Clear Sky Science · ar
اختيار ميزات نصية متعددة الوسوم بتعلم اتحادي عبر نمذجة متن-aware متنقلة ونموذج رمزي رمادي تعاوني
لماذا تهم فرز النصوص بشكل أذكى
يولّد المستشفيات، وضوابط الأخبار، والشبكات الاجتماعية يومياً كمّاً هائلاً من النصوص التي يجب وسمها بعدة مواضيع متداخلة في آنٍ واحد — تَخَيّل تقريراً طبياً يحمل وسوماً لعدة أمراض وعلاجات وعوامل خطر. يساعد هذا الوسم المتعدد في البحث والتوصية ودعم القرار، لكنه يثقل كاهل الحواسيب بقوائم هائلة من الكلمات والعبارات المحتملة. تقدم الورقة طريقة جديدة لاختيار مؤشرات النص الأكثر فائدة فقط مع الحفاظ على بيانات الأشخاص على أجهزتهم المحلية، مع هدف جعل هذه الأنظمة أسرع وأكثر احتراماً للخصوصية.
اختراق الضجيج
في مشاكل النصوص متعددة الوسوم، قد ينتمي كل مستند لعدة فئات، وغالباً ما تكون هذه الفئات مترابطة: مقالة عن علوم المناخ قد تمس أيضاً السياسات والاقتصاد. في الوقت نفسه، تمثل التمثيلات الحديثة للنص — مثل القواميس الموسّعة أو التضمينات الكثيفة — آلاف الإشارات المحتملة، كثير منها مكرر أو