Clear Sky Science · ru
Метод прогнозирования сердечно-сосудистых заболеваний на основе стратегии перекрёстной комбинации и динамического взвешенного стекинга
Почему важно прогнозирование риска для сердца
Заболевания сердца и сосудов остаются главной причиной смертности в мире и часто развиваются без явных предупреждений. Врачи хорошо знают многие факторы риска — такие как курение, высокий уровень холестерина и повышенный сахар в крови — но объединить эти подсказки для каждого пациента сложно, особенно когда данные шумные или поступают из разных больниц и популяций. В этом исследовании предлагается новый компьютерный метод, который комбинирует множество моделей прогнозирования и автоматически обучается определять степень доверия к каждой из них, стремясь обнаруживать риск сердечно‑сосудистых заболеваний точнее и раньше, чем существующие инструменты.
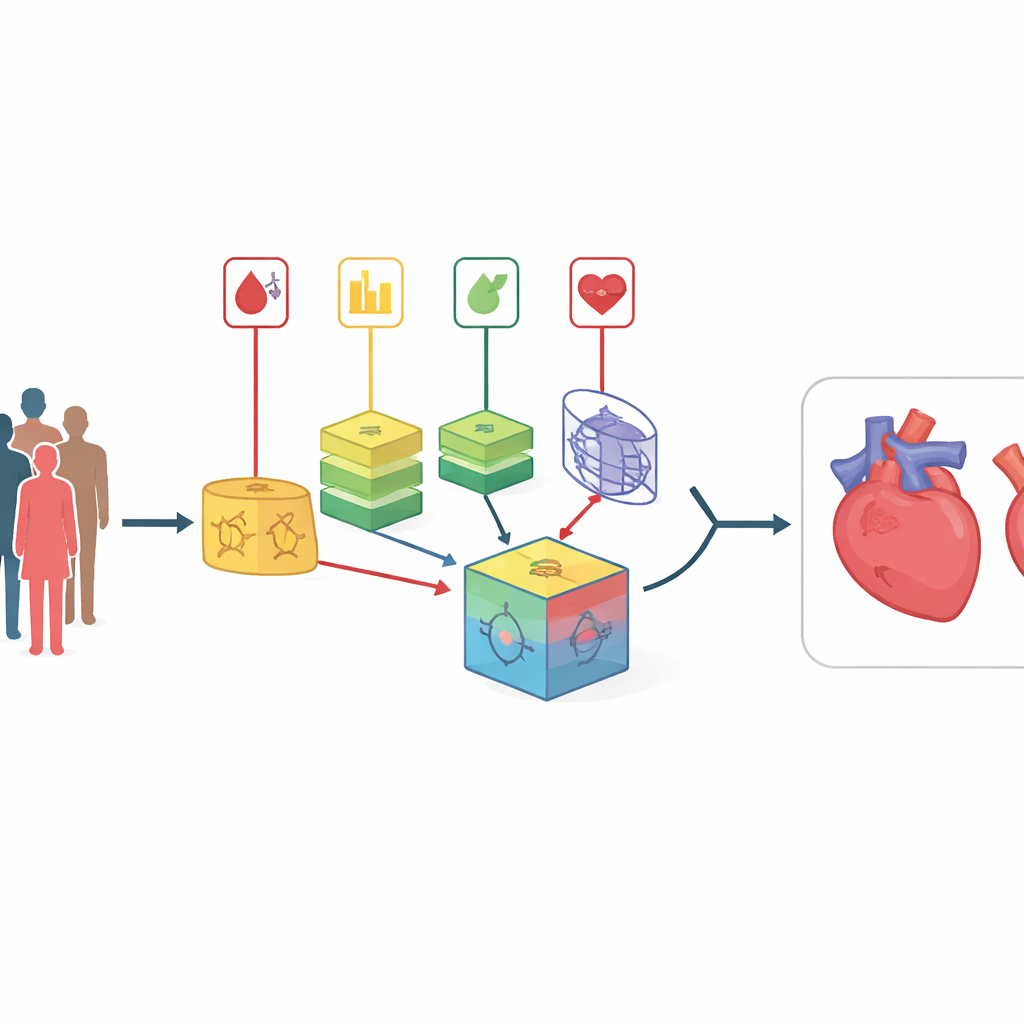
Выход за пределы простых рейтингов риска
Традиционные калькуляторы сердечного риска, такие как известные клинические шкалы, предполагают довольно простые, линейные связи между измерениями и заболеванием. На самом деле организм ведёт себя скорее как запутанная сеть, где такие факторы, как холестерин, артериальное давление и глюкоза, взаимодействуют сложным образом. Современные методы машинного обучения способны выявлять такие закономерности, но отдельные модели часто выступают как непрозрачные «чёрные ящики» и могут плохо работать на новых группах пациентов. Существующие подходы с комбинированием моделей часто опираются на фиксированные веса, установленные один раз и не обновляемые, что делает их медленно адаптирующимися при изменении популяции пациентов или качества данных во времени.
