Clear Sky Science · tr
Manifold farkındalıklı seyrek modelleme ve işbirlikçi gri kurt optimizasyonu ile federated çok etiketli metin özellik seçimi
Neden daha akıllı metin sıralaması önemli
Her gün hastaneler, haber odaları ve sosyal ağlar, aynı anda birden fazla örtüşen konu ile etiketlenmesi gereken devasa metin kümeleri üretir—örneğin bir tıbbi raporun birden çok hastalık, tedavi ve risk faktörü ile etiketlenmesi gibi. Bu çoklu etiketleme aramayı, öneri sistemlerini ve karar desteğini kolaylaştırır; ancak aynı zamanda bilgisayarları olası sözcük ve ifadelerin uzun listeleriyle aşırı yükler. Makale, kişilerin verilerini kendi cihazlarında tutarken yalnızca en yararlı metin ipuçlarını seçmeyi amaçlayan yeni bir yöntem sunarak bu tür sistemleri hem daha hızlı hem de daha gizlilik odaklı hale getirmeyi hedefliyor.
Gürültüyü temizlemek
Çok etiketli metin problemlerinde her belge birden fazla kategoriye ait olabilir ve bu kategoriler genellikle ilişkilidir: iklim bilimiyle ilgili bir makale politika ve ekonomi konularına da değinebilir. Aynı zamanda modern metin temsilleri—uzun sözlükler veya yoğun gömme vektörleri gibi—binlerce potansiyel sinyal içerir; bunların çoğu gereksiz veya alakasızdır. Bu "çok fazla özellik" sorunu eğitimi yavaşlatır, aşırı uyum (overfitting) riskini artırır ve tahminleri zayıflatır. Yazarlar, bilgilendirici metin özelliklerinin kompakt bir alt kümesini bulma görevi olan özellik seçimine odaklanıyorlar; fakat bunu verilerin birçok cihazda dağıtılmış olduğu ve merkezi bir sunucuda birleştirilemediği bir ortamda yapıyorlar.
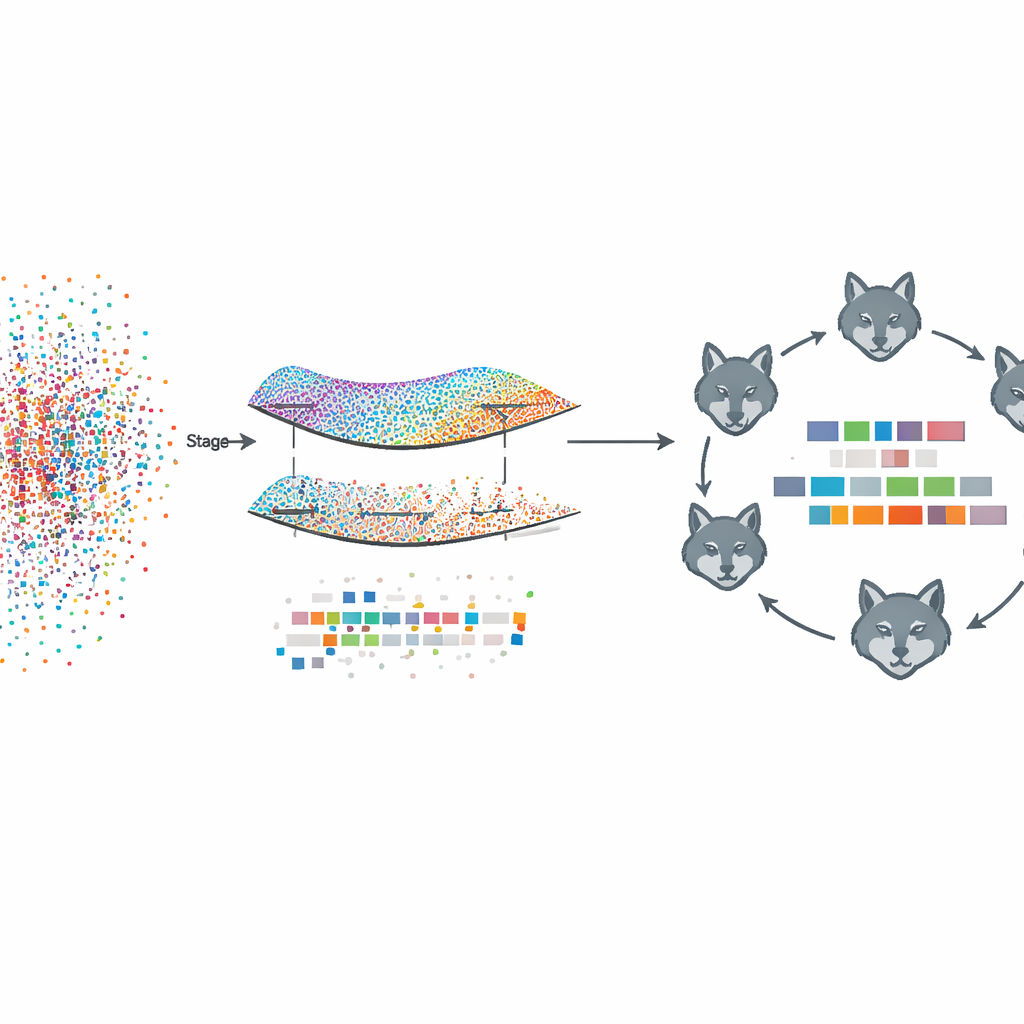
Verileri görmeden yapıyı öğrenmek
Önerilen çerçeve, Fed‑MSMCGWO adını taşır ve federated learning düzeninde çalışır: her istemci cihazı—örneğin bir hastane veya haber sitesı—ham metinlerini ve etiketlerini yerel olarak tutar. İlk aşamada yöntem, belgelerin birbirine nasıl benzediğinin ve etiketlerin nasıl birlikte ortaya çıktığının bir tür haritasını—yani bir manifold—oluşturur. Yakın belgeleri ve ilişkili etiketleri graf yapılarında bağlar, sonra bu yapıları gözeten özellik ağırlıklarını öğrenir. Özel bir seyrekleştirme kuralı, farklı etiketler arasında genel olarak faydasız olan tüm özelliklerin birlikte söndürülmesini teşvik eder; böylece metinler ile etiketleri arasındaki temel ilişkileri koruyan daha sade bir gösterim elde edilir.
