Clear Sky Science · pl
Federacyjny wybór cech w tekście wieloetykietowym przez manifold‑świadome skąpe modelowanie i kooperatywną optymalizację szarych wilków
Dlaczego mądrzejsze sortowanie tekstu ma znaczenie
Codziennie szpitale, redakcje i serwisy społecznościowe generują oceany tekstu, które trzeba oznaczać wieloma nakładającymi się tematami jednocześnie — pomyśl o raporcie medycznym oznaczonym kilkoma chorobami, terapiami i czynnikami ryzyka. Taka wieloetykietowość ułatwia wyszukiwanie, rekomendacje i wspomaganie decyzji, ale jednocześnie zasypuje systemy ogromnymi listami możliwych słów i fraz. Artykuł przedstawia nowy sposób wyłuskiwania tylko najbardziej użytecznych wskazówek tekstowych, przy zachowaniu danych użytkowników na ich własnych urządzeniach, z zamiarem uczynienia takich systemów zarówno szybszymi, jak i bardziej prywatnymi.
Przecinając szum
W problemach z wieloma etykietami każdy dokument może należeć do kilku kategorii, które często są ze sobą powiązane: artykuł o klimacie może również poruszać politykę czy ekonomię. Jednocześnie współczesne reprezentacje tekstu — szerokie słownictwa czy gęste osadzenia — zawierają tysiące potencjalnych sygnałów, z których wiele jest redundantnych lub nieistotnych. Ten problem „zbyt wielu cech” spowalnia uczenie, sprzyja przeuczeniu i osłabia predykcję. Autorzy koncentrują się na selekcji cech, czyli zadaniu znalezienia zwartego podzbioru informatywnych cech tekstowych, ale robią to w scenariuszu, w którym dane są rozproszone po wielu urządzeniach i nie mogą być zebrane na centralnym serwerze.
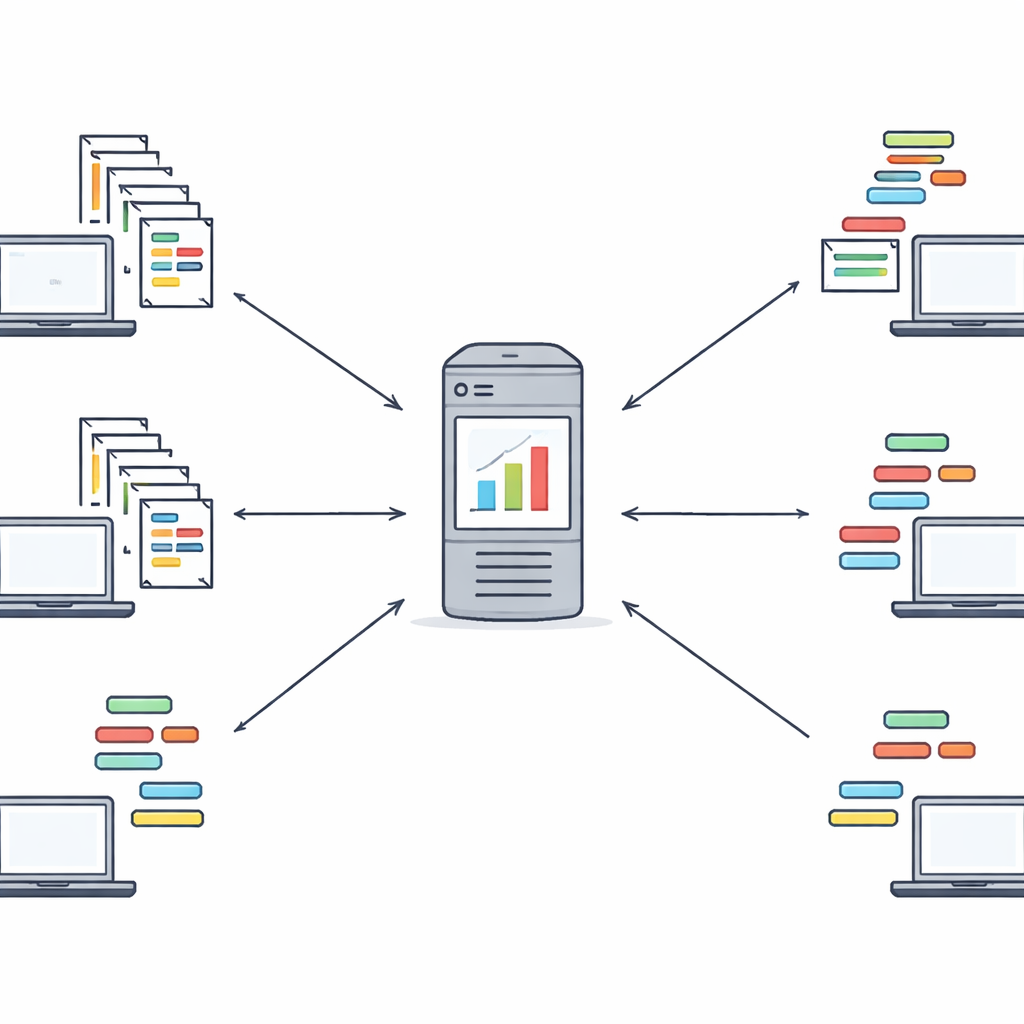
Uczenie struktury bez oglądania danych
