Clear Sky Science · nl
Een methode voor voorspelling van hart- en vaatziekten gebaseerd op cross-combinatiestrategie en dynamische gewogen stacking-ensemble
Waarom voorspelling van hartaandoeningen belangrijk is
Ziekten van hart en bloedvaten blijven wereldwijd de belangrijkste doodsoorzaken en slaan vaak toe zonder duidelijke waarschuwing. Artsen kennen veel risicofactoren—zoals roken, hoog cholesterol en hoge bloedsuiker—maar deze aanwijzingen samenbrengen voor ieder individu is lastig, zeker wanneer gegevens rommelig zijn of afkomstig van verschillende ziekenhuizen en bevolkingsgroepen. Deze studie presenteert een nieuwe computergebaseerde methode die meerdere voorspellingsmodellen combineert en automatisch leert hoeveel vertrouwen aan elk model gegeven moet worden, met als doel het risico op hart- en vaatziekten nauwkeuriger en eerder te detecteren dan bestaande hulpmiddelen.
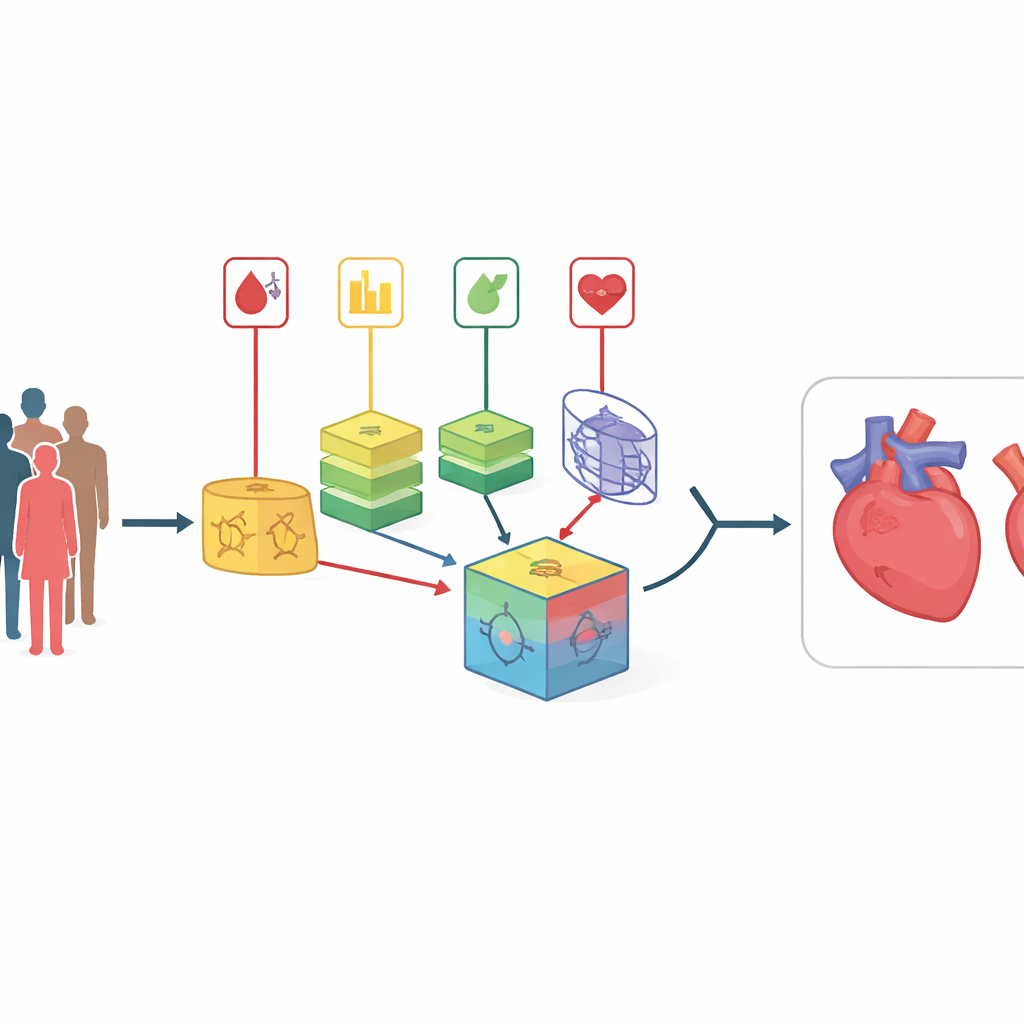
Voorbij eenvoudige risicoscores
Traditionele hart-risicocalculators, zoals bekende klinische scores, gaan uit van vrij eenvoudige, lineaire verbanden tussen metingen en ziekte. In werkelijkheid gedraagt het lichaam zich als een verstrikt web, waarin factoren als cholesterol, bloeddruk en glucose op complexe manieren met elkaar interageren. Recente machine-learningbenaderingen kunnen zulke patronen blootleggen, maar individuele modellen blijven vaak ondoorzichtig “black boxes” en kunnen falen wanneer ze op nieuwe patiëntengroepen worden toegepast. Bestaande gecombineerde-modelmethoden vertrouwen vaak op vaste wegingsfactoren die éénmaal worden vastgesteld en daarna niet worden bijgewerkt, waardoor ze traag zijn in het aanpassen aan veranderingen in patiëntpopulaties of datakwaliteit in de loop van de tijd.
