Clear Sky Science · es
Selección federada de características de texto multilabel mediante modelado disperso consciente de la variedad y optimización cooperativa de lobo gris
Por qué importa ordenar el texto de forma más inteligente
Cada día, hospitales, redacciones y redes sociales generan océanos de texto que deben etiquetarse con múltiples temas superpuestos a la vez; piense en un informe médico etiquetado con varias enfermedades, tratamientos y factores de riesgo. Este etiquetado múltiple facilita la búsqueda, las recomendaciones y el apoyo a la toma de decisiones, pero también sobrecarga a los sistemas con largas listas de palabras y frases posibles. El artículo presenta una nueva forma de seleccionar solo las señales textuales más útiles mientras se mantiene la información de las personas en sus propios dispositivos, con el objetivo de que esos sistemas sean a la vez más rápidos y más respetuosos con la privacidad.
Cortando el ruido
En problemas de texto con múltiples etiquetas, cada documento puede pertenecer a varias categorías, y esas categorías suelen estar relacionadas: un artículo sobre ciencia climática también puede abordar política y economía. Al mismo tiempo, las representaciones modernas de texto —como vocabularios extensos o incrustaciones densas— contienen miles de señales potenciales, muchas de las cuales son redundantes o irrelevantes. Este problema de “demasiadas características” enlentece el entrenamiento, favorece el sobreajuste y debilita las predicciones. Los autores se centran en la selección de características, la tarea de encontrar un subconjunto compacto de características textuales informativas, pero lo hacen en un escenario donde los datos están dispersos entre muchos dispositivos y no se pueden agrupar en un servidor central.
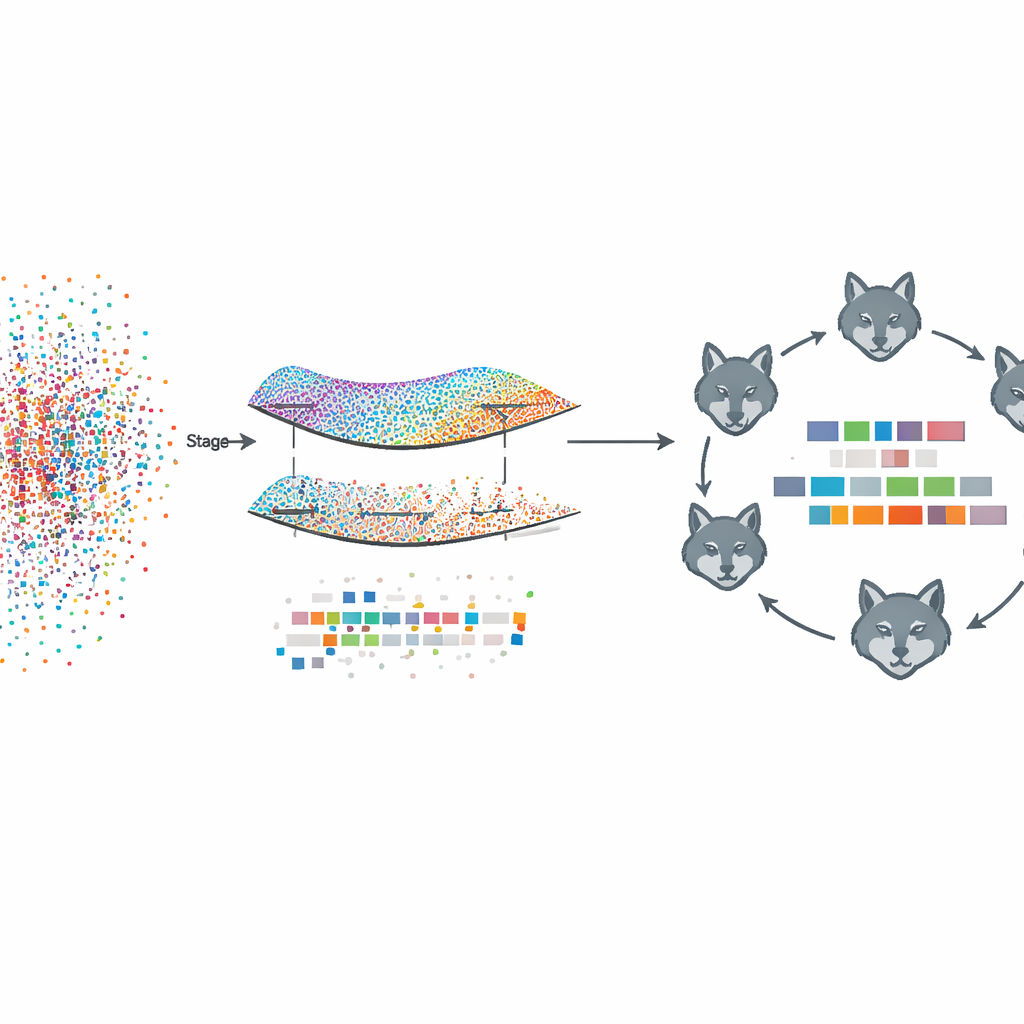
Aprender la estructura sin ver los datos
El marco propuesto, denominado Fed‑MSMCGWO, funciona bajo un esquema de aprendizaje federado: cada cliente, como un hospital o un medio de comunicación, conserva sus textos y etiquetas de forma local. En la primera fase, el método construye una especie de mapa —o variedad— de cómo los documentos se parecen entre sí y cómo tienden a coocurrir sus etiquetas. Conecta documentos cercanos y etiquetas relacionadas en grafos, y luego aprende ponderaciones de características que respetan estas estructuras. Una regla especial de esparcimiento (sparsity) incentiva que las características que no son útiles a través de varias etiquetas desaparezcan de forma conjunta, dejando una representación más ligera que aún captura las relaciones subyacentes entre textos y etiquetado.
