Clear Sky Science · it
Selezione di feature testuali multi-etichetta federata tramite modellazione sparsa consapevole della varietà e ottimizzazione cooperativa grey wolf
Perché ordinare il testo in modo più intelligente conta
Ogni giorno ospedali, redazioni e reti sociali generano oceani di testo che devono essere etichettati con molti argomenti sovrapposti simultaneamente—pensi a un referto medico annotato con più malattie, trattamenti e fattori di rischio. Questa multi-etichettatura facilita la ricerca, le raccomandazioni e il supporto alle decisioni, ma appesantisce anche i sistemi con lunghissime liste di parole e frasi possibili. L’articolo propone un nuovo modo per selezionare soltanto gli indizi testuali più utili mantenendo i dati delle persone sui loro dispositivi, con l’obiettivo di rendere tali sistemi sia più veloci sia più rispettosi della privacy.
Tagliare il rumore
Nei problemi testuali multi-etichetta, ogni documento può appartenere a più categorie, e queste categorie sono spesso correlate: un articolo sulla scienza climatica può anche trattare politica ed economia. Allo stesso tempo, le rappresentazioni testuali moderne—come vocabolari estesi o embedding densi—contengono migliaia di segnali potenziali, molti dei quali ridondanti o irrilevanti. Questo problema del “troppi attributi” rallenta l’addestramento, favorisce l’overfitting e indebolisce le previsioni. Gli autori si concentrano sulla selezione di feature, il compito di trovare un sottoinsieme compatto di feature testuali informative, ma lo fanno in un contesto in cui i dati sono distribuiti su molti dispositivi e non possono essere aggregati su un server centrale.
Apprendere la struttura senza vedere i dati
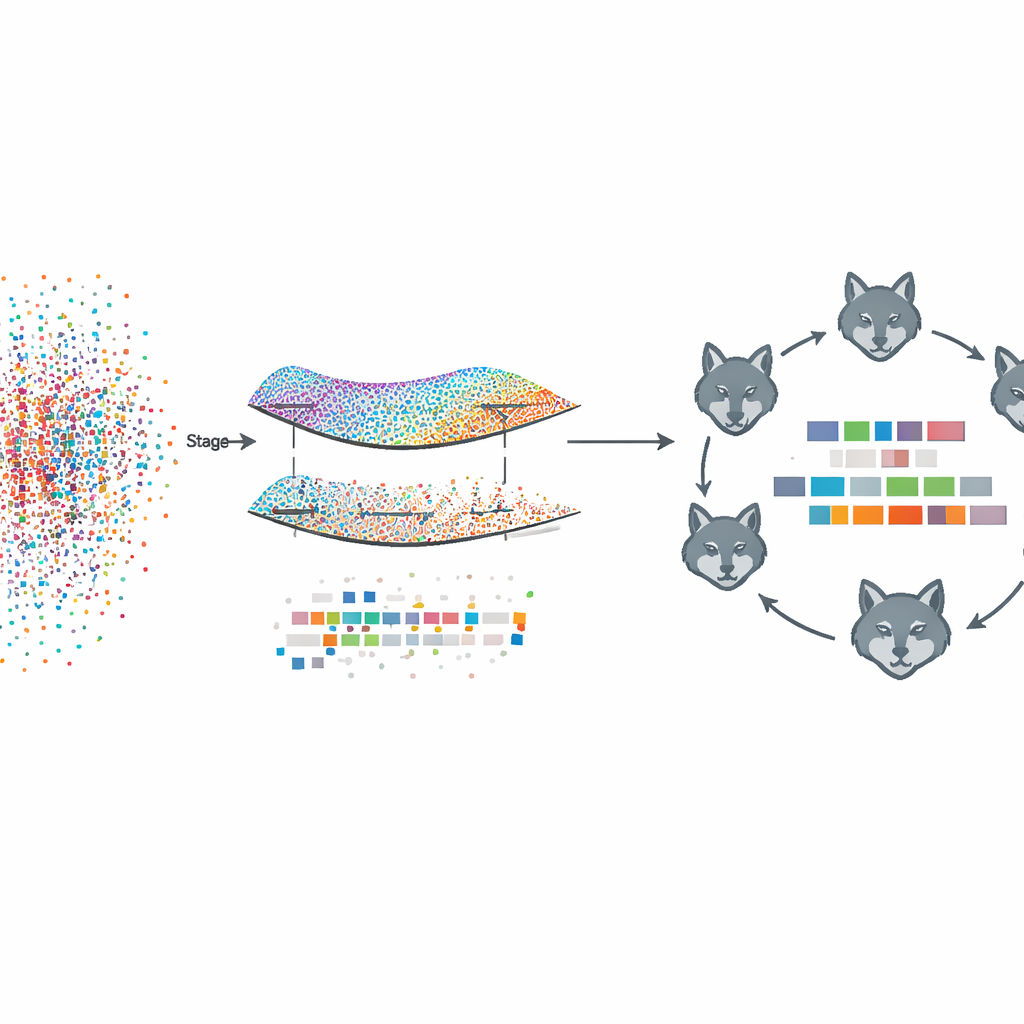
Il framework proposto, chiamato Fed‑MSMCGWO, opera in uno schema di apprendimento federato: ogni client, come un ospedale o un sito di informazione, conserva localmente i testi grezzi e le etichette. Nella prima fase, il metodo costruisce una sorta di mappa—o varietà—di come i documenti si somigliano e di come le loro etichette tendono a co-occorre. Collega documenti vicini e etichette correlate in grafi, quindi apprende pesi delle feature che rispettano queste strutture. Una regola di sparsità speciale incoraggia l’eliminazione collettiva delle feature inutili per più etichette, lasciando una rappresentazione snella che conserva comunque le relazioni sottostanti tra testi e tag.