Verschillende gezichtspunten op dezelfde patiënt mengen
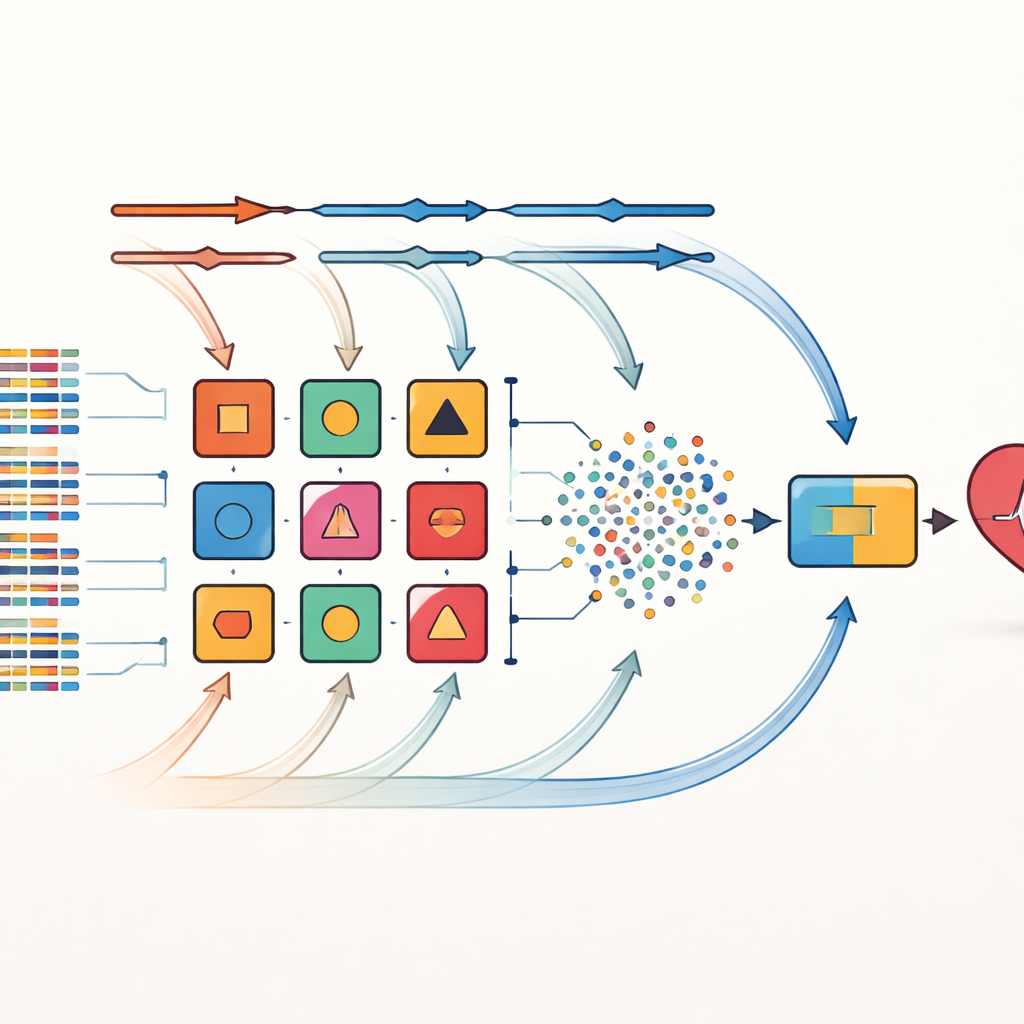
De auteurs pakken deze beperkingen aan met een strategie die zij cross-combinatie noemen. In plaats van te gokken op één manier om belangrijke risicofactoren te selecteren, passen ze acht verschillende feature-selectiemethoden toe op dezelfde datasets. Deze methoden omvatten eenvoudige statistische filters, procedures die herhaaldelijk testen welke variabelen het belangrijkst zijn, en technieken die nauw verbonden zijn met specifieke leeralgoritmen. Elke geselecteerde kenmerkenset wordt vervolgens gekoppeld aan een van 14 uiteenlopende classificatiemodellen, variërend van eenvoudige probabilistische modellen tot beslisbomen en neurale netwerken. In totaal ontstaan zo 112 kandidaat-voorspelmodellen, elk met een iets ander “zicht” op de relaties tussen patiëntkenmerken en hartaandoeningen.
