Clear Sky Science · es
Método de predicción de enfermedades cardiovasculares basado en una estrategia de combinación cruzada y ensamblado por apilamiento ponderado dinámico
Por qué importa la predicción del riesgo cardíaco
Las enfermedades del corazón y de los vasos sanguíneos siguen siendo las principales causantes de muerte en todo el mundo, y muchas veces aparecen sin avisos claros. Los médicos conocen numerosos factores de riesgo—como fumar, el colesterol alto y la glucemia elevada—pero integrar estas pistas para cada persona es complicado, especialmente cuando los datos son ruidosos o proceden de distintos hospitales y poblaciones. Este estudio presenta un nuevo método informático que combina muchos modelos de predicción y aprende automáticamente cuánto confiar en cada uno, con el objetivo de detectar el riesgo de enfermedad cardiovascular con mayor precisión y anticipación que las herramientas actuales.
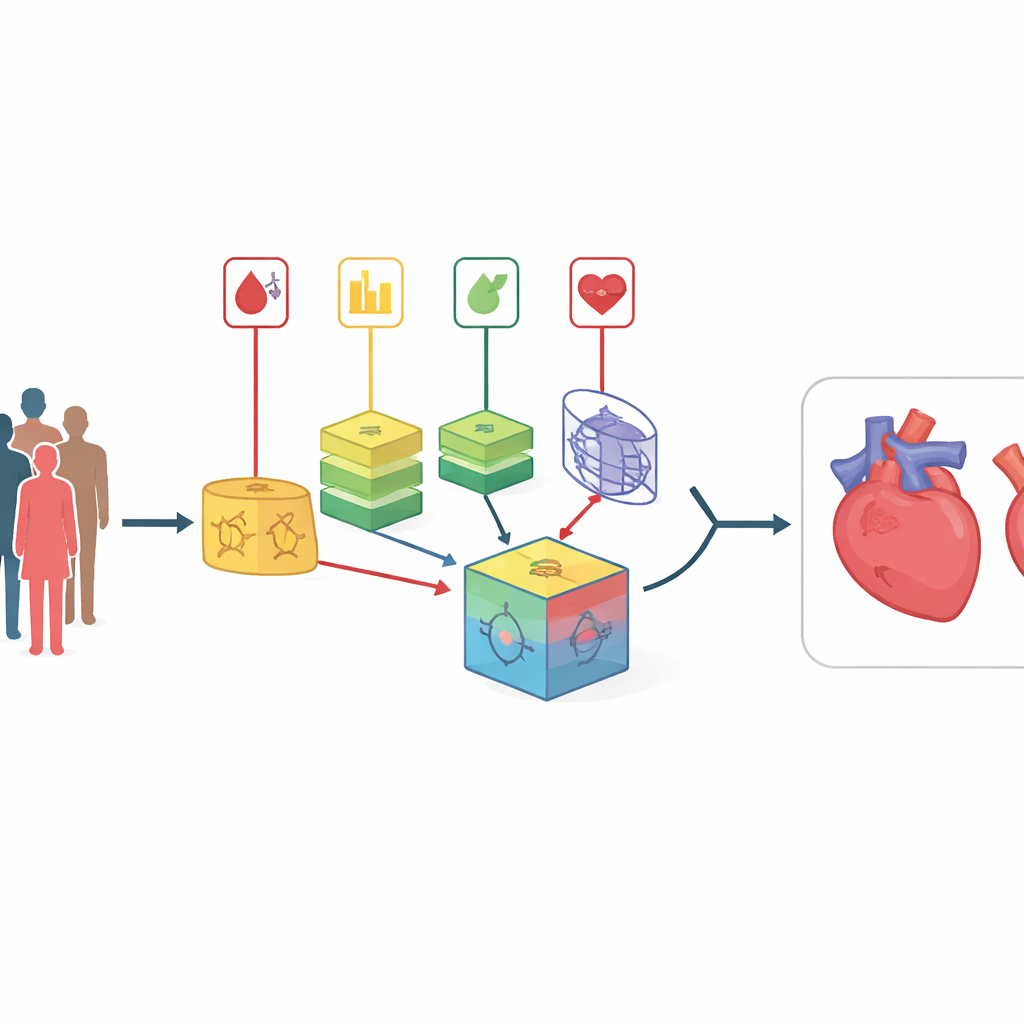
Más allá de las puntuaciones de riesgo simples
Los calculadores tradicionales de riesgo cardíaco, como las puntuaciones clínicas conocidas, asumen relaciones bastante sencillas y lineales entre las mediciones y la enfermedad. En realidad, el organismo se comporta más como una red enmarañada, donde factores como el colesterol, la presión arterial y la glucosa interactúan de maneras complejas. Los enfoques recientes de aprendizaje automático pueden descubrir esos patrones, pero los modelos individuales tienden a comportarse como “cajas negras” opacas y pueden fallar cuando se aplican a nuevos grupos de pacientes. Los métodos existentes de combinación de modelos a menudo dependen de ponderaciones fijas determinadas una sola vez y que no se actualizan, lo que los hace lentos para adaptarse cuando cambian las poblaciones de pacientes o la calidad de los datos.
