を含む7万件の非常に大規模なデータセットです。研究者らはデータを慎重にクリーニングし、欠損値を適宜補完し、外れ値に対処しました。これら3つのデータセット全体で、提案する結合モデルは個々のモデルやいくつかの最近の先進手法に比べて高い精度と優れた識別力を達成しました。例えばクリーブランドデータでは約98%の精度を達成し、心臓病の有無をほぼ完全に識別でき、また不均衡で大規模なデータセットでも性能を向上させました。
予測のブラックボックスを開く
臨床で受け入れられやすくするために、研究チームはSHAPという現代的な解釈手法を用いて各入力因子が予測にどれだけ寄与しているかを測定しました。患者が高リスクであると報告するだけでなく、その結論に喫煙行動、脂質レベル、血糖が大きく寄与したことを示すことができます。興味深いことに、モデルが同定した最も影響力の大きい特徴は、中国の現行予防ガイドラインと一致しており、喫煙、異常な血脂、糖尿病が心血管疾患の主要な可変的要因として特に重要とされています。年齢や血圧といった因子も依然重要ですが、これらのデータセットでは生活様式や代謝マーカーが最終的判断にやや大きく寄与していました。
日常的な健康管理への示唆
専門外の方への主なポイントは、より賢く柔軟な計算モデルが、不可逆的な損傷が起こる前に心臓の問題を予見する医師の能力を高めうるということです。多数の小さなモデルを組み合わせ、その影響力を継続的に再配分することで、本手法はノイズの多い、不均衡な、そして変化する医療データに対してより強く対応します。同時に解釈可能性ツールの利用により、患者や臨床医が実際に変えうる喫煙、コレステロール、血糖といった馴染みのあるリスク因子に焦点を当て続けられます。さらに臨床現場やより多様な種類のデータでの追加検証は必要ですが、本研究はより正確で透明性のある心血管予防を導く予測システムへの道を示しています。
引用: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
キーワード: 心血管疾患予測, アンサンブル学習, 医療における機械学習, 危険因子, モデルの解釈可能性