Clear Sky Science · pt
Seleção de características textuais multi-rótulo federada via modelagem esparsa consciente da variedade e otimização cooperativa do lobo cinzento
Por que classificar texto de forma mais inteligente importa
Todos os dias, hospitais, redações e redes sociais geram oceanos de texto que precisam ser rotulados com vários tópicos sobrepostos ao mesmo tempo — pense em um relatório médico marcado com várias doenças, tratamentos e fatores de risco. Essa multi-etiquetagem ajuda em buscas, recomendações e suporte à decisão, mas também sobrecarrega os computadores com enormes listas de palavras e expressões possíveis. O artigo apresenta uma nova maneira de selecionar apenas os sinais textuais mais úteis mantendo os dados das pessoas em seus próprios dispositivos, com o objetivo de tornar esses sistemas mais rápidos e mais privados.
Cortando o ruído
Em problemas de texto com múltiplas etiquetas, cada documento pode pertencer a várias categorias, e essas categorias frequentemente se relacionam: um artigo sobre ciência climática também pode tratar de políticas e economia. Ao mesmo tempo, representações textuais modernas — como vocabulários extensos ou embeddings densos — contêm milhares de sinais potenciais, muitos dos quais são redundantes ou irrelevantes. Esse problema de “muitas características” desacelera o treinamento, estimula overfitting e enfraquece as previsões. Os autores focam na seleção de características, a tarefa de encontrar um subconjunto compacto de características textuais informativas, mas fazem isso em um cenário onde os dados estão espalhados por muitos dispositivos e não podem ser centralizados num servidor.
Aprendendo a estrutura sem ver os dados
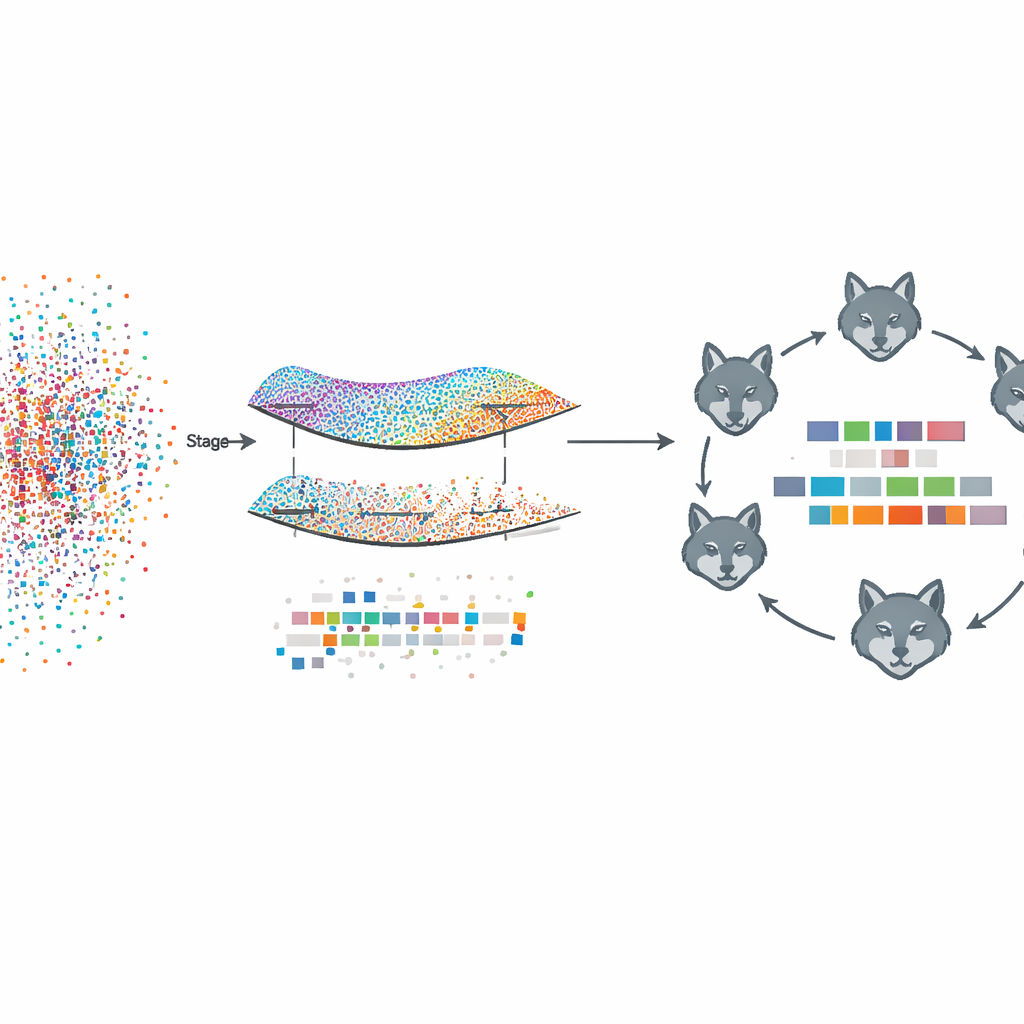
O framework proposto, chamado Fed‑MSMCGWO, opera em um arranjo de aprendizado federado: cada cliente, como um hospital ou site de notícias, mantém seus textos brutos e rótulos localmente. Na primeira fase, o método constrói uma espécie de mapa — ou variedade (manifold) — de como os documentos se assemelham entre si e como seus rótulos tendem a coocorrer. Ele conecta documentos próximos e rótulos relacionados em grafos, e então aprende pesos de características que respeitam essas estruturas. Uma regra especial de esparsidade incentiva que características inteiras que não ajudam across labels desapareçam em conjunto, deixando uma representação mais enxuta que ainda captura as relações subjacentes entre textos e suas etiquetas.
