Clear Sky Science · ja
多様体認識スパースモデリングと協調グレイウルフ最適化によるフェデレーテッド多ラベルテキスト特徴選択
なぜ賢いテキスト分類が重要なのか
病院、ニュース編集部、ソーシャルネットワークは日々膨大なテキストを生み出し、それらに重なり合う複数のトピックを同時に付与する必要があります。たとえば医療報告書には複数の病名、治療法、リスク要因がタグ付けされることがあります。こうした多重タグ付けは検索や推薦、意思決定支援に役立ちますが、同時に膨大な語彙やフレーズの候補で計算を圧迫します。本論文は、利用価値の高いテキストの手がかりだけを選び出しつつ、各人のデータを端末内に残すことで、より高速かつプライバシー重視のシステムを目指す新たな手法を提示します。
ノイズを切り分ける
多ラベルのテキスト問題では、各文書が複数のカテゴリに属し得て、しかもそれらのカテゴリはしばしば関連しています。気候科学の記事が政策や経済にも触れることがあるように。一方で、長大な語彙や密な埋め込み表現のような現代のテキスト表現は、数千もの潜在的な信号を含み、その多くは冗長か無関係です。「特徴過多」の問題は学習を遅くし、過学習を招き、予測精度を低下させます。著者らは情報量の高いテキスト特徴のコンパクトな部分集合を見つける特徴選択に着目しますが、データが多数の端末に分散しており中央サーバに集約できないという状況でこれを行います。
データを見ずに構造を学ぶ
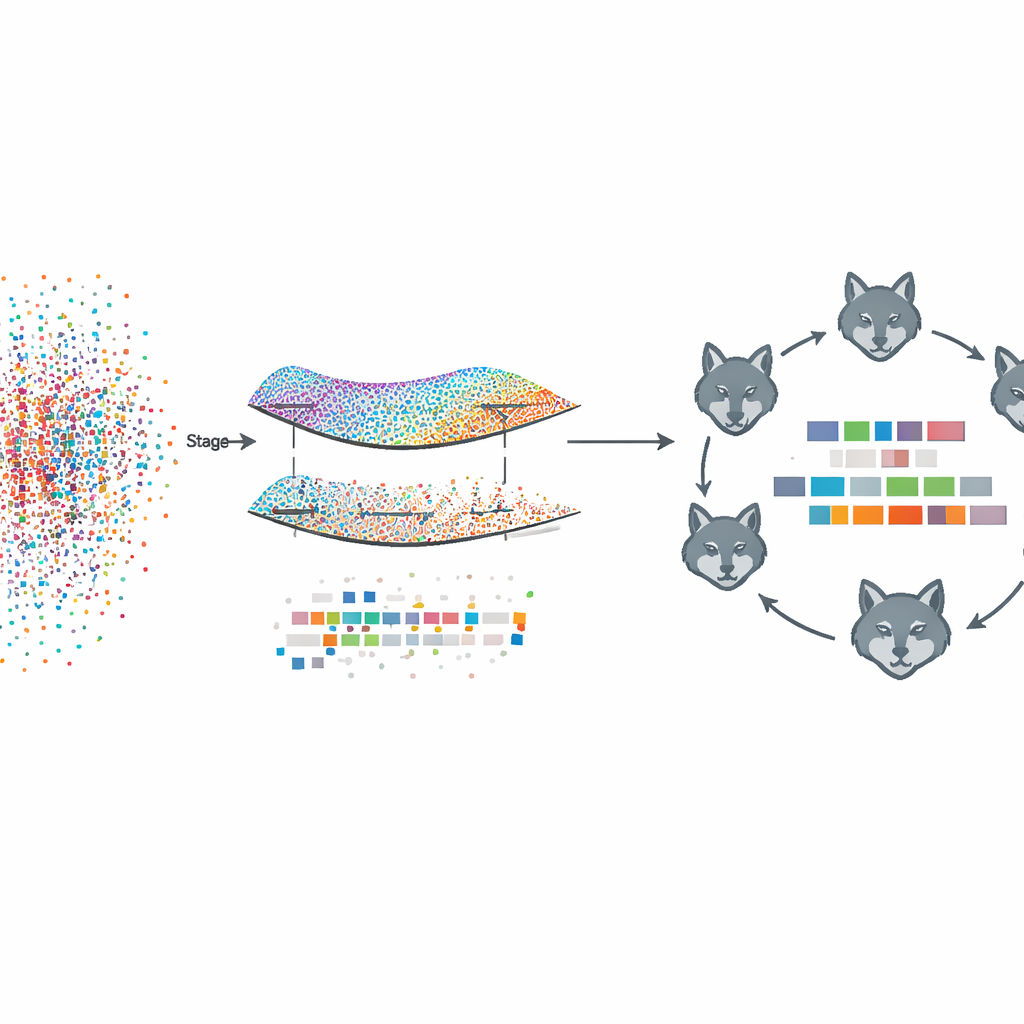
提案するフレームワークFed‑MSMCGWOはフェデレーテッドラーニングの枠組みで動作します。病院やニュースサイトのような各クライアントは生のテキストとラベルをローカルに保持します。第1段階では、文書同士の類似性やラベルの共起傾向といった「多様体(マニフォールド)」のような地図を構築します。近接する文書と関連するラベルをグラフで結び、それらの構造を尊重する形で特徴重みを学習します。特別なスパース化の規則により、複数ラベルにわたって有用でない特徴はまとめて消えやすくなり、テキストとタグの間にある基本的な関係を保持したままより簡潔な表現が得られます。
自然に着想を得た微調整
この多様体に基づく剪定の後、第二段階では残った特徴重みをグレイウルフの群れに着想を得た生物模倣の探索戦略で精緻化します。候補となる特徴集合を、解空間を探索する“オオカミ”に見立てます。これらは慎重に良好な部分解を突き詰める群れと、新しい探索を広く行う群れの三つの協調するグループに組織されます。各群れが最良メンバーに従って位置を更新し続けることで、仮想ウルフたちはさらに性能を高めつつスパース性を保つ特徴の組合せへと収束します。
