Clear Sky Science · pt
Um método de predição de doenças cardiovasculares baseado em estratégia de combinação cruzada e empilhamento ponderado dinâmico
Por que a predição do risco cardíaco é importante
As doenças do coração e dos vasos sanguíneos continuam sendo as principais causas de morte no mundo, muitas vezes atingindo sem aviso claro. Os médicos conhecem vários fatores de risco — como tabagismo, colesterol alto e glicose elevada —, mas combinar essas pistas para cada indivíduo é desafiador, principalmente quando os dados são confusos ou vêm de diferentes hospitais e populações. Este estudo apresenta um novo método computacional que combina diversos modelos de predição e aprende automaticamente quanto confiar em cada um, com o objetivo de identificar o risco de doença cardiovascular de forma mais precisa e precoce do que as ferramentas atuais.
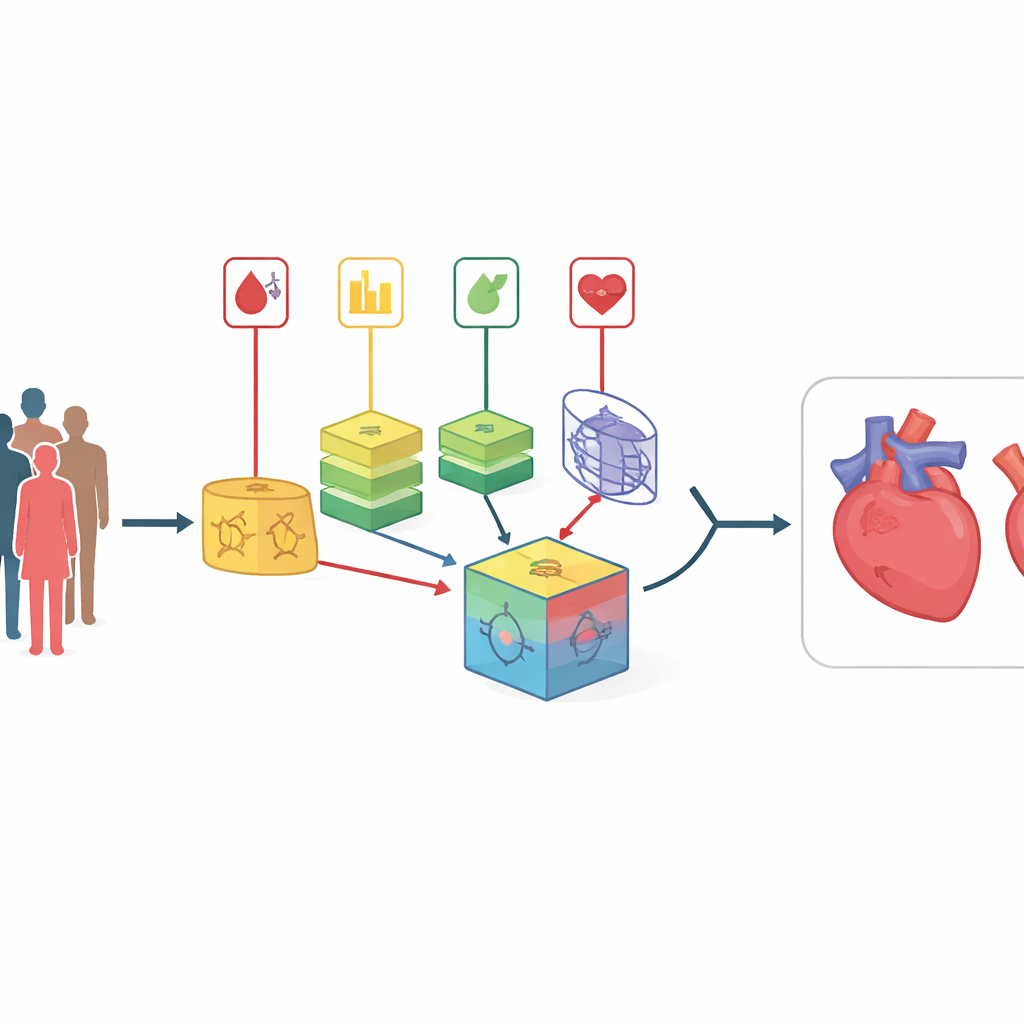
Indo além de escores de risco simples
Calculadoras tradicionais de risco cardíaco, como escores clínicos conhecidos, pressupõem relações bastante simples e lineares entre medidas e doença. Na realidade, o corpo se comporta mais como uma teia emaranhada, onde fatores como colesterol, pressão arterial e glicemia interagem de maneiras complexas. Abordagens recentes de aprendizado de máquina podem descobrir esses padrões, mas modelos únicos tendem a funcionar como “caixas-pretas” opacas e podem falhar quando aplicados a novos grupos de pacientes. Métodos existentes de modelos combinados frequentemente dependem de ponderações fixas determinadas uma vez e nunca atualizadas, o que os torna lentos para se adaptar quando as populações de pacientes ou a qualidade dos dados mudam ao longo do tempo.
