Clear Sky Science · en
Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization
Why smarter text sorting matters
Every day, hospitals, newsrooms, and social networks generate oceans of text that must be tagged with many overlapping topics at once—think of a medical report labeled with several diseases, treatments, and risk factors. This multi-tagging helps search, recommendations, and decision support, but it also overloads computers with huge lists of possible words and phrases. The paper introduces a new way to pick out only the most useful text cues while keeping people’s data on their own devices, aiming to make such systems both faster and more private.
Cutting through the noise
In multi-tag text problems, each document may belong to several categories, and those categories are often related: an article about climate science can also touch on policy and economics. At the same time, modern text representations—such as long vocabularies or dense embeddings—contain thousands of potential signals, many of which are redundant or irrelevant. This “too many features” problem slows training, encourages overfitting, and weakens predictions. The authors focus on feature selection, the task of finding a compact subset of informative text features, but they do so in a setting where data are scattered across many devices and cannot be pooled on a central server.
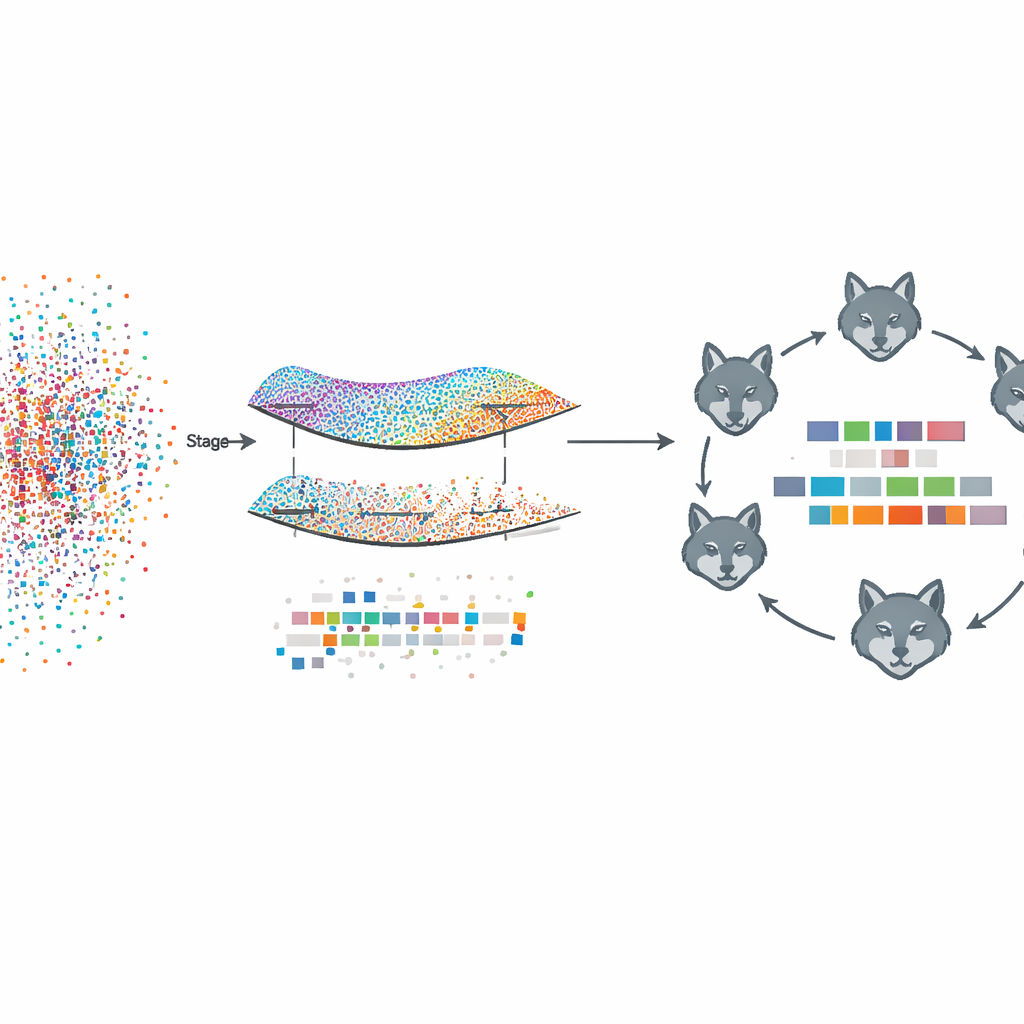
Learning structure without seeing the data
The proposed framework, called Fed‑MSMCGWO, works under a federated learning setup: each client device, such as a hospital or news site, keeps its raw text and labels locally. In the first stage, the method builds a kind of map—or manifold—of how documents resemble one another and how their labels tend to co‑occur. It links nearby documents and related labels into graphs, then learns feature weights that respect these structures. A special sparsity rule encourages entire features that are unhelpful across labels to fade out together, leaving a leaner representation that still captures the underlying relationships between texts and their tags.
