Clear Sky Science · he
שיטה לחיזוי מחלות לב וכלי דם המבוססת על אסטרטגיית שילוב צולב ואנסמבל סטאקינג משוקלל דינמי
מדוע חיזוי סיכון לב חשוב
מחלות הלב וכלי הדם נשארות הגורם המוביל למוות ברחבי העולם ולעתים תוקפות ללא סימני אזהרה ברורים. רופאים מכירים גורמי סיכון רבים—למשל עישון, כולסטרול גבוה וסוכר גבוה בדם—אבל שילוב הרמזים הללו עבור כל מטופל הוא אתגר, במיוחד כשהנתונים מבולגנים או מגיעים מבתי חולים ואוכלוסיות שונות. המחקר הזה מציג שיטה ממוחשבת חדשה שמאגדת מספר מודלים לחיזוי ולומדת אוטומטית עד כמה יש לסמוך על כל אחד מהם, במטרה לזהות סיכון למחלות לב וכלי דם בדיוק ובזמן מוקדם יותר מכלים קיימים.
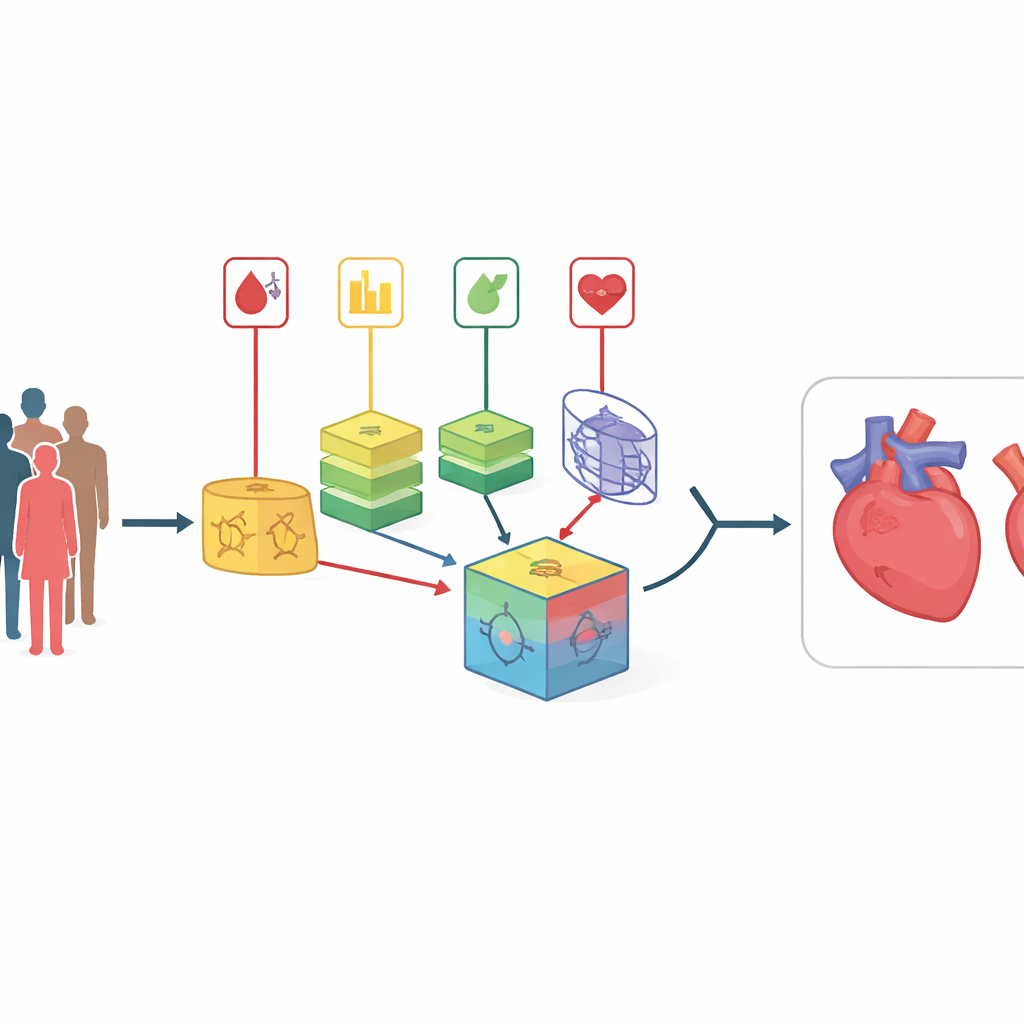
מעבר לציוני סיכון פשוטים
מחשבי הסיכון המסורתיים, כמו ציונים קליניים מוכרים, מניחים יחסים יחסית פשוטים וקו ישר בין מדידות למחלה. במציאות, הגוף מתנהג יותר כמו רשת מסורבלת, שבה גורמים כגון כולסטרול, לחץ דם וגלוקוז באים באינטראקציות מורכבות. שיטות למידת מכונה חדשות יכולות לחשוף דפוסים כאלה, אך מודל יחיד נוטה להיות ״קופסה שחורה״ ועלול להיכשל כשהוא מיושם על קבוצות מטופלים חדשות. גישות שמשלבות מודלים קיימות לעתים מסתמכות על משקולות קבועות שנקבעות פעם אחת ואינן מתעדכנות, דבר שמקשה על התאמתן כאשר אוכלוסיית המטופלים או איכות הנתונים משתנים לאורך זמן.