غير ذي صلة. تؤدي مشكلة «كثرة الميزات» هذه إلى إبطاء التدريب، وتشجيع الإفراط في التخصيص، وإضعاف التنبؤات. يركز المؤلفون على اختيار الميزات، وهي مهمة إيجاد مجموعة مدمجة من ميزات النص المعلوماتية، لكنهم يفعلون ذلك في ظل وضع تتشتت فيه البيانات عبر أجهزة عديدة ولا يمكن تجميعها على خادم مركزي.
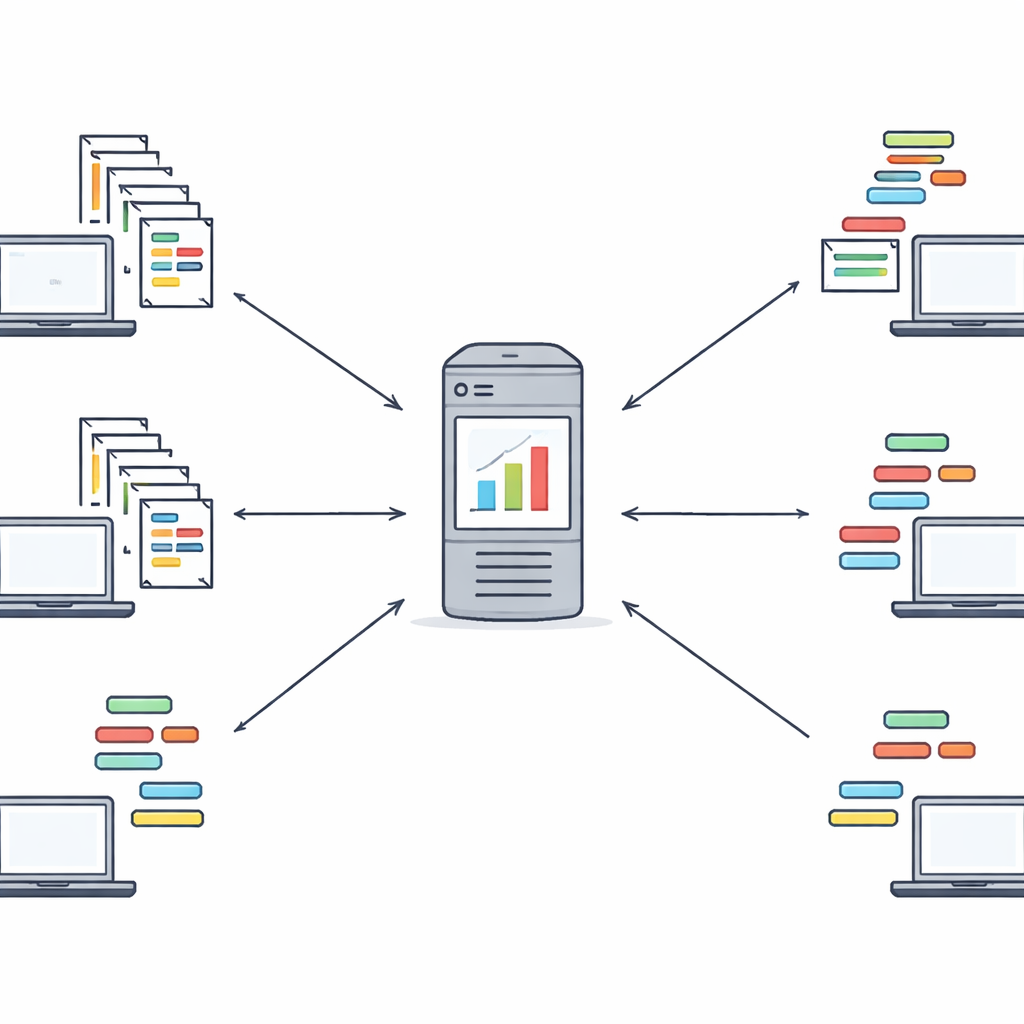
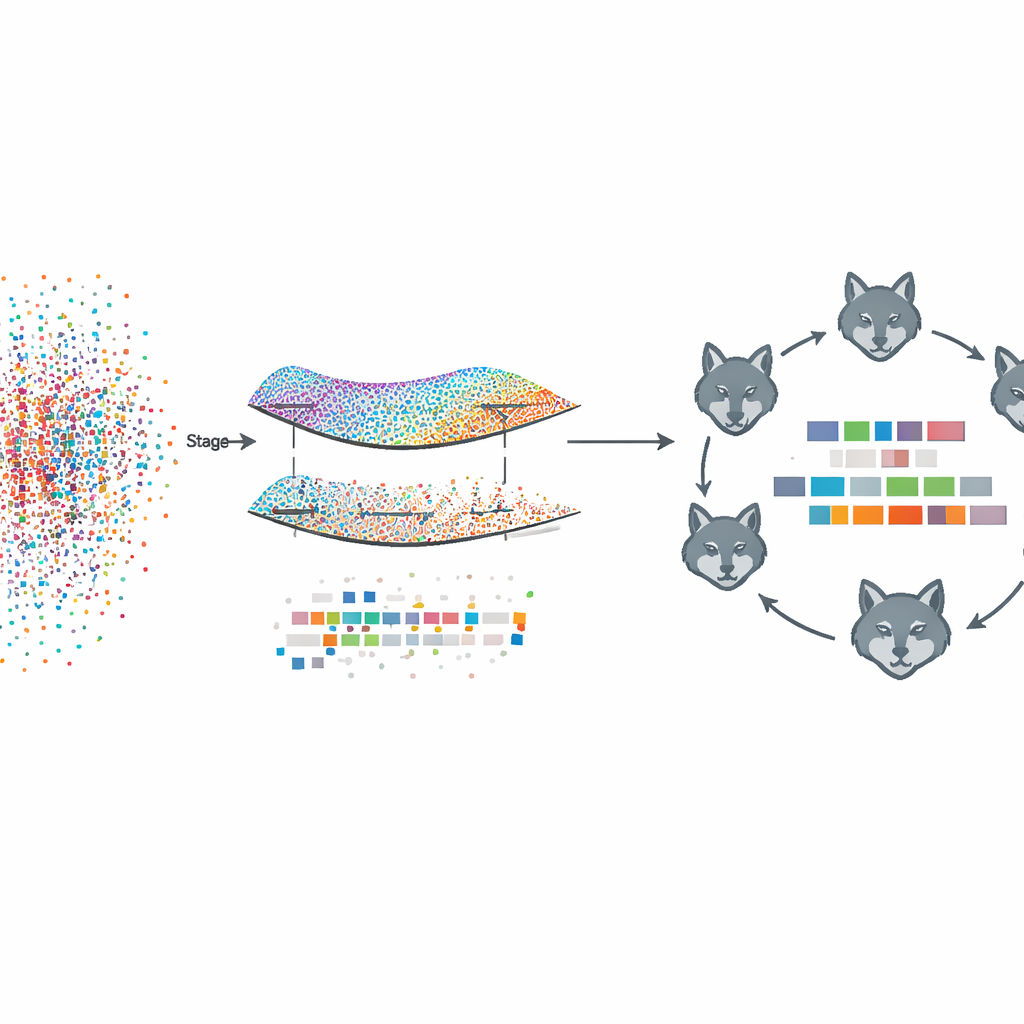
تعلّم البنية دون مشاهدة البيانات
الإطار المقترح، المسمى Fed‑MSMCGWO، يعمل في إعداد التعلّم الاتحادي: يحتفظ كل جهاز عميل، مثل مستشفى أو موقع إخباري، بالنصوص والوسوم الخام محلياً. في المرحلة الأولى، يبني الأسلوب نوعاً من الخريطة — أو المأنifold — تبين كيف تتشابه المستندات مع بعضها وكيف تميل وسومها إلى الترافق. يربط المستندات القريبة والوسوم المرتبطة في رسوم بيانية، ثم يتعلّم أوزان الميزات التي تحترم هذه البنى. قاعدة ندرة خاصة تشجع اختفاء الميزات الكاملة غير المفيدة عبر الوسوم معاً، تاركة تمثيلاً أكثر نحافة لا يزال يلتقط العلاقات الأساسية بين النصوص ووسومها.
