Clear Sky Science · fr
Méthode de prédiction des maladies cardiovasculaires basée sur une stratégie de combinaison croisée et un empilement dynamique pondéré
Pourquoi la prédiction du risque cardiaque est importante
Les maladies du cœur et des vaisseaux restent les premières causes de mortalité dans le monde, frappant souvent sans signes avant-coureurs évidents. Les médecins connaissent de nombreux facteurs de risque — comme le tabagisme, un taux de cholestérol élevé et une glycémie élevée — mais combiner ces indices pour chaque individu est difficile, surtout quand les données sont bruitées ou proviennent d’hôpitaux et de populations différents. Cette étude présente une nouvelle méthode informatique qui rassemble plusieurs modèles de prédiction et apprend automatiquement à quel point il faut faire confiance à chacun, visant à détecter le risque cardiovasculaire plus précisément et plus tôt que les outils actuels.
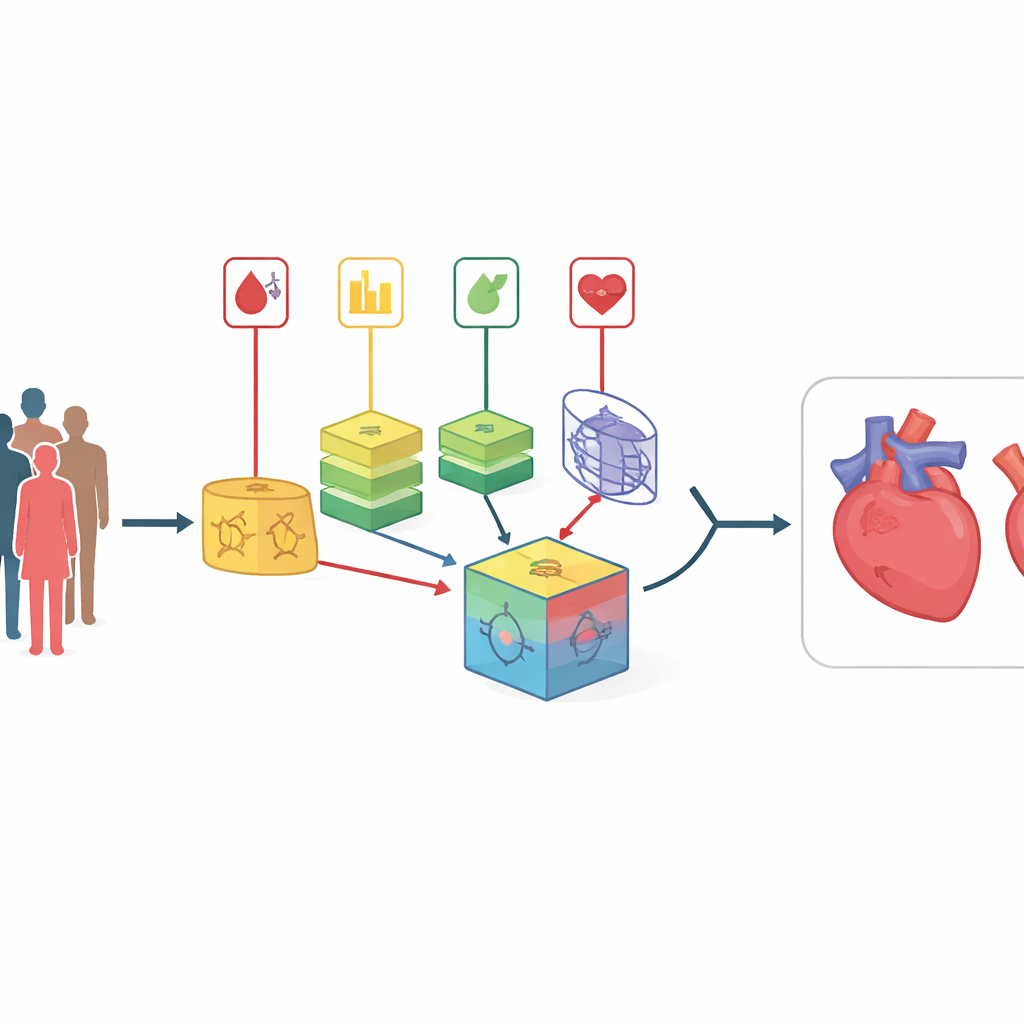
Au-delà des simples scores de risque
Les calculateurs de risque cardiaque traditionnels, comme certains scores cliniques bien connus, supposent des relations assez simples et linéaires entre les mesures et la maladie. En réalité, l’organisme se comporte plutôt comme un réseau complexe, où des facteurs tels que le cholestérol, la pression artérielle et la glycémie interagissent de manière non linéaire. Les approches récentes d’apprentissage automatique peuvent révéler de tels motifs, mais les modèles isolés ont tendance à se comporter comme des « boîtes noires » opaques et peuvent échouer lorsqu’ils sont appliqués à de nouvelles populations de patients. Les méthodes existantes d’assemblage de modèles reposent souvent sur des pondérations fixes déterminées une fois pour toutes, ce qui les rend lentes à s’adapter quand les populations de patients ou la qualité des données évoluent.
