Clear Sky Science · de
Föderierte Multi-Label-Textmerkmal-Auswahl mittels mannigfaltigkeitsbewusster sparsamer Modellierung und kooperativer Grey-Wolf-Optimierung
Warum intelligenteres Textsortieren wichtig ist
Tagtäglich erzeugen Krankenhäuser, Redaktionen und soziale Netzwerke Ozeane von Texten, die gleichzeitig mit vielen überlappenden Themen versehen werden müssen – denken Sie an einen medizinischen Bericht, der mit mehreren Krankheiten, Behandlungen und Risikofaktoren gekennzeichnet ist. Dieses Mehrfach-Tagging unterstützt Suche, Empfehlungen und Entscheidungsunterstützung, überflutet aber Rechner mit riesigen Listen möglicher Wörter und Phrasen. Die Arbeit stellt eine neue Methode vor, nur die nützlichsten Textindikatoren auszuwählen, dabei die Daten der Nutzer auf ihren eigenen Geräten zu belassen und so Systeme sowohl schneller als auch datenschutzfreundlicher zu machen.
Dem Rauschen den Schnitt setzen
Bei Multi-Label-Textproblemen kann jedes Dokument zu mehreren Kategorien gehören, die oft miteinander verwandt sind: Ein Artikel über Klimawissenschaften kann auch Politik und Wirtschaft berühren. Gleichzeitig enthalten moderne Textrepräsentationen – etwa umfangreiche Vokabulare oder dichte Embeddings – Tausende potenzieller Signale, von denen viele