Modellen laten evolueren in gewicht over tijd
Uit deze grote pool worden de tien best presterende modellen gekozen om een ensemble te vormen. De kerninnovatie is hier een dynamisch gewogen stacking-framework. Aanvankelijk krijgt elk basismodel gelijke invloed. Tijdens het trainen test het systeem herhaaldelijk hoe goed elk model het doet op verschillende vouwen van de data en past het zijn gewicht aan op basis van fouten—modellen die beter presteren krijgen meer invloed, terwijl zwakkere modellen geleidelijk worden afgezwakt. De uitkomsten van deze afgestemde basismodellen worden samengevoegd tot een nieuwe set signalen die een uiteindelijke besluitvormer voeden, gebaseerd op de k-nearest neighbors-benadering, die uitblinkt in het herkennen van lokale patronen zonder een specifieke datavorm aan te nemen. Dit adaptieve proces laat het ensemble zich aanpassen aan verschuivingen in datadistributie, bijvoorbeeld wanneer een nieuw ziekenhuis of een andere patiëntmix wordt geïntroduceerd.
Getest op realistische hartdatasets
De methode is geëvalueerd op drie bekende cardiovasculaire datasets: een kleine, gebalanceerde ziekenhuisset uit Cleveland, een grotere en sterk onevenwichtige bevolkingsstudie uit Framingham, en een zeer grote dataset van 70.000 records met zowel numerieke als categorische informatie. De onderzoekers schonen de gegevens zorgvuldig, vulden waar nodig missende waarden in en gingen om met uitbijters. Over alle drie de datasets behaalde hun gecombineerde model hogere nauwkeurigheid en betere discriminatie tussen zieke en gezonde patiënten dan elk individueel model en verschillende recente geavanceerde methoden. Zo behaalde het op de Cleveland-data ongeveer 98 procent nauwkeurigheid met een vrijwel perfecte scheiding tussen patiënten met en zonder hartaandoening, en het verbeterde ook de prestaties op de onevenwichtige en grootschalige datasets.
De black box van voorspellingen openen
Om het systeem acceptabeler te maken in de klinische praktijk, gebruikte het team SHAP, een moderne interpreteerbaarheidstechniek, om te meten hoeveel elke invoerfactor bijdraagt aan een voorspelling. In plaats van alleen te melden dat een patiënt hoog risico heeft, kan het model aangeven dat rookgedrag, lipideniveaus of bloedglucose de belangrijkste drijfveren van die conclusie waren. Interessant genoeg komen de meest invloedrijke kenmerken die het model identificeerde overeen met huidige preventierichtlijnen in China, die roken, abnormale bloedlipiden en diabetes aanwijzen als belangrijke beïnvloedbare oorzaken van hart- en vaatziekten. Factoren zoals leeftijd en bloeddruk blijven van belang, maar binnen deze datasets droegen ze iets minder bij aan de uiteindelijke beslissing dan leefstijl- en metabole markers.
Wat dit betekent voor alledaagse gezondheid
Voor niet-specialisten is de belangrijkste conclusie dat slimere, flexibelere computermodellen artsen beter kunnen helpen hartproblemen te voorspellen voordat die onomkeerbare schade veroorzaken. Door veel kleinere modellen te combineren en voortdurend hun invloed te herevalueren, kan de voorgestelde aanpak beter omgaan met lawaaierige, onevenwichtige en veranderlijke medische data. Tegelijkertijd helpt het gebruik van interpreteerbaarheidstools de focus te houden op bekende risicofactoren—vooral roken, cholesterol en bloedsuiker—die patiënten en clinici daadwerkelijk kunnen beïnvloeden. Hoewel verdere tests in echte klinische omgevingen en op rijkere datatypen nog nodig zijn, wijst dit werk op voorspellingssystemen die zowel nauwkeuriger als transparanter zijn bij het sturen van cardiovasculaire preventie.
Bronvermelding: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
Trefwoorden: voorspelling hart- en vaatziekten, ensemble learning, machine learning in de geneeskunde, risicofactoren, modelinterpreteerbaarheid