Clear Sky Science · nl
Gefaedeerde multi-label teksteigenschapsselectie via manifold-bewuste spars modeling en coöperatieve grijze-wolf optimalisatie
Waarom slimmer tekst organiseren ertoe doet
Dagelijks genereren ziekenhuizen, redacties en sociale netwerken zeeën van tekst die tegelijkertijd met vele overlappende onderwerpen moeten worden gemarkeerd—denk aan een medisch rapport gelabeld met meerdere ziekten, behandelingen en risicofactoren. Deze multi-tagging helpt bij zoeken, aanbevelingen en besluitvorming, maar overlaadt ook computers met enorme lijsten van mogelijke woorden en zinsdelen. Het artikel introduceert een nieuwe manier om slechts de meest bruikbare tekens te selecteren terwijl de gegevens van mensen op hun eigen apparaten blijven, met als doel dergelijke systemen zowel sneller als privacysvriendelijker te maken.
Door het ruis heen snijden
Bij multi-tag tekstopgaven kan elk document tot meerdere categorieën behoren, en die categorieën hangen vaak met elkaar samen: een artikel over klimaatwetenschap kan ook beleid en economie behandelen. Tegelijk bevatten moderne textrepresentaties—zoals grote woordenschatten of dichte embeddings—duizenden potentiële signalen, waarvan veel redundant of irrelevant zijn. Dit probleem van “te veel kenmerken” vertraagt training, bevordert overfitting en verzwakt voorspellingen. De auteurs richten zich op eigenschapsselectie, de taak om een compacte subset van informatieve tekstkenmerken te vinden, maar doen dit in een omgeving waarin gegevens verspreid zijn over veel apparaten en niet op een centrale server kunnen worden samengevoegd.
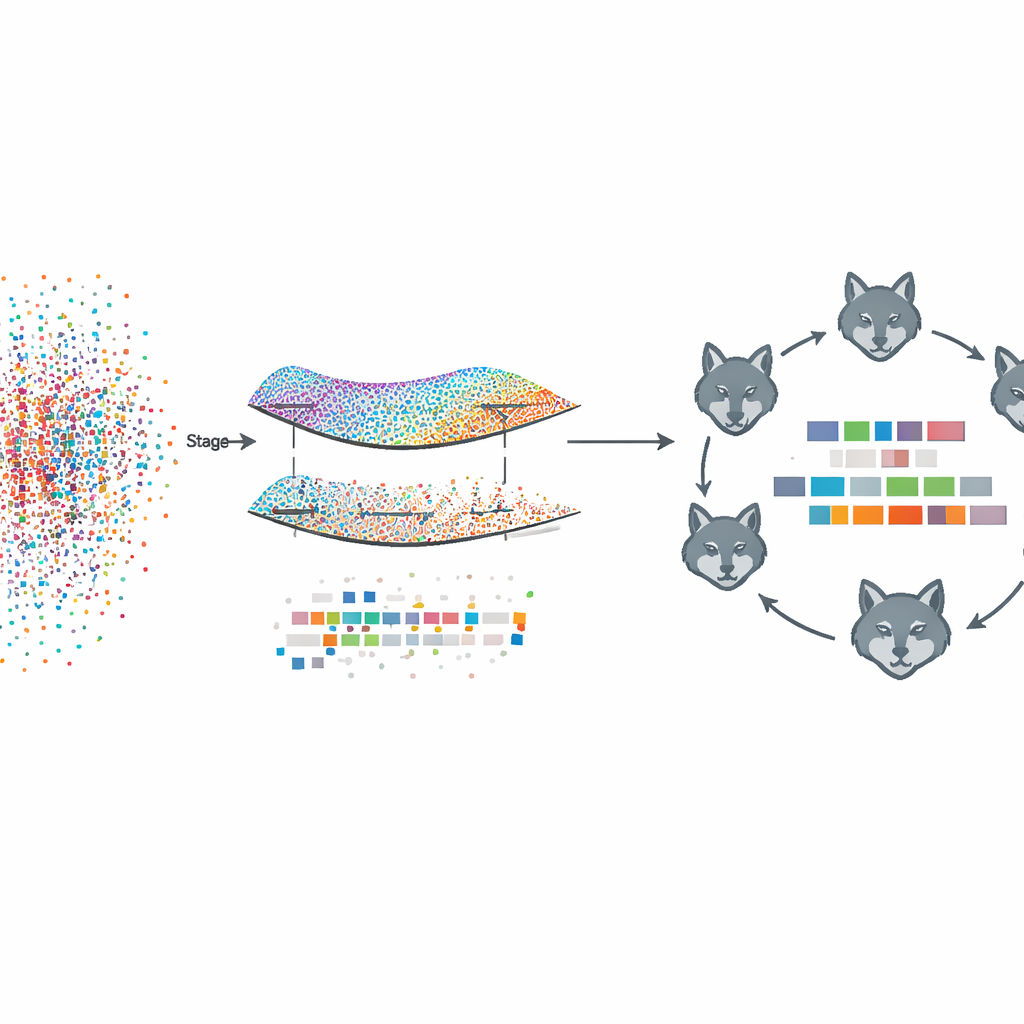
Structuur leren zonder de data te zien
Het voorgestelde kader, Fed‑MSMCGWO genoemd, werkt in een gefedereerde leeropzet: elk clientapparaat, zoals een ziekenhuis of nieuwssite, bewaart zijn ruwe tekst en labels lokaal. In de eerste fase bouwt de methode een soort kaart—of manifold—van hoe documenten op elkaar lijken en hoe hun labels geneigd zijn samen voor te komen. Het koppelt nabijgelegen documenten en gerelateerde labels in grafen en leert vervolgens kenmerkgewichten die deze structuren respecteren. Een speciale sparsiteitsregel moedigt complete kenmerken die over labels heen onbruikbaar zijn aan om samen weg te vallen, waardoor een slanker representatie overblijft die toch de onderliggende relaties tussen teksten en hun tags vastlegt.
