Clear Sky Science · sv
Federerad flermärkningsbaserad textfunktionsurval via manifold‑medveten gles modellering och samverkande gråvargoptimering
Varför smartare textsortering spelar roll
Varje dag genererar sjukhus, redaktioner och sociala nätverk enorma mängder text som måste märkas med många överlappande ämnen samtidigt — tänk en medicinsk rapport som får etiketter för flera sjukdomar, behandlingar och riskfaktorer. Denna flermärkning förbättrar sökningar, rekommendationer och beslutsstöd, men överbelastar också systemen med väldigt långa listor av möjliga ord och fraser. Artikeln presenterar ett nytt sätt att plocka ut endast de mest användbara textsignalerna samtidigt som människors data stannar kvar på deras egna enheter, med målet att göra sådana system både snabbare och mer integritetsvänliga.
Skära igenom bruset
I flermärkta textproblem kan varje dokument tillhöra flera kategorier, och dessa kategorier är ofta relaterade: en artikel om klimavetenskap kan också beröra politik och ekonomi. Samtidigt innehåller moderna textrepresentationer — såsom stora vokabulärer eller täta inbäddningar — tusentals potentiella signaler, många av dem redundanta eller irrelevanta. Detta problem med ”för många funktioner” saktar ner träningen, uppmuntrar överanpassning och försvagar prognoserna. Författarna fokuserar på funktionsurval, uppgiften att hitta en kompakt delmängd av informativa textfunktioner, men gör det i en miljö där data är spridda över många enheter och inte kan samlas på en central server.
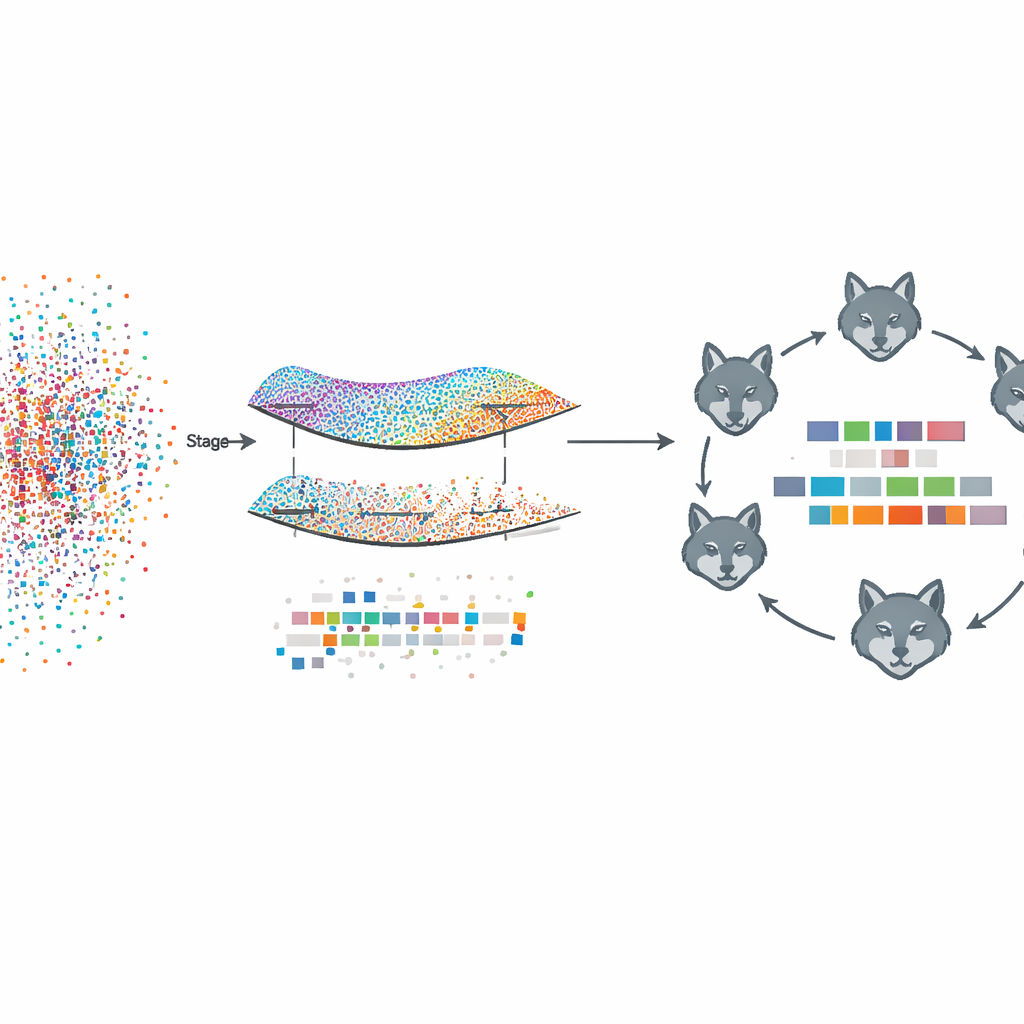
Lära struktur utan att se rådata
Det föreslagna ramverket, kallat Fed‑MSMCGWO, fungerar under en federerad inlärningsuppställning: varje klientenhet, såsom ett sjukhus eller en nyhetssajt, behåller sin råtext och sina etiketter lokalt. I första steget bygger metoden en slags karta — eller manifold — av hur dokument liknar varandra och hur deras etiketter tenderar att samexistera. Den kopplar närliggande dokument och relaterade etiketter i grafer och lär sig därefter funktionsvikter som respekterar dessa strukturer. En särskild gleshetsregel uppmuntrar hela funktioner som är oanvändbara över etiketter att försvinna tillsammans, vilket lämnar en mer slimmad representation som ändå fångar de underliggande relationerna mellan texter och deras etiketter.
