Clear Sky Science · ru
Федеративный отбор признаков для многометочной текстовой классификации через манироидно-осознанное разреженное моделирование и кооперативную оптимизацию «серых волков»
Почему более умная сортировка текста важна
Ежедневно больницы, редакции и социальные сети генерируют океаны текста, которые нужно отмечать множеством пересекающихся тем одновременно — представьте медицинский отчёт с несколькими заболеваниями, лечениями и факторами риска. Такое многометочное аннотирование помогает поиску, рекомендациям и принятию решений, но одновременно нагружает вычислительные системы огромными списками возможных слов и фраз. В статье предложен новый способ отбирать лишь наиболее полезные текстовые сигналы, сохраняя при этом данные людей на их собственных устройствах, с целью сделать такие системы быстрее и более конфиденциальными.
Прорваться сквозь шум
В задачах с многими метками каждый документ может принадлежать нескольким категориям, и эти категории часто взаимосвязаны: статья о климатической науке может затрагивать политику и экономику. В то же время современные представления текста — длинные словари или плотные эмбеддинги — содержат тысячи потенциальных сигналов, многие из которых избыточны или нерелевантны. Эта проблема «слишком большого числа признаков» замедляет обучение, способствует переобучению и ухудшает прогнозы. Авторы сосредотачиваются на отборе признаков — задаче нахождения компактного набора информативных текстовых признаков — но делают это в условиях, когда данные разбросаны по множеству устройств и не могут быть объединены на центральном сервере.
Обучение структуры без просмотра данных
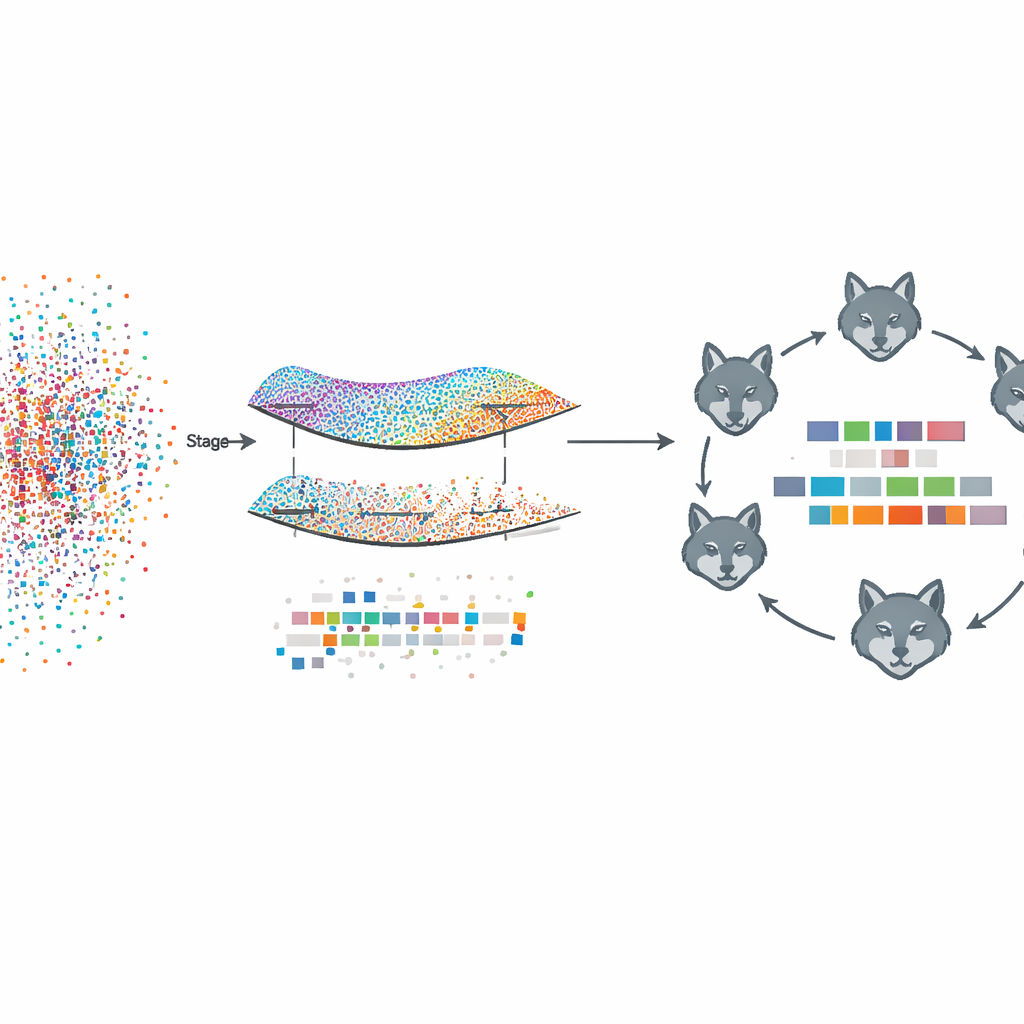
Предложенная структура, названная Fed‑MSMCGWO, работает в режиме федеративного обучения: каждое клиентское устройство, например больница или новостной сайт, хранит свои исходные тексты и метки локально. На первом этапе метод строит своего рода карту — многообразие — того, как документы похожи друг на друга и как их метки склонны сосуществовать. Он связывает близкие документы и связанные метки в графы, а затем обучает веса признаков с учётом этих структур. Специальное правило разрежения поощряет совместное «затухание» целых признаков, которые не полезны для множества меток, оставляя более компактное представление, которое всё ещё отражает скрытые связи между текстами и их метками.