Mélanger plusieurs points de vue sur le même patient
Les auteurs traitent ces limites avec une stratégie qu’ils appellent combinaison croisée. Plutôt que de parier sur une seule manière de sélectionner les facteurs de risque importants, ils appliquent huit méthodes différentes de sélection de caractéristiques aux mêmes jeux de données. Ces méthodes incluent des filtres statistiques simples, des procédures qui testent de manière répétée quelles variables sont les plus importantes, et des techniques étroitement liées à des algorithmes d’apprentissage spécifiques. Chaque ensemble de caractéristiques sélectionnées est ensuite associé à l’un des 14 classificateurs divers, allant de modèles probabilistes simples à des arbres de décision et des réseaux de neurones. Au total, 112 modèles de prédiction candidats sont créés, chacun offrant une « vue » légèrement différente des relations entre les caractéristiques des patients et les maladies cardiaques.
Laisser évoluer les poids des modèles dans le temps
À partir de ce grand réservoir, les dix modèles les plus performants sont choisis pour former un ensemble. L’innovation clé ici est un cadre d’empilement dynamique pondéré. Initialement, chaque modèle de base reçoit la même influence. Pendant l’entraînement, le système évalue de façon répétée la performance de chaque modèle sur différentes partitions des données et ajuste son poids en réponse aux erreurs — les modèles qui performent mieux gagnent en influence, tandis que les plus faibles sont progressivement sous-pondérés. Les sorties de ces modèles de base ajustés sont fusionnées en un nouvel ensemble de signaux qui alimentent un décideur final basé sur l’approche des k-plus proches voisins, qui excelle à repérer des motifs locaux sans supposer une forme particulière des données. Ce processus adaptatif permet à l’ensemble de s’ajuster aux changements de distribution des données, par exemple lorsqu’un nouvel hôpital ou un nouveau profil de patients est introduit.
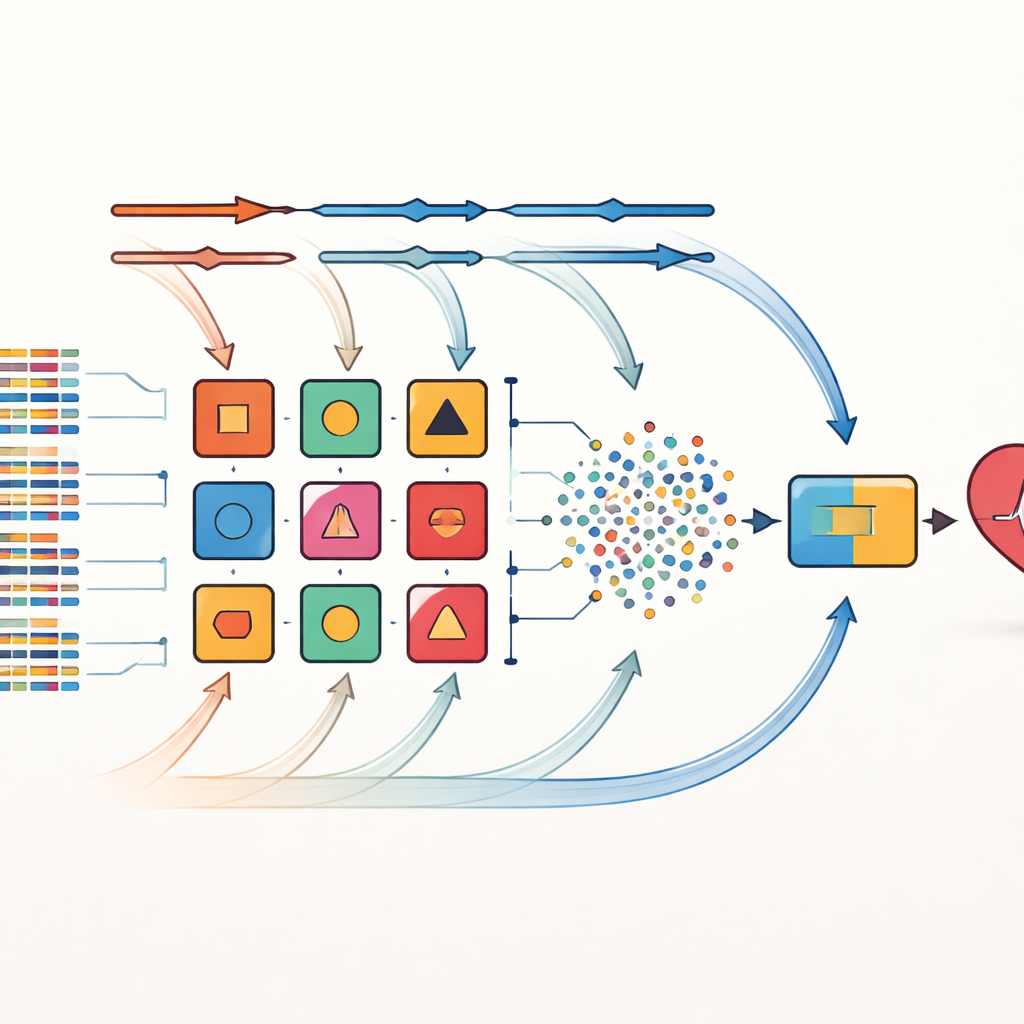
Tests sur des jeux de données cardiaques réels
La méthode a été évaluée sur trois jeux de données cardiovasculaires bien connus : un petit jeu hospitalier équilibré de Cleveland, une étude communautaire plus large et fortement déséquilibrée de Framingham, et un très grand jeu de 70 000 enregistrements contenant des informations numériques et catégorielles. Les chercheurs ont soigneusement nettoyé les données, imputé les valeurs manquantes lorsque c’était approprié et traité les valeurs aberrantes. Sur l’ensemble des trois jeux de données, leur modèle combiné a atteint une