Rifinitura ispirata alla natura
Dopo questo potatura basata sulla varietà, la seconda fase approfondisce la rifinitura dei pesi delle feature rimanenti usando una strategia di ricerca bio-ispirata modellata sui branchi di lupi grigi. Sottosets candidati di feature vengono trattati come lupi che esplorano un paesaggio di soluzioni possibili. Sono organizzati in tre gruppi cooperanti che bilanciano l’exploitazione prudente di buone soluzioni parziali con l’ampia esplorazione di nuove regioni. Aggiornando ripetutamente le loro posizioni in base ai membri del branco con prestazioni migliori, questi lupi virtuali convergono su combinazioni di feature che migliorano ulteriormente le prestazioni di etichettatura mantenendo la parsimonia.
Collaborare restando privati
Una volta che ogni client ha eseguito le due fasi di ottimizzazione localmente, invia al server centrale solo i pesi delle feature e gli indici delle feature selezionate—non i documenti o le etichette originali. Il server combina questi pesi, dando maggiore influenza ai client con dataset più grandi, per formare una visione globale delle feature più rilevanti. Quindi invia questo vettore di pesi globali a tutti i client, che lo usano per guidare un altro giro di rifinitura locale. Poche iterazioni di questo scambio sono di solito sufficienti per raggiungere un insieme di feature condiviso e stabile. Questo ciclo crea un processo di apprendimento collaborativo in cui le istituzioni beneficiano dell’esperienza reciproca senza mai condividere i testi grezzi. Gli autori discutono anche di come questo disegno possa essere combinato con strumenti crittografici più forti in lavori futuri.
Dimostrare i guadagni in pratica
Per mettere alla prova l’idea, i ricercatori hanno eseguito esperimenti su otto dataset testuali multi-etichetta pubblici coprendo domini come istruzione, salute, arti e scienza. Hanno confrontato il loro metodo sia con approcci centralizzati classici che assumono la possibilità di aggregare tutti i dati, sia con schemi federati più recenti per la selezione di feature. Su diverse misure standard di performance multi-etichetta—inclusi il posizionamento accurato delle etichette corrette e la frequenza con cui le etichette vengono dimenticate o assegnate in modo errato—il nuovo framework ha costantemente ottenuto risultati pari o superiori alle alternative, spesso raggiungendo elevata accuratezza con un numero sorprendentemente ridotto di feature selezionate. Test statistici hanno confermato che questi miglioramenti non erano dovuti al caso, e studi di ablazione hanno mostrato che sia la modellazione della varietà sia l’ottimizzazione grey-wolf sono componenti cruciali del progetto complessivo.
Cosa significa per il futuro
In termini pratici, questo lavoro dimostra che è possibile ridurre le rappresentazioni testuali massive, rispettare relazioni complesse tra più tag e collaborare tra molti detentori di dati—il tutto mantenendo i documenti sensibili a casa. Combinando intuizioni geometriche strutturate con una strategia di ricerca ispirata alla natura, Fed‑MSMCGWO offre una ricetta pratica per costruire sistemi di etichettatura testuale più veloci, più accurati e più attenti alla privacy. Gli autori prevedono di estendere questo approccio oltre il testo semplice a tipi di dati più ricchi e di abbinarlo a crittografie più robuste, aprendo la strada a un’IA collaborativa che può apprendere da molte fonti senza esporre ciò che quelle fonti contengono realmente.
Citazione: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
Parole chiave: apprendimento federato, selezione di feature, classificazione testuale multi-etichetta, IA che preserva la privacy, ottimizzazione metaeuristica