Тонкая настройка, вдохновлённая природой
После этого многообразного отсечения второй этап углублённо уточняет оставшиеся веса признаков, используя био-вдохновлённую стратегию поиска, модель которой основана на стаях серых волков. Кандидатные наборы признаков рассматриваются как волки, исследующие ландшафт возможных решений. Они организованы в три кооперативные группы, балансирующие осторожную эксплуатацию хороших частичных решений и широкое исследование новых вариантов. Повторно обновляя свои позиции в соответствии с лучшими членами стаи, эти виртуальные «волки» сходятся к комбинациям признаков, которые дополнительно улучшают точность разметки при сохранении разреженности.
Сотрудничество при сохранении конфиденциальности
Когда каждый клиент завершит двухэтапную оптимизацию локально, он отправляет на центральный сервер только свои веса признаков и выбранные индексы — не исходные документы и не метки. Сервер объединяет эти веса, придавая больший вес клиентам с большими наборами данных, чтобы сформировать глобальное представление о том, какие признаки наиболее важны. Затем он рассылает этот глобальный вектор весов обратно всем клиентам, которые используют его для следующего раунда локальной донастройки. Обычно нескольких таких итераций достаточно, чтобы получить стабильный общий набор признаков. Этот цикл создаёт совместный процесс обучения, при котором организации извлекают выгоду из опыта друг друга, не передавая свои сырые текстовые данные. Авторы также обсуждают, как эту архитектуру можно комбинировать с более мощными криптографическими средствами в будущих работах.
Подтверждение выгоды на практике
Для проверки идеи исследователи провели эксперименты на восьми публичных наборах многометочных текстовых данных из областей образования, здравоохранения, искусства и науки. Они сравнили свой метод с классическими централизованными подходами, предполагающими объединение всех данных, и с новыми федеративными схемами отбора признаков. По ряду стандартных метрик многометочной эффективности — включая то, насколько правильно ранжируются метки и как часто метки пропускаются или ошибочно назначаются — новая структура последовательно показывала результаты не хуже и часто лучше альтернатив, зачастую достигая высокой точности при удивительно небольшом числе отобранных признаков. Статистические тесты подтвердили, что эти улучшения не случайны, а исследования по отбрасыванию компонентов (ablation) показали, что и моделирование многообразия, и оптимизация «серых волков» являются ключевыми элементами общей конструкции.
Что это означает в будущем
Проще говоря, эта работа показывает, что возможно сократить массивные текстовые представления, учитывать сложные взаимосвязи между множественными метками и сотрудничать между множеством держателей данных — всё это при сохранении конфиденциальных документов локально. Сочетая структурное геометрическое понимание с натуралистичной стратегией поиска, Fed‑MSMCGWO предлагает практический рецепт для создания более быстрых, точных и ориентированных на конфиденциальность систем разметки текста. Авторы предполагают расширять этот подход за пределы простого текста на более богатые типы данных и сочетать его с усиленной защитой шифрованием, прокладывая путь к совместному ИИ, который может учиться у многих источников, не раскрывая содержимого этих источников.
Цитирование: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
Ключевые слова: федеративное обучение, отбор признаков, многометочная текстовая классификация, конфиденциальный ИИ, метаэвристическая оптимизация