Proponowane ramy, nazwane Fed‑MSMCGWO, działają w ustawieniu uczenia federacyjnego: każde urządzenie-klient, takie jak szpital czy serwis informacyjny, zachowuje surowe teksty i etykiety lokalnie. W pierwszym etapie metoda buduje rodzaj mapy — manifoldu — pokazującej, jak dokumenty są do siebie podobne i jak ich etykiety współwystępują. Łączy pobliskie dokumenty i powiązane etykiety w grafy, a następnie uczy wag cech, które respektują te struktury. Specjalne reguły skąpości zachęcają do jednoczesnego wygaszania całych cech nieprzydatnych dla wielu etykiet, pozostawiając szczuplejszą reprezentację, która nadal oddaje podstawowe relacje między tekstami a ich znacznikami.
Dopasowanie inspirowane naturą
Po tym manifoldowym przycięciu drugi etap precyzuje pozostałe wagi cech za pomocą biologicznie inspirowanej strategii poszukiwań wzorowanej na watahach szarych wilków. Kandydackie podzbiory cech traktowane są jak wilki eksplorujące krajobraz możliwych rozwiązań. Organizowane są w trzy współdziałające grupy, które równoważą ostrożne wykorzystywanie dobrych częściowych rozwiązań z szeroką eksploracją nowych możliwości. Poprzez powtarzane aktualizowanie pozycji zgodnie z najlepszymi członkami watahy, te wirtualne wilki koncentrują się na kombinacjach cech, które dalej poprawiają jakość etykietowania przy zachowaniu skąpości.
Współpraca przy zachowaniu prywatności
Gdy każdy klient wykona dwustopniową optymalizację lokalnie, wysyła do serwera centralnego jedynie swoje wagi cech i indeksy wybranych cech — nie surowe dokumenty ani etykiety. Serwer łączy te wagi, nadając większy wpływ klientom z większymi zbiorami danych, aby utworzyć globalny obraz najważniejszych cech. Następnie wysyła ten globalny wektor wag z powrotem do wszystkich klientów, którzy używają go do kolejnej rundy lokalnego dopracowania. Kilka takich rund zwykle wystarcza, by osiągnąć stabilny wspólny zestaw cech. Ta pętla tworzy proces uczenia się oparty na współpracy, w którym instytucje korzystają z doświadczeń innych, nie udostępniając nigdy swoich surowych danych tekstowych. Autorzy omawiają także, jak tę konstrukcję można w przyszłości połączyć z silniejszymi narzędziami kryptograficznymi.