Door de natuur geïnspireerde verfijning
Na deze manifold-gebaseerde snoei volgt in de tweede fase een verfijning van de resterende kenmerkgewichten met een bio-geïnspireerde zoekstrategie gemodelleerd naar grijze-wolf roedels. Kandidaatsubsets van kenmerken worden behandeld als wolven die een landschapsruimte van mogelijke oplossingen verkennen. Ze zijn georganiseerd in drie samenwerkende groepen die behoedzame exploitatie van goede deelsoplossingen in balans brengen met brede exploratie van nieuwe mogelijkheden. Door herhaaldelijk hun posities bij te werken op basis van de best presterende roedelleden, richten deze virtuele wolven zich op kenmerkcombinaties die de tagprestaties verder verbeteren terwijl ze spaarzaam blijven.
Samenwerken terwijl privacy gewaarborgd blijft
Zodra elke client de tweefasige optimalisatie lokaal heeft uitgevoerd, stuurt deze alleen zijn kenmerkgewichten en geselecteerde kenmerkindices naar een centrale server—niet de oorspronkelijke documenten of labels. De server combineert deze gewichten en geeft meer invloed aan clients met grotere datasets om een globaal beeld te vormen van welke kenmerken het belangrijkst zijn. Vervolgens stuurt hij deze globale gewichtsvector terug naar alle clients, die deze gebruiken om een nieuwe ronde lokale verfijning aan te sturen. Enkele van dergelijke rondes zijn meestal voldoende om een stabiele gedeelde set kenmerken te bereiken. Deze lus creëert een collaboratief leerproces waarin instellingen profiteren van elkaars ervaring zonder ooit hun ruwe tekstdata te delen. De auteurs bespreken ook hoe dit ontwerp in vervolgonderzoek gecombineerd kan worden met sterkere cryptografische middelen.
De voordelen in de praktijk aantonen
Om hun idee te testen voerden de onderzoekers experimenten uit op acht publieke multi-label tekstdatasets die domeinen beslaan zoals onderwijs, gezondheid, kunst en wetenschap. Ze vergeleken hun methode zowel met klassieke gecentraliseerde benaderingen die veronderstellen dat alle data kunnen worden samengevoegd als met nieuwere gefedereerde eigenschapsselectieschema's. Over verschillende standaardmaten voor multi-label prestaties—waaronder hoe nauwkeurig de juiste tags worden gerangschikt en hoe vaak labels worden gemist of verkeerd toegewezen—presteerde het nieuwe kader consequent even goed of beter dan de alternatieven, vaak met sterke nauwkeurigheid en verrassend weinig geselecteerde kenmerken. Statistische toetsen bevestigden dat deze verbeteringen niet door toeval werden veroorzaakt, en ablatiestudies lieten zien dat zowel het manifoldmodel als de grijze-wolf optimalisatie cruciale onderdelen van het totale ontwerp waren.
Wat dit vooruit betekent
Simpel gezegd laat dit werk zien dat het mogelijk is omvangrijke textrepresentaties terug te snoeien, complexe relaties tussen meerdere tags te respecteren en samen te werken tussen veel gegevenshouders—en dat alles terwijl gevoelige documenten lokaal blijven. Door gestructureerde geometrische inzichten te combineren met een door de natuur geïnspireerde zoekstrategie, biedt Fed‑MSMCGWO een praktisch recept voor het bouwen van snellere, nauwkeurigere en meer privacy-bewuste teksttaggingsystemen. De auteurs voorzien het uitbreiden van deze benadering voorbij platte tekst naar rijkere datatypes en het combineren met sterkere encryptie, en banen zo de weg voor collaboratieve AI die van vele bronnen kan leren zonder bloot te geven wat die bronnen daadwerkelijk bevatten.
Bronvermelding: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
Trefwoorden: gefedereerd leren, eigenschapsselectie, multi-label tekstclassificatie, privacy-behoudende AI, metaheuristische optimalisatie