Naturinspirerad finjustering
Efter denna manifold‑baserade beskärning zoomar det andra steget in för att förfina återstående funktionsvikter med en bioinspirerad sökstrategi modellerad på gråvargspack. Kandidatdelmängder av funktioner behandlas som vargar som utforskar ett landskap av möjliga lösningar. De organiseras i tre samarbetande grupper som balanserar försiktig utnyttjning av lovande partiallösningar med bred utforskning av nya sådana. Genom att upprepade gånger uppdatera sina positioner enligt de bäst presterande packmedlemmarna, koncentrerar dessa virtuella vargar sig på funktionskombinationer som ytterligare förbättrar märkningens prestanda samtidigt som glesheten bevaras.
Samarbeta samtidigt som man bevarar integriteten
När varje klient har kört den tvåstegsoptimering lokalt skickar den endast sina funktionsvikter och valda funktionsindex till en central server — inte de ursprungliga dokumenten eller etiketterna. Servern kombinerar dessa vikter och ger större inflytande åt klienter med större datamängder för att bilda en global uppfattning om vilka funktioner som är viktigast. Den skickar sedan denna globala viktvektor tillbaka till alla klienter, som använder den för att styra en ny runda lokal förfining. Några sådana rundor räcker oftast för att nå en stabil delad funktionsuppsättning. Denna slinga skapar en samarbetsinlärningsprocess där institutioner drar nytta av varandras erfarenheter utan att någonsin dela sina råa textdata. Författarna diskuterar också hur denna design kan kombineras med starkare kryptografiska verktyg i framtida arbete.
Bevisa vinsterna i praktiken
För att pröva sin idé körde forskarna experiment på åtta publika flermärkta textdatamängder som täcker domäner som utbildning, hälsa, konst och vetenskap. De jämförde sin metod med både klassiska centraliserade angreppssätt som förutsätter att all data kan samlas och nyare federerade funktionsurvalsscheman. Över flera standardmått för flermärkningsprestanda — inklusive hur korrekt de rätta etiketterna rankas och hur ofta etiketter missas eller felaktigt tilldelas — presterade det nya ramverket konsekvent lika bra eller bättre än alternativen, ofta med stark noggrannhet med förvånansvärt få valda funktioner. Statistiska tester bekräftade att dessa förbättringar inte berodde på slumpen, och ablationsstudier visade att både manifoldmodelleringen och gråvargsoptimeringen var avgörande delar av helhetsdesignen.
Vad detta betyder framöver
I korthet visar detta arbete att det är möjligt att krympa massiva textrepresentationer, respektera komplexa relationer mellan flera etiketter och samarbeta över många datainnehavare — allt medan känsliga dokument stannar hemma. Genom att kombinera strukturerad geometrisk insikt med en naturinspirerad sökstrategi erbjuder Fed‑MSMCGWO ett praktiskt recept för att bygga snabbare, mer precisa och mer integritetsmedvetna system för textmärkning. Författarna föreställer sig att man kan utvidga detta till mer komplexa datatyper och para ihop det med starkare kryptering, vilket banar väg för kollaborativ AI som kan lära från många källor utan att avslöja vad dessa källor faktiskt innehåller.
Citering: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
Nyckelord: federerat lärande, funktionsurval, flermärkningsyta textklassificering, sekretessbevarande AI, metaheuristisk optimering