redundant oder irrelevant sind. Dieses „zu viele Merkmale“-Problem verlangsamt das Training, fördert Overfitting und schwächt Vorhersagen. Die Autoren konzentrieren sich auf Merkmalsauswahl, also die Aufgabe, eine kompakte Teilmenge informativer Textmerkmale zu finden; und zwar in einem Szenario, in dem Daten über viele Geräte verteilt sind und nicht zentral zusammengeführt werden können.
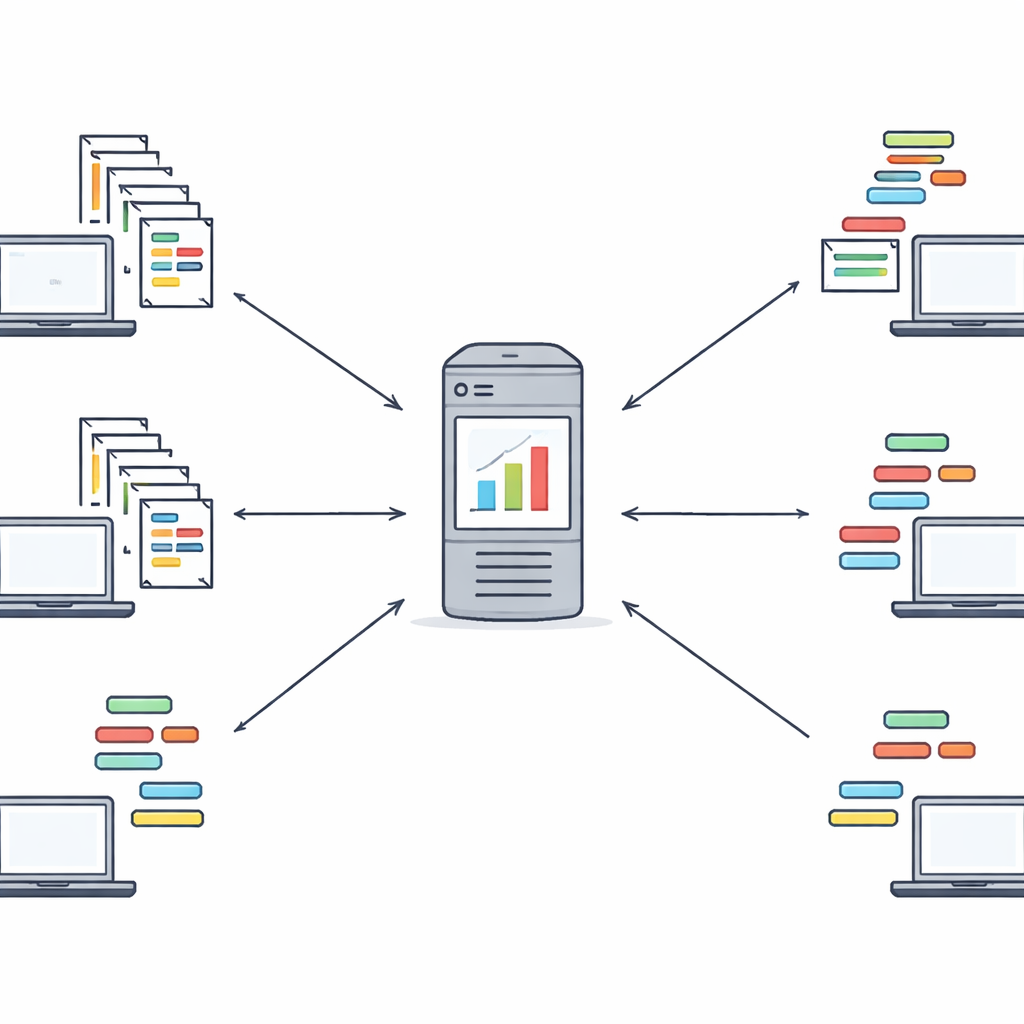
Struktur lernen, ohne die Daten zu sehen
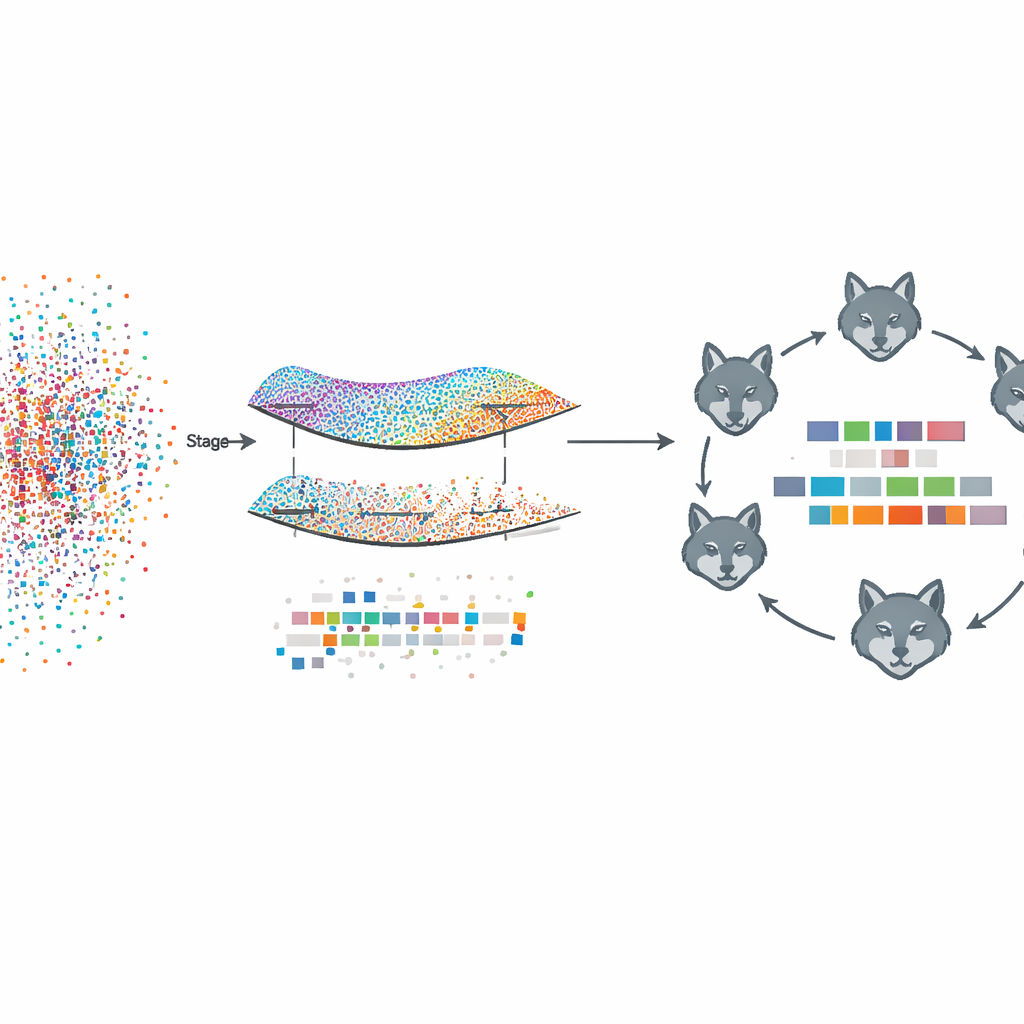
Das vorgeschlagene Framework, Fed‑MSMCGWO genannt, arbeitet in einer föderierten Lernumgebung: Jedes Client-Gerät, etwa ein Krankenhaus oder eine Nachrichtenseite, behält seine Rohtexte und Labels lokal. In der ersten Phase baut die Methode eine Art Karte – oder Mannigfaltigkeit – darüber auf, wie Dokumente einander ähneln und wie sich ihre Labels gemeinsam auftun. Sie verknüpft nahe Dokumente und verwandte Labels zu Graphen und lernt anschließend Merkmalsgewichte, die diese Strukturen respektieren. Eine spezielle Sparsitätsregel fördert das gleichzeitige Ausblenden ganzer Merkmale, die über Labels hinweg uninformativ sind, sodass eine schlankere Repräsentation entsteht, die dennoch die zugrundeliegenden Beziehungen zwischen Texten und ihren Tags einfängt.