Ajuste fino inspirado na natureza
Após essa poda baseada na variedade, a segunda fase aprofunda-se para refinar os pesos das características remanescentes usando uma estratégia de busca bio-inspirada modelada em matilhas de lobos cinzentos. Subconjuntos candidatos de características são tratados como lobos explorando uma paisagem de soluções possíveis. Eles são organizados em três grupos cooperativos que equilibram a exploração cuidadosa de boas soluções parciais com uma ampla busca por novas opções. Ao atualizar repetidamente suas posições de acordo com os membros da matilha com melhor desempenho, esses lobos virtuais convergem para combinações de características que melhoram ainda mais a performance de rotulagem mantendo a esparsidade.
Cooperando sem perder a privacidade
Uma vez que cada cliente executou localmente a otimização em duas etapas, ele envia apenas seus pesos de características e os índices das características selecionadas para um servidor central — não os documentos ou rótulos originais. O servidor combina esses pesos, dando mais influência a clientes com conjuntos de dados maiores, para formar uma visão global de quais características são mais importantes. Em seguida, envia esse vetor de pesos global de volta a todos os clientes, que o usam para orientar outra rodada de refinamento local. Algumas poucas dessas rodadas geralmente são suficientes para alcançar um conjunto de características compartilhado e estável. Esse ciclo cria um processo de aprendizado colaborativo no qual instituições se beneficiam da experiência umas das outras sem jamais compartilhar seus dados textuais brutos. Os autores também discutem como esse desenho pode ser combinado com ferramentas criptográficas mais fortes em trabalhos futuros.
Comprovando os ganhos na prática
Para testar a ideia, os pesquisadores realizaram experimentos em oito conjuntos de dados públicos de texto multi-rótulo cobrindo domínios como educação, saúde, artes e ciência. Eles compararam seu método tanto com abordagens centralizadas clássicas que assumem que todos os dados podem ser reunidos quanto com esquemas federados mais recentes de seleção de características. Em várias medidas padrão de desempenho multi-rótulo — incluindo quão precisamente as etiquetas corretas são ranqueadas e com que frequência rótulos são omitidos ou atribuídos de forma incorreta — o novo framework consistentemente apresentou desempenho tão bom quanto ou melhor que as alternativas, frequentemente atingindo alta acurácia com surpreendentemente poucas características selecionadas. Testes estatísticos confirmaram que essas melhorias não se deveram ao acaso, e estudos de ablação mostraram que tanto a modelagem da variedade quanto a otimização pelo lobo cinzento foram peças cruciais do projeto geral.
O que isso significa para o futuro
Em termos simples, este trabalho mostra que é possível reduzir representações textuais massivas, respeitar relações complexas entre múltiplas etiquetas e colaborar entre muitos detentores de dados — tudo isso mantendo documentos sensíveis localmente. Ao combinar insight geométrico estruturado com uma estratégia de busca inspirada na natureza, o Fed‑MSMCGWO oferece uma receita prática para construir sistemas de rotulagem de texto mais rápidos, mais precisos e mais conscientes da privacidade. Os autores imaginam estender essa abordagem além do texto simples para tipos de dados mais ricos e emparelhá-la com criptografia mais forte, abrindo caminho para uma IA colaborativa que aprenda a partir de muitas fontes sem expor o conteúdo dessas fontes.
Citação: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
Palavras-chave: aprendizado federado, seleção de características, classificação de texto multi-rótulo, IA preservadora de privacidade, otimização metaheurística