Misturando muitas visões do mesmo paciente
Os autores enfrentam essas limitações com uma estratégia chamada combinação cruzada. Em vez de apostar em uma única forma de selecionar fatores de risco importantes, eles aplicam oito métodos diferentes de seleção de variáveis aos mesmos conjuntos de dados. Esses métodos incluem filtros estatísticos simples, procedimentos que testam repetidamente quais variáveis mais importam e técnicas fortemente vinculadas a algoritmos de aprendizado específicos. Cada conjunto de características selecionado é então pareado com um dos 14 classificadores diversos, que vão de modelos probabilísticos simples a árvores de decisão e redes neurais. Ao todo, são criados 112 modelos candidatos de predição, cada um oferecendo uma “visão” levemente diferente das relações entre as características do paciente e a doença cardíaca.
Deixando os pesos dos modelos evoluírem com o tempo
Desse grande conjunto, os dez modelos com melhor desempenho são escolhidos para formar um ensemble. Aqui a inovação chave é uma estrutura de empilhamento ponderado dinâmico. Inicialmente, cada modelo base recebe influência igual. Durante o treinamento, o sistema testa repetidamente o desempenho de cada modelo em diferentes partições dos dados e ajusta seu peso em resposta aos erros — modelos que se saem melhor ganham mais influência, enquanto os mais fracos são gradualmente desvalorizados. As saídas desses modelos base ajustados são combinadas em um novo conjunto de sinais que alimentam um decisor final baseado na abordagem dos k-vizinhos mais próximos, que se destaca em reconhecer padrões locais sem presumir uma forma específica dos dados. Esse processo adaptativo permite que o ensemble se ajuste a mudanças na distribuição dos dados, como quando um novo hospital ou mistura de pacientes é introduzida.
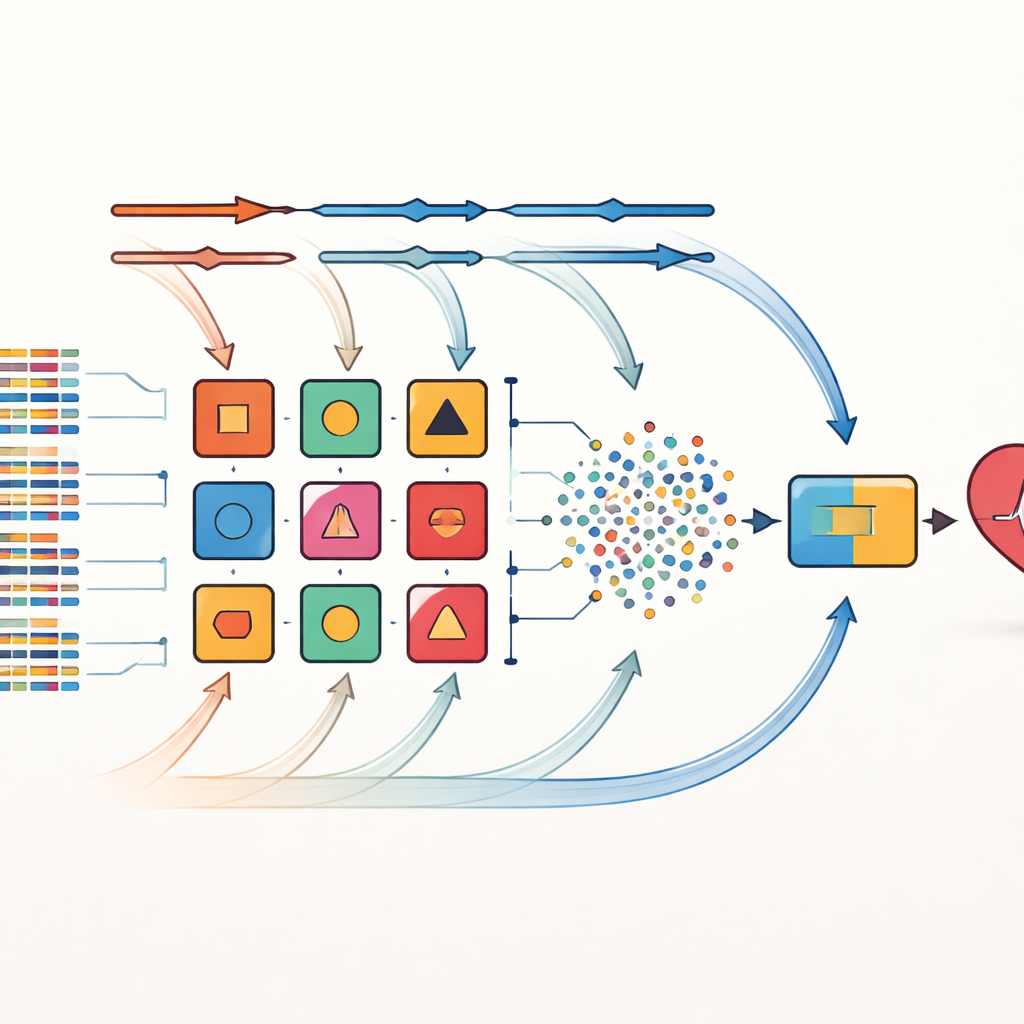
Testando em conjuntos de dados reais sobre coração
O método foi avaliado em três conjuntos de dados cardiovasculares bem conhecidos: um conjunto hospitalar pequeno e balanceado de Cleveland, um estudo comunitário maior e altamente desbalanceado de Framingham, e um conjunto muito grande com 70.000 registros contendo informações numéricas e categóricas. Os pesquisadores limparam cuidadosamente os dados, preencheram valores ausentes quando apropriado e trataram outliers. Em todos os três conjuntos, seu