שילוב מספר מבטים על אותו מטופל
המחברים מתמודדים עם המגבלות הללו באמצעות אסטרטגיה שהם קוראים לה cross-combination. במקום להמר על דרך אחת לבחור את גורמי הסיכון החשובים, הם מיישמים שמונה שיטות שונות לבחירת תכונות על אותם מערכי נתונים. שיטות אלה כוללות מסננים סטטיסטיים פשוטים, נהלים שבוחנים שוב ושוב אילו משתנים חשובים, וטכניקות שקשורות באופן הדוק לאלגוריתמי למידה ספציפיים. כל קבוצת תכונות שנבחרה מזווגת לאחר מכן עם אחד מתוך 14 ממיינים מגוונים, שנעים ממודלים מבוססי הסתברות פשוטים ועד עצי החלטה ורשתות עצביות. בסך הכול נוצרים 112 מודלים מועמדים, שכל אחד מהם נותן ״מבט״ מעט שונה על הקשרים בין מאפייני המטופל למחלת הלב.
מתן ל משקלות המודלים להתפתח לאורך זמן
ממאגר גדול זה נבחרים עשרת המודלים בעלי הביצועים הטובים ביותר להרכבה לאנסמבל. החדשנות המרכזית כאן היא מסגרת סטאקינג משוקללת דינמית. בתחילה, לכל מודל בסיסי מוקנית השפעה שווה. במהלך האימון המערכת בוחנת שוב ושוב עד כמה כל מודל מצליח על קפלי נתונים שונים ומעדכנת את משקלו בהתאם לשגיאות—מודלים שמבצעים טוב זוכים להשפעה גדולה יותר, בעוד חלשים יותר מופחתים בהדרגה. הפלטים של מודלים בסיסיים מותאמים אלה משולבים למערך אותות חדש שמוזן למקבל החלטה סופי המבוסס על שיטת ה-k-nearest neighbors, שמצטיינת בזיהוי דפוסים מקומיים מבלי להניח צורת נתונים ספציפית. תהליך אדפטיבי זה מאפשר לאנסמבל להסתגל לשינויים בהתפלגות הנתונים, למשל כאשר מתווסף בית חולים חדש או משתנה הרכב המטופלים.
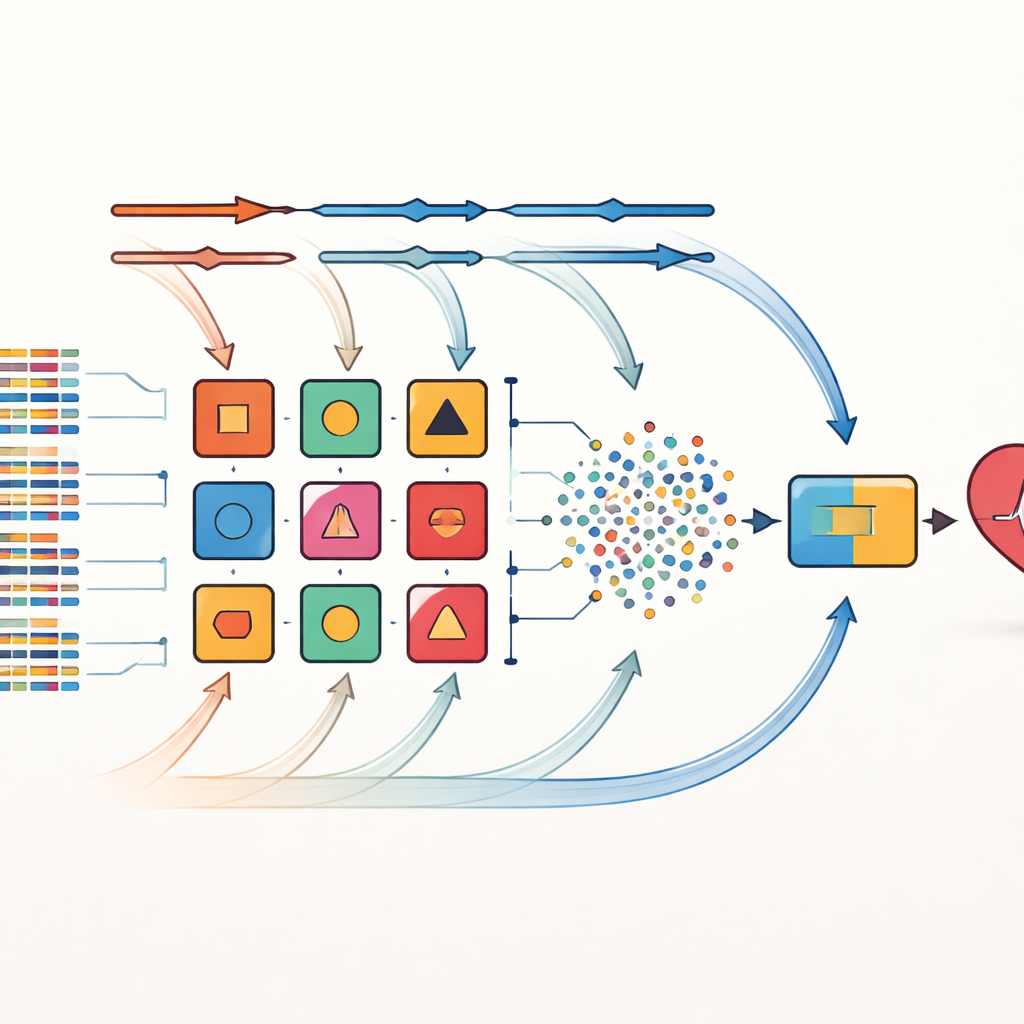
בדיקה על מערכי נתונים מעולם האמיתי
השיטה הוערכה על שלושה מערכי נתונים ידועים של מחלות לב וכלי דם: מערך קטן ומאוזן מבית חולים בקלייוולד, מחקר קהילתי גדול מאד ומאוזן פחות מפרמינגהם, ומערך נתונים ענק של 70,000 רשומות הכולל מידע מספרי וקטגוריאלי. החוקרים ניקו בקפידה את הנתונים, השלימו ערכים חסרים במידת הצורך וטיפלו בקיצוני ערכים. בכל שלושת