précision supérieure et une meilleure discrimination entre patients malades et sains que n’importe lequel des modèles individuels et que plusieurs méthodes récentes avancées. Par exemple, sur les données de Cleveland il a atteint environ 98 % de précision avec une capacité quasi parfaite à séparer les sujets avec et sans maladie cardiaque, et il a également amélioré les performances sur les jeux de données déséquilibrés et à grande échelle.
Ouvrir la boîte noire des prédictions
Pour rendre le système plus acceptable en pratique clinique, l’équipe a utilisé SHAP, une technique moderne d’interprétabilité, pour mesurer la contribution de chaque facteur d’entrée à une prédiction. Plutôt que de se contenter d’indiquer qu’un patient est à haut risque, le modèle peut préciser que le tabagisme, les taux lipidiques ou la glycémie ont été des moteurs majeurs de cette conclusion. Fait intéressant, les caractéristiques les plus influentes identifiées par le modèle correspondent aux recommandations actuelles de prévention en Chine, qui soulignent le tabagisme, les anomalies des lipides sanguins et le diabète comme principaux facteurs modifiables des maladies cardiovasculaires. Des facteurs comme l’âge et la pression artérielle restent importants, mais dans ces jeux de données ils ont contribué un peu moins à la décision finale que les marqueurs liés au mode de vie et au métabolisme.
Ce que cela signifie pour la santé quotidienne
Pour le grand public, l’essentiel est que des modèles informatiques plus intelligents et plus flexibles peuvent affiner la capacité des médecins à prévoir les problèmes cardiaques avant qu’ils ne causent des dommages irréversibles. En combinant de nombreux petits modèles et en rééquilibrant constamment leur influence, l’approche proposée gère mieux les données médicales bruitées, déséquilibrées et changeantes. Parallèlement, l’utilisation d’outils d’interprétabilité aide à maintenir l’attention sur des facteurs de risque familiers — en particulier le tabagisme, le cholestérol et la glycémie — que les patients et les cliniciens peuvent réellement modifier. Bien que des tests supplémentaires en situation clinique réelle et sur des types de données plus riches soient encore nécessaires, ce travail ouvre la voie à des systèmes de prédiction à la fois plus précis et plus transparents pour guider la prévention cardiovasculaire.
Citation: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
Mots-clés: prédiction des maladies cardiovasculaires, apprentissage par ensemble, apprentissage automatique en médecine, facteurs de risque, interprétabilité des modèles