Mezclando muchas visiones del mismo paciente
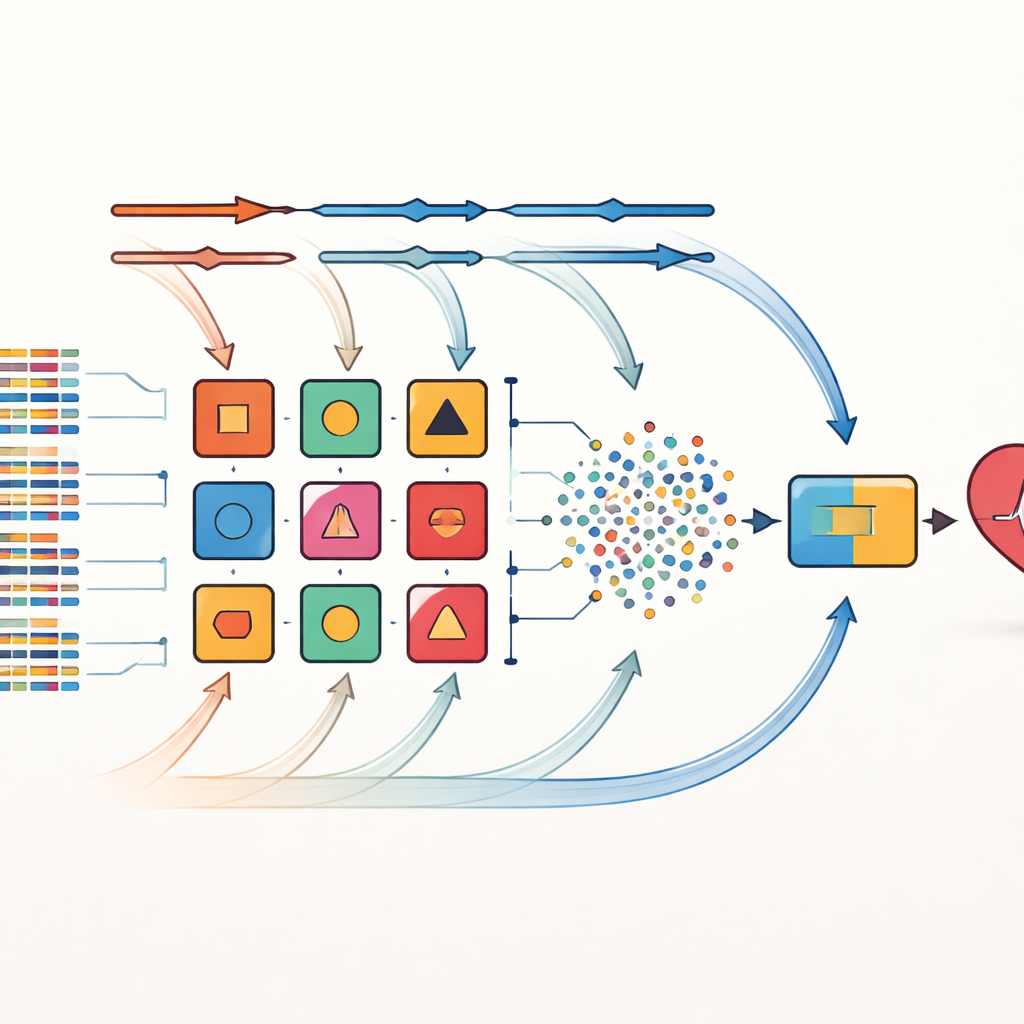
Los autores abordan estas limitaciones con una estrategia que llaman combinación cruzada. En lugar de apostar por una sola forma de seleccionar factores importantes, aplican ocho métodos diferentes de selección de características a los mismos conjuntos de datos. Estos métodos incluyen filtros estadísticos sencillos, procedimientos que prueban repetidamente qué variables importan más y técnicas estrechamente vinculadas a algoritmos de aprendizaje específicos. Cada conjunto de características seleccionado se empareja luego con uno de 14 clasificadores diversos, que van desde modelos probabilísticos simples hasta árboles de decisión y redes neuronales. En total se crean 112 modelos candidatos de predicción, cada uno ofreciendo una “visión” ligeramente distinta de las relaciones entre las características del paciente y la enfermedad cardíaca.