Doğadan ilham alan ince ayar
Bu manifold tabanlı budamadan sonra ikinci aşama, kalan özellik ağırlıklarını gri kurt sürülerinden esinlenen biyolojik bir arama stratejisiyle incelikle ayarlar. Aday özellik alt kümeleri, olası çözümler manzarasını keşfeden kurtlar gibi ele alınır. Bunlar, iyi kısmi çözümlerin dikkatli yararlanması ile yeni çözümlerin geniş keşfi arasında denge kuran üç işbirlikçi gruba ayrılır. En iyi performans gösteren sürü üyelerine göre konumlarını tekrar tekrar güncelleyerek, bu sanal kurtlar seyrek kalırken etiketleme performansını daha da iyileştiren özellik kombinasyonlarına odaklanırlar.
Gizliliği koruyarak işbirliği
Her istemci yerel olarak iki aşamalı optimizasyonu çalıştırdıktan sonra yalnızca özellik ağırlıklarını ve seçtiği özellik indekslerini merkezi bir sunucuya gönderir—orijinal belgeler veya etiketler gönderilmez. Sunucu, daha büyük veri kümelerine sahip istemcilere daha fazla ağırlık vererek bu ağırlıkları birleştirir ve hangi özelliklerin en önemli olduğuna dair küresel bir görüş oluşturur. Ardından bu küresel ağırlık vektörünü tüm istemcilere geri gönderir; istemciler bunu başka bir yerel iyileştirme turunu yönlendirmek için kullanır. Birkaç böyle tur genellikle kararlı, paylaşılan bir özellik kümesine ulaşmak için yeterlidir. Bu döngü, kurumların ham metin verilerini paylaşmadan birbirlerinin deneyimlerinden faydalanmasını sağlayan işbirlikçi bir öğrenme süreci yaratır. Yazarlar ayrıca bu tasarımın gelecekte daha güçlü kriptografik araçlarla nasıl birleştirilebileceğini tartışıyorlar.
Kazançları pratikte kanıtlama
Fikirlerini test etmek için araştırmacılar, eğitim, sağlık, sanat ve bilim gibi alanları kapsayan sekiz açık çok etiketli metin veri kümesi üzerinde deneyler yürüttüler. Yöntemlerini, tüm verilerin birleştirilebileceğini varsayan klasik merkezileştirilmiş yaklaşımlar ve daha yeni federated özellik seçimi şemaları ile karşılaştırdılar. Doğru etiketlerin sıralanma doğruluğu ve etiketlerin kaçırılma veya hatalı atanma sıklığı gibi bir dizi standart çok etiket performans ölçütünde yeni çerçeve, genellikle çok az seçilmiş özellikle güçlü doğruluk elde ederek alternatiflerden ya eşit ya da daha iyi performans gösterdi. İstatistiksel testler bu iyileşmelerin tesadüfe bağlı olmadığını doğruladı ve ayrıştırma (ablation) çalışmaları hem manifold modellemenin hem de gri kurt optimizasyonunun genel tasarımın kritik parçaları olduğunu gösterdi.
İleriye dönük anlamı
Düz ifadeyle, bu çalışma, devasa metin temsillerini kısaltmanın, birden çok etiket arasındaki karmaşık ilişkileri gözetmenin ve birçok veri sahibinin işbirliği yapmasının mümkün olduğunu—tüm bunları hassas belgeleri kurumda tutarken—gösteriyor. Yapısal geometrik içgörü ile doğadan ilham alan bir arama stratejisini birleştirerek, Fed‑MSMCGWO daha hızlı, daha doğru ve gizlilik bilincine sahip metin etiketleme sistemleri oluşturmak için pratik bir reçete sunuyor. Yazarlar, bu yaklaşımı düz metin ötesinde daha zengin veri türlerine genişletmeyi ve daha güçlü şifreleme ile eşleştirmeyi öngörüyor; böylece kaynakların içeriğini açığa çıkarmadan birçok kaynaktan öğrenebilen işbirlikçi yapay zekâya zemin hazırlanmış olur.
Atıf: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
Anahtar kelimeler: federated learning, özellik seçimi, çok etiketli metin sınıflandırması, gizlilik korumalı yapay zeka, meta-sezgisel optimizasyon