Refinamiento inspirado en la naturaleza
Tras esta poda basada en la variedad, la segunda fase se centra en refinar las ponderaciones de las características restantes mediante una estrategia de búsqueda bioinspirada modelada en manadas de lobos grises. Los subconjuntos candidatos de características se tratan como lobos que exploran un paisaje de soluciones posibles. Se organizan en tres grupos cooperativos que equilibran la explotación cautelosa de buenas soluciones parciales con una amplia exploración de nuevas alternativas. Al actualizar repetidamente sus posiciones según los miembros de la manada con mejor rendimiento, estos lobos virtuales convergen hacia combinaciones de características que mejoran aún más el etiquetado manteniendo la esparcitud.
Colaborar manteniendo la privacidad
Una vez que cada cliente ha ejecutado localmente la optimización en dos etapas, envía solo sus ponderaciones de características y los índices de las características seleccionadas a un servidor central —no los documentos ni las etiquetas originales. El servidor combina estas ponderaciones, dando más influencia a los clientes con conjuntos de datos mayores, para formar una visión global de qué características importan más. A continuación, envía este vector de ponderaciones globales de vuelta a todos los clientes, que lo usan para guiar otra ronda de refinamiento local. Unas pocas rondas suelen ser suficientes para alcanzar un conjunto de características compartido y estable. Este bucle crea un proceso de aprendizaje colaborativo en el que las instituciones se benefician de la experiencia mutua sin llegar a compartir sus datos en bruto. Los autores también discuten cómo este diseño puede combinarse con herramientas criptográficas más robustas en trabajos futuros.
Demostrando las mejoras en la práctica
Para evaluar su idea, los investigadores realizaron experimentos en ocho conjuntos de datos públicos de texto multilabel que cubren dominios como educación, salud, artes y ciencia. Compararon su método tanto con enfoques centralizados clásicos que asumen que todos los datos pueden agruparse como con esquemas federados más recientes de selección de características. En varias medidas estándar de rendimiento multilabel —incluida la precisión en la ordenación de etiquetas correctas y la frecuencia con que las etiquetas se pierden o asignan erróneamente—, el nuevo marco rindió de manera consistente igual o superior a las alternativas, alcanzando a menudo alta precisión con sorprendentemente pocas características seleccionadas. Pruebas estadísticas confirmaron que estas mejoras no se debían al azar, y estudios de ablación mostraron que tanto el modelado de la variedad como la optimización basada en el lobo gris eran componentes cruciales del diseño global.
Qué significa esto de cara al futuro
En términos sencillos, este trabajo demuestra que es posible reducir representaciones textuales masivas, respetar relaciones complejas entre múltiples etiquetas y colaborar entre muchos poseedores de datos —todo ello manteniendo los documentos sensibles en sus orígenes. Al combinar un enfoque geométrico estructurado con una estrategia de búsqueda inspirada en la naturaleza, Fed‑MSMCGWO ofrece una receta práctica para construir sistemas de etiquetado de texto más rápidos, precisos y atentos a la privacidad. Los autores prevén extender este enfoque más allá del texto plano a tipos de datos más ricos y emparejarlo con cifrado más fuerte, abriendo camino a una IA colaborativa capaz de aprender de muchas fuentes sin exponer lo que esas fuentes contienen realmente.
Cita: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
Palabras clave: aprendizaje federado, selección de características, clasificación de texto multilabel, IA que preserva la privacidad, optimización metaheurística