Смешивание множества взглядов на одного и того же пациента
Авторы решают эти ограничения с помощью стратегии, которую они называют перекрёстной комбинацией. Вместо того чтобы полагаться на один способ выбора важных признаков, они применяют восемь различных методов отбора признаков к одним и тем же наборам данных. Эти методы включают простые статистические фильтры, процедуры, многократно тестирующие значимость переменных, и техники, тесно связанные с конкретными алгоритмами обучения. Каждая выбранная совокупность признаков затем сочетается с одним из 14 разнообразных классификаторов — от простых вероятностных моделей до деревьев решений и нейронных сетей. В итоге создаётся 112 кандидатных моделей прогнозирования, каждая из которых предлагает слегка отличающийся «взгляд» на отношения между характеристиками пациента и сердечным заболеванием.
Позволяя весам моделей эволюционировать во времени
Из этой большой группы выбираются десять моделей с наилучшими показателями для формирования ансамбля. Ключевое нововведение здесь — динамический взвешенный стекинг. Изначально каждой базовой модели придаётся равное влияние. В процессе обучения система многократно оценивает, насколько хорошо каждая модель работает на разных фолдах данных, и корректирует её вес в ответ на ошибки — модели с лучшей производительностью получают больше влияния, а слабые постепенно взвешиваются меньше. Выходы этих настроенных базовых моделей объединяются в новый набор сигналов, который подаётся на итоговый решатель, основанный на методе k-ближайших соседей, хорошо распознающем локальные закономерности без предположений о форме данных. Этот адаптивный процесс позволяет ансамблю подстраиваться под сдвиги в распределении данных, например при подключении новой больницы или изменении состава пациентов.
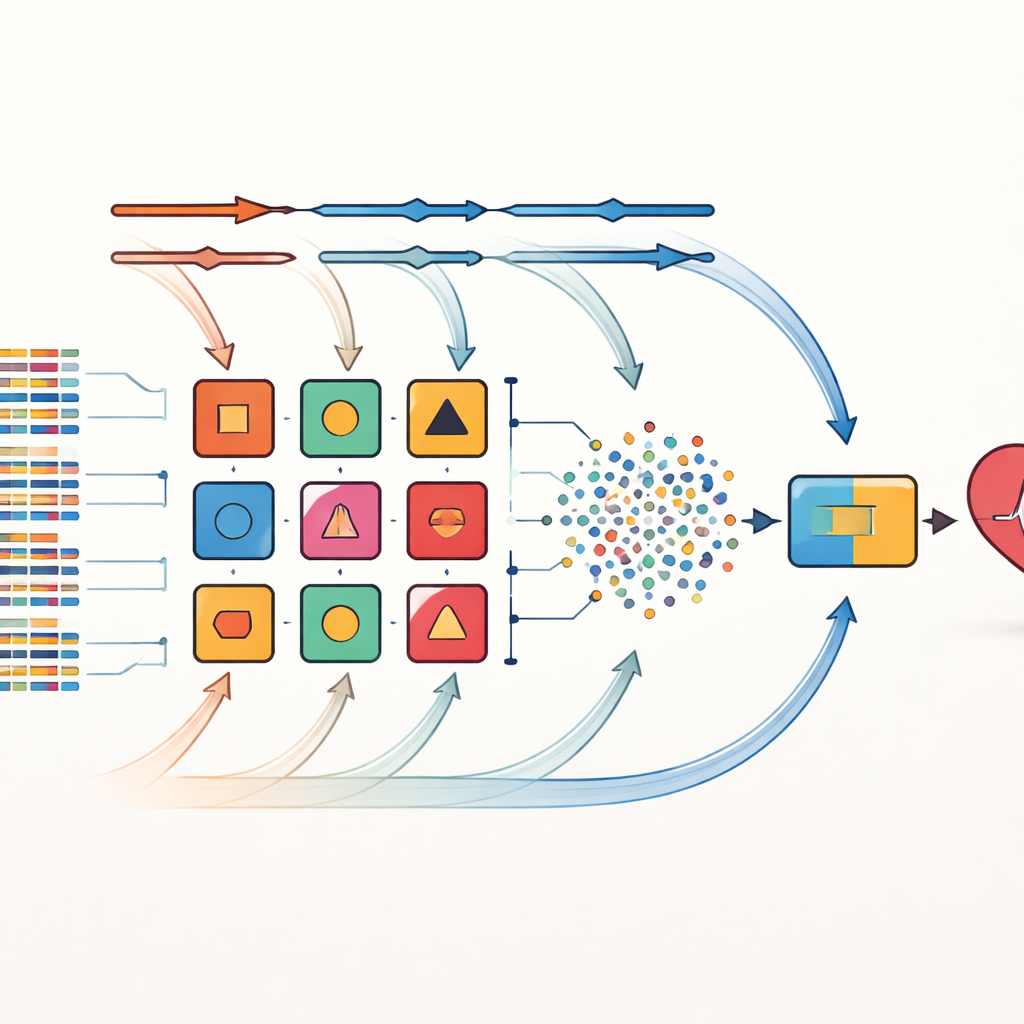
Тестирование на реальных сердечных наборах данных
Метод оценивали на трёх известных наборах данных по сердечно‑сосудистым заболеваниям: небольшом сбалансированном больничном наборе из Кливленда, более крупном и сильно несбалансированном популяционном исследовании Фрамингема и очень большом наборе из 70 000 записей с числовыми и категориальными признаками. Исследователи аккуратно очистили данные, при необходимости заполнили пропущенные значения и обработали выбросы. Во всех трёх наборах их комбинированная модель показала более высокую точность и лучшее различение больных и здоровых по сравнению с любой из отдельных моделей и несколькими современными методами. Например, на данных Кливленда она достигла примерно 98-процентной точности с почти идеальной способностью отделять пациентов с заболеванием и без него, а также улучшила результаты на несбалансированных и масштабных наборах.