Dejando que las ponderaciones de los modelos evolucionen con el tiempo
De este gran conjunto, se eligen los diez modelos con mejor rendimiento para formar un ensamblado. Aquí la innovación clave es un marco de apilamiento ponderado dinámico. Inicialmente, cada modelo base recibe la misma influencia. Durante el entrenamiento, el sistema evalúa repetidamente lo bien que rinde cada modelo en diferentes particiones de los datos y ajusta su peso en respuesta a los errores: los modelos que funcionan mejor ganan más influencia, mientras que los más débiles se van relegando. Las salidas de estos modelos base ajustados se combinan en un nuevo conjunto de señales que alimentan un decisor final basado en el enfoque de k vecinos más cercanos, que destaca por reconocer patrones locales sin asumir una forma específica de los datos. Este proceso adaptativo permite que el ensamblado se ajuste a cambios en la distribución de los datos, por ejemplo cuando se incorpora un nuevo hospital o una mezcla distinta de pacientes.
Pruebas en conjuntos de datos reales sobre cardiopatías
El método se evaluó en tres conjuntos de datos cardiovasculares bien conocidos: un conjunto hospitalario pequeño y equilibrado de Cleveland, un estudio comunitario mayor y muy desbalanceado de Framingham y un conjunto de datos muy grande de 70.000 registros con información tanto numérica como categórica. Los investigadores limpiaron cuidadosamente los datos, completaron los valores faltantes cuando fue apropiado y gestionaron los valores atípicos. En los tres conjuntos, su modelo combinado alcanzó mayor exactitud y mejor discriminación entre pacientes enfermos y sanos que cualquiera de los modelos individuales y frente a varios métodos avanzados recientes. Por ejemplo, en los datos de Cleveland logró alrededor del 98 por ciento de exactitud con una capacidad casi perfecta para separar a quienes tienen y no tienen enfermedad cardíaca, y también mejoró el rendimiento en los conjuntos de datos desbalanceados y de gran escala.
Abrir la caja negra de las predicciones
Para hacer el sistema más aceptable en la práctica clínica, el equipo utilizó SHAP, una técnica moderna de interpretabilidad, para medir cuánto contribuye cada factor de entrada a una predicción. En lugar de limitarse a informar que un paciente tiene alto riesgo, el modelo puede indicar que el hábito de fumar, los niveles de lípidos o la glucosa en sangre fueron los principales impulsores de esa conclusión. Curiosamente, las características más influyentes identificadas por el modelo coinciden con las guías de prevención actuales en China, que señalan al tabaquismo, las alteraciones de las grasas en sangre y la diabetes como factores modificables clave en las enfermedades cardiovasculares. Factores como la edad y la presión arterial siguen siendo importantes, pero en estos conjuntos de datos contribuyeron algo menos a la decisión final que los marcadores metabólicos y de estilo de vida.
Qué significa esto para la salud cotidiana
Para el público general, la conclusión principal es que modelos informáticos más inteligentes y flexibles pueden afinar la capacidad de los médicos para prever problemas cardíacos antes de que causen daños irreversibles. Al combinar muchos modelos pequeños y reequilibrar constantemente su influencia, el enfoque propuesto maneja mejor datos médicos ruidosos, desequilibrados y cambiantes. Al mismo tiempo, su uso de herramientas de interpretabilidad ayuda a mantener el foco en factores de riesgo conocidos—especialmente el tabaquismo, el colesterol y la glucosa—que pacientes y clínicos pueden realmente modificar. Aunque aún se necesitan más pruebas en entornos clínicos reales y con tipos de datos más variados, este trabajo apunta hacia sistemas de predicción que son a la vez más precisos y más transparentes para orientar la prevención cardiovascular.
Cita: Qi, X., Gao, J., Qi, H. et al. A cardiovascular disease prediction method based on cross-combination strategy and dynamic weighted stacking ensemble. Sci Rep 16, 13901 (2026). https://doi.org/10.1038/s41598-026-48006-3
Palabras clave: predicción de enfermedades cardiovasculares, aprendizaje por ensamblado, aprendizaje automático en medicina, factores de riesgo, interpretabilidad del modelo