Feinabstimmung inspiriert von der Natur
Nach diesem mannigfaltigkeitsbasierten Beschneiden verfeinert die zweite Phase die verbleibenden Merkmalsgewichte mithilfe einer bio-inspirierten Suchstrategie, die an Rudelverhalten von Grauwölfen angelehnt ist. Kandidaten-Merkmalsmengen werden wie Wölfe betrachtet, die eine Landschaft möglicher Lösungen erkunden. Sie sind in drei kooperierende Gruppen organisiert, die vorsichtiges Ausbeuten guter Teillösungen mit breiter Erkundung neuer Bereiche ausbalancieren. Durch wiederholtes Aktualisieren ihrer Positionen entsprechend der leistungsstärksten Rudelmitglieder nähern sich diese virtuellen Wölfe Merkmalskombinationen an, die die Tagging-Leistung weiter verbessern, während die Sparsamkeit erhalten bleibt.
Zusammenarbeiten und dabei privat bleiben
Sobald jeder Client die zweistufige Optimierung lokal ausgeführt hat, sendet er nur seine Merkmalsgewichte und die ausgewählten Merkmalsindizes an einen zentralen Server – nicht die Originaldokumente oder Labels. Der Server kombiniert diese Gewichte und gewichtet dabei Clients mit größeren Datensätzen stärker, um eine globale Sicht darauf zu formen, welche Merkmale am wichtigsten sind. Dieses globale Gewichtssignal wird an alle Clients zurückgeschickt, die es zur Steuerung einer weiteren Runde lokaler Verfeinerung nutzen. Ein paar solcher Runden genügen meist, um einen stabilen gemeinsamen Merkmalsatz zu erreichen. Diese Schleife schafft einen kollaborativen Lernprozess, bei dem Institutionen voneinander profitieren, ohne jemals ihre Rohtextdaten zu teilen. Die Autoren diskutieren zudem, wie dieses Design in zukünftiger Arbeit mit stärkeren kryptografischen Werkzeugen kombiniert werden kann.
Die Vorteile in der Praxis belegen
Um ihre Idee zu prüfen, führten die Forschenden Experimente auf acht öffentlichen Multi-Label-Textdatensätzen durch, die Bereiche wie Bildung, Gesundheit, Kunst und Wissenschaft abdecken. Sie verglichen ihre Methode mit klassischen zentralisierten Ansätzen, die davon ausgehen, dass alle Daten zusammengeführt werden können, sowie mit neueren föderierten Merkmalsauswahlverfahren. Über mehrere standardisierte Maße für Multi-Label-Leistung hinweg – einschließlich wie akkurat die richtigen Tags gerankt werden und wie oft Labels übersehen oder falsch zugewiesen werden – schnitt das neue Framework durchweg genauso gut oder besser ab als die Alternativen und erreichte häufig starke Genauigkeit mit überraschend wenigen ausgewählten Merkmalen. Statistische Tests bestätigten, dass diese Verbesserungen nicht zufällig waren, und Ablationsstudien zeigten, dass sowohl die Mannigfaltigkeitsmodellierung als auch die Grey-Wolf-Optimierung entscheidende Bestandteile des Gesamtdesigns sind.
Was das für die Zukunft bedeutet
Einfach gesagt zeigt diese Arbeit, dass es möglich ist, massive Textrepräsentationen zu reduzieren, komplexe Beziehungen zwischen mehreren Tags zu respektieren und über viele Datenhalter hinweg zusammenzuarbeiten – und das alles, während sensible Dokumente lokal verbleiben. Durch die Kombination strukturierter geometrischer Einsichten mit einer naturinspirierten Suchstrategie bietet Fed‑MSMCGWO ein praktisches Rezept für schnellere, genauere und datenschutzfreundlichere Text-Tagging-Systeme. Die Autoren sehen vor, diesen Ansatz über reinen Text hinaus auf reichere Datentypen auszudehnen und ihn mit stärkerer Verschlüsselung zu koppeln, wodurch kollaborative KI möglich wird, die von vielen Quellen lernt, ohne deren Inhalte preiszugeben.
Zitation: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
Schlüsselwörter: föderiertes Lernen, Merkmalsauswahl, Multi-Label-Textklassifikation, privatsphärewahrende KI, metaheuristische Optimierung