Открывая «чёрный ящик» прогнозов
Чтобы сделать систему более приемлемой в клинической практике, команда использовала SHAP — современную методику интерпретируемости — чтобы оценить вклад каждого входного фактора в прогноз. Вместо простого сообщения о высоком риске пациенту, модель может указать, что ключевыми драйверами этого вывода были курение, липидный профиль или уровень глюкозы в крови. Примечательно, что наиболее влиятельные признаки, выявленные моделью, соответствуют действующим руководствам по профилактике в Китае, которые выделяют курение, нарушения липидного обмена и диабет как ключевые модифицируемые факторы риска сердечно‑сосудистых заболеваний. Такие факторы, как возраст и артериальное давление, по‑прежнему важны, но в рамках этих наборов данных они внесли несколько меньший вклад в итоговое решение по сравнению с показателями образа жизни и метаболическими маркерами.
Что это значит для повседневного здоровья
Для неспециалистов основной вывод таков: более умные и гибкие компьютерные модели могут повысить способность врачей предвидеть сердечные проблемы до того, как они приведут к необратимому вреду. Комбинируя множество небольших моделей и постоянно перенастраивая их влияние, предложенный подход лучше справляется с шумными, несбалансированными и меняющимися медицинскими данными. В то же время использование инструментов интерпретируемости помогает сохранять акцент на знакомых факторах риска — особенно курении, холестерине и уровне сахара — которые пациенты и клиницисты действительно могут изменить. Хотя необходимы дальнейшие испытания в реальных клинических условиях и на более богатых типах данных, эта работа указывает путь к системам прогнозирования, которые одновременно точнее и прозрачнее в руководстве профилактикой сердечно‑сосудистых заболеваний.
Цитирование: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
Ключевые слова: прогнозирование сердечно-сосудистых заболеваний, ансамблевое обучение, машинное обучение в медицине, факторы риска, интерпретируемость модели