ضبط مستوحى من الطبيعة
بعد هذه التقليم المبني على المأنوفولد، تركز المرحلة الثانية على تحسين أوزان الميزات المتبقية باستخدام استراتيجية بحث مستوحاة بيولوجياً نموذجت على أسراب الذئاب الرمادية. تُعامل مجموعات الميزات المرشحة كالذئاب التي تستكشف مشهداً من الحلول المحتملة. تُنظَّم هذه الذئاب في ثلاث مجموعات متعاونة توازن بين الاستغلال الحذر للحلول الجزئية الجيدة والاستكشاف الواسع لحلول جديدة. من خلال تحديث مواقعها مراراً وفقاً لأفضل أعضاء السرب أداءً، تترسّخ هذه الذئاب الافتراضية على تراكيبات ميزات تحسّن الأداء في الوسم مع الحفاظ على الندرة.
التعاون مع البقاء على الخصوصية
بمجرد أن تنفّذ كل جهة عميلة التحسين المكوّن من مرحلتين محلياً، ترسل فقط أوزان ميزاتها ومؤشرات الميزات المختارة إلى خادم مركزي — وليس المستندات أو الوسوم الأصلية. يجمع الخادم هذه الأوزان، مع منح تأثير أكبر للعملاء ذوي مجموعات البيانات الأكبر، ليكوّن رؤية عالمية للميزات الأكثر أهمية. ثم يعيد إرسال متجه الأوزان العالمي إلى جميع العملاء، الذين يستخدمونه لإرشاد جولة أخرى من التكرار المحلي. عادة ما تكفي بضع جولات للوصول إلى مجموعة ميزات مشتركة مستقرة. تخلق هذه الحلقة عملية تعلم تعاونية تستفيد فيها المؤسسات من خبرات بعضها البعض دون مشاركة نصوصها الخام أبداً. كما يناقش المؤلفون كيف يمكن دمج هذا التصميم مع أدوات تشفير أقوى في أعمال مستقبلية.
إثبات الفائدة عملياً
لاختبار فكرتهم، أجرى الباحثون تجارب على ثمانية مجموعات بيانات نصية متعددة الوسوم عامة تغطي مجالات مثل التعليم والصحة والفنون والعلوم. قارنوا طريقتهم مع نهجين مركزيين كلاسيكيين يفترضان إمكانية تجميع كل البيانات، ومع مخططات اختيار ميزات اتحادية أحدث. عبر عدة مقاييس معيارية لأداء متعدد الوسوم — بما في ذلك مدى دقة ترتيب الوسوم الصحيحة ومدى تكرار فقدان أو إساءة تعيين الوسوم — أدى الإطار الجديد باستمرار بمستوى مساوي أو أفضل من البدائل، وغالباً ما بلغ دقة قوية مع عدد قليل مفاجئ من الميزات المختارة. أكدت الاختبارات الإحصائية أن هذه التحسينات لم تكن بالصدفة، وأظهرت دراسات الإلغاء أن كل من نمذجة المأنوفولد وتحسين الذئب الرمادي كانتا قطعتين حاسمتين في التصميم الكلي.
ماذا يعني هذا للمستقبل
بعبارات بسيطة، تُظهر هذه الورقة أنه من الممكن تقليص تمثيلات نصية ضخمة، واحترام العلاقات المعقدة بين وسوم متعددة، والتعاون عبر العديد من حاملي البيانات — وكل ذلك مع إبقاء المستندات الحساسة محلية. من خلال الجمع بين بصيرة هندسية منظمة واستراتيجية بحث مستوحاة من الطبيعة، يقدم Fed‑MSMCGWO وصفة عملية لبناء أنظمة وسم نص أسرع وأكثر دقة ووعيًا بالخصوصية. يتصور المؤلفون توسيع هذا النهج ليمتد إلى أنواع بيانات أغنى وإقرانه بتشفير أقوى، مما يمهّد الطريق لذكاء اصطناعي تعاوني يتعلم من مصادر عديدة دون الكشف عما تحتويه هذه المصادر فعلاً.
الاستشهاد: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
الكلمات المفتاحية: التعلّم الاتحادي, اختيار الميزات, تصنيف النصوص متعددة الوسوم, الذكاء الاصطناعي مع حماية الخصوصية, التحسين الميتاهيرستيك