modelo combinado alcançou maior acurácia e melhor discriminação entre pacientes doentes e saudáveis do que qualquer um dos modelos individuais e várias abordagens avançadas recentes. Por exemplo, nos dados de Cleveland atingiu cerca de 98% de acurácia com capacidade quase perfeita de separar aqueles com e sem doença cardíaca, e também melhorou o desempenho nos conjuntos desbalanceados e em grande escala.
Abrindo a caixa preta das predições
Para tornar o sistema mais aceitável na prática clínica, a equipe usou SHAP, uma técnica moderna de interpretabilidade, para medir quanto cada fator de entrada contribui para uma predição. Em vez de apenas reportar que um paciente tem alto risco, o modelo pode indicar que o tabagismo, os níveis de lipídios ou a glicemia foram os principais motores dessa conclusão. Curiosamente, as características mais influentes identificadas pelo modelo coincidem com as diretrizes de prevenção vigentes na China, que destacam tabagismo, alterações nos lipídios e diabetes como principais fatores modificáveis de risco cardiovascular. Fatores como idade e pressão arterial ainda importam, mas, nesses conjuntos de dados, contribuíram um pouco menos para a decisão final do que marcadores de estilo de vida e metabólicos.
O que isso significa para a saúde do dia a dia
Para não especialistas, a principal conclusão é que modelos computacionais mais inteligentes e flexíveis podem aguçar a capacidade dos médicos de prever problemas cardíacos antes que causem danos irreversíveis. Ao combinar muitos modelos menores e reequilibrar constantemente sua influência, a abordagem proposta lida melhor com dados médicos ruidosos, desbalanceados e em mudança. Ao mesmo tempo, o uso de ferramentas de interpretabilidade ajuda a manter o foco em fatores de risco familiares — especialmente tabagismo, colesterol e glicemia — que pacientes e clínicos podem, de fato, modificar. Embora sejam necessários mais testes em cenários clínicos reais e com tipos de dados mais ricos, este trabalho aponta para sistemas de predição que são tanto mais precisos quanto mais transparentes no direcionamento da prevenção cardiovascular.
Citação: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
Palavras-chave: predição de doenças cardiovasculares, aprendizado em conjunto, aprendizado de máquina na medicina, fatores de risco, interpretabilidade do modelo