מערכי הנתונים המודל המשולב שלהם השיג דיוק גבוה יותר והבחנה טובה יותר בין חולים לבריאים מאשר כל אחד מהמודלים הבודדים ומכמה שיטות מתקדמות שהוצעו לאחרונה. לדוגמה, בנתוני קליבלנד הוא הגיע לערך של כ־98% דיוק עם יכולת כמעט מושלמת להפריד בין אלו עם ובלי מחלת לב, והוא גם שיפר ביצועים בקבוצות הבלתי־מאוזנות ובנתוני ההיקף הגדול.
פתיחת ה״קופסה השחורה״ של התחזיות
כדי להגדיל את הקבילות הקלינית של המערכת, הצוות השתמש ב‑SHAP, טכניקת פרשנות מודרנית, כדי למדוד כמה כל גורם קלט תורם לניבוי. במקום לדווח רק שמטופל בסיכון גבוה, המודל יכול להצביע שעישון, רמות שומנים בדם או גלוקוז היו המניעים המרכזיים של המסקנה. באופן מעניין, התכונות המשפיעות ביותר שזוהו על ידי המודל תואמות את קווי ההנחיה המניעתיים הנוכחיים בסין, שמציינות את העישון, שומנים בלתי תקינים בדם וסכרת כגורמים מרכזיים ניתנים לשינוי במניעת מחלות לב. גורמים כמו גיל ולחץ דם עדיין חשובים, אך בתוך מערכי נתונים אלה הם תרמו במידה פחותה יותר להחלטה הסופית מאשר סימנים מטבוליים ואורח חיים.
מה זה אומר לבריאות היומיומית
ללא־מומחים, המסקנה העיקרית היא שמודלים ממוחשבים חכמים וגמישים יותר יכולים לחדד את יכולת הרופאים לצפות בעיות לב לפני שייגרם נזק בלתי הפיך. על ידי שילוב של רבים ממודלים קטנים ואיזון חוזרתי של השפעתם, הגישה המוצעת מתמודדת טוב יותר עם נתונים רועשים, בלתי‑מאוזנים ומשתנים. במקביל, השימוש בכלי פרשנות מסייע לשמור על המיקוד בגורמי הסיכון המוכרים—במיוחד עישון, כולסטרול וסוכר—שאלו מטופלים ומרפאים יכולים לשנות בפועל. אף שעדיין יש צורך בבדיקות נוספות בהגדרות קליניות אמיתיות ועל סוגי נתונים עשירים יותר, עבודה זו מצביעה לכיוון מערכות חיזוי מדויקות ושקופות יותר להנחיית מניעת מחלות לב וכלי דם.
ציטוט: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
מילות מפתח: חיזוי מחלות לב וכלי דם, למידת אנסמבל, למידת מכונה ברפואה, גורמי סיכון, פרשנות המודל