プライバシーを保ちながらの協調
各クライアントが二段階の最適化をローカルで実行した後、送られるのは生の文書やラベルではなく、特徴重みと選択された特徴のインデックスのみです。サーバはこれらの重みを結合し、データ量の多いクライアントにより大きな影響力を与えて、どの特徴が重要かのグローバルな見解を形成します。続いてこのグローバル重みベクトルを全クライアントへ返送し、それを手掛かりに別のローカル精緻化を行います。数回の往復で安定した共有特徴集合に到達することが多く、このループにより各機関は生データを一切共有することなく互いの経験を生かせます。著者らは将来的により強力な暗号化手法と組み合わせる可能性についても議論しています。
実践での利得を示す
提案法の検証のために、研究者らは教育、医療、芸術、科学といった領域を含む8つの公開多ラベルテキストデータセットで実験を行いました。従来の中央集権的手法(全データを集約できると仮定するもの)や最近のフェデレーテッドな特徴選択手法と比較したところ、複数の標準的な多ラベル性能指標(正しいタグのランキング精度、ラベルの見逃しや誤割り当ての頻度など)において、本フレームワークは一貫して他手法と同等かそれ以上の性能を示し、しばしば驚くほど少ない選択特徴数で高い精度に到達しました。統計的検定によってこれらの改善が偶然によるものではないことが確認され、アブレーション研究により多様体モデリングとグレイウルフ最適化の両方が設計上重要であることが示されました。
今後の意味合い
平たく言えば、本研究は巨大なテキスト表現を削ぎ落としつつ、複雑な多重タグ間の関係を尊重し、多数のデータ保有者間で協力できることを、機密文書を端末に残したまま実現できることを示しています。構造化された幾何学的知見と自然に着想を得た探索戦略を組み合わせることで、Fed‑MSMCGWOは高速で高精度、かつプライバシー配慮したテキストタグ付けシステムを構築する実用的な手引きを提供します。著者らはこのアプローチをプレーンテキスト以外のより豊かなデータ種に拡張し、より強力な暗号化と組み合わせることで、多数の情報源から学びながらそれらの内容を露出しない協調的AIの実現へ道を開くことを見込んでいます。
引用: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
キーワード: フェデレーテッドラーニング, 特徴選択, 多ラベルテキスト分類, プライバシー保護AI, メタヒューリスティック最適化