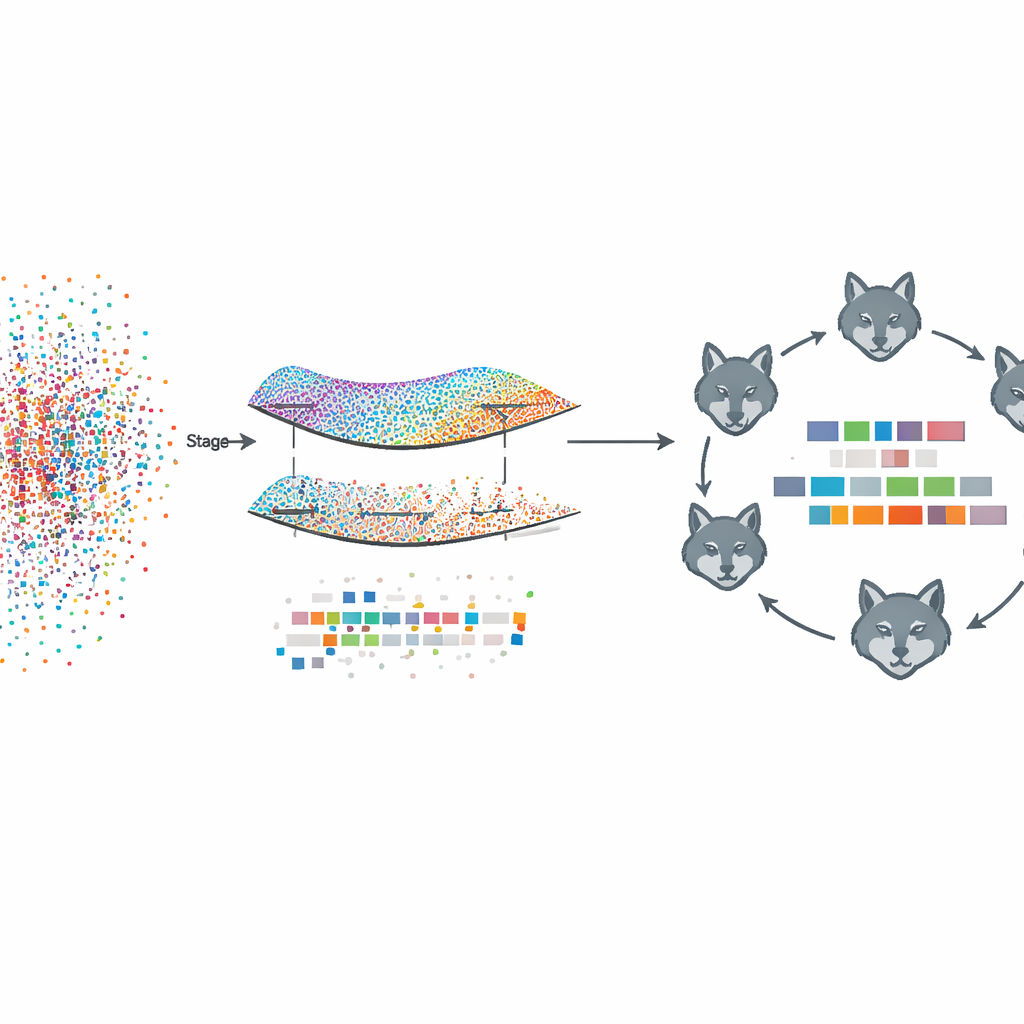
Dowody korzyści w praktyce
Aby przetestować pomysł, badacze przeprowadzili eksperymenty na ośmiu publicznych zbiorach danych do zadań tekstu wieloetykietowego z domen takich jak edukacja, zdrowie, sztuka i nauka. Porównali swoją metodę zarówno z klasycznymi podejściami scentralizowanymi zakładającymi skonsolidowanie danych, jak i z nowszymi federacyjnymi schematami selekcji cech. W szeregu standardowych miar wydajności dla zadań wieloetykietowych — w tym dokładności w rankingu poprawnych etykiet oraz częstości pominięć czy błędnych przypisań — nowe ramy konsekwentnie wypadały tak samo dobrze lub lepiej niż alternatywy, często osiągając wysoką dokładność przy zaskakująco niewielkiej liczbie wybranych cech. Testy statystyczne potwierdziły, że te poprawy nie były przypadkowe, a badania ablacyjne wykazały, że zarówno modelowanie manifoldu, jak i optymalizacja szarych wilków były kluczowymi elementami ogólnej konstrukcji.
Co to oznacza na przyszłość
Mówiąc prosto, praca pokazuje, że można przyciąć ogromne reprezentacje tekstu, uwzględnić złożone relacje między wieloma etykietami i współpracować między wieloma posiadaczami danych — wszystko przy zachowaniu wrażliwych dokumentów na miejscu. Łącząc strukturalne, geometryczne wniknięcie z naturą inspirowaną strategią poszukiwań, Fed‑MSMCGWO oferuje praktyczny przepis na budowę szybszych, dokładniejszych i bardziej świadomych prywatności systemów tagowania tekstu. Autorzy zakładają rozszerzenie podejścia poza zwykły tekst na bogatsze typy danych oraz połączenie go z silniejszym szyfrowaniem, torując drogę do współpracującej AI, która może uczyć się z wielu źródeł, nie ujawniając ich zawartości.
Cytowanie: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
Słowa kluczowe: uczenie federacyjne, selekcja cech, klasyfikacja tekstu wieloetykietowego, AI chroniące prywatność, optymalizacja metaheurystyczna