Nature-inspired fine-tuning
After this manifold-based pruning, the second stage zooms in to refine the remaining feature weights using a bio-inspired search strategy modeled on grey wolf packs. Candidate feature subsets are treated like wolves exploring a landscape of possible solutions. They are organized into three cooperating groups that balance cautious exploitation of good partial solutions with wide exploration of new ones. By repeatedly updating their positions according to the best-performing pack members, these virtual wolves home in on feature combinations that further improve tagging performance while staying sparse.
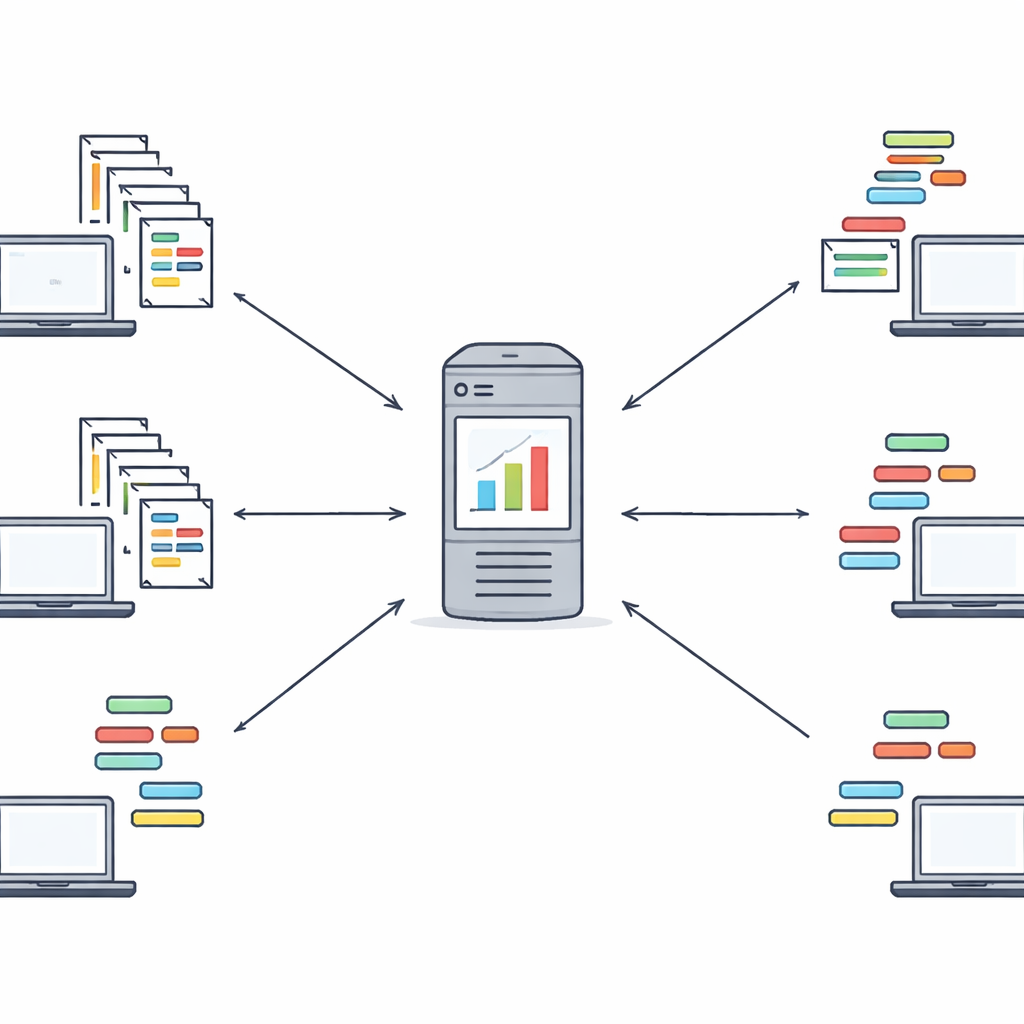
Collaborating while staying private
Once each client has run the two-stage optimization locally, it sends only its feature weights and chosen feature indices to a central server—not the original documents or labels. The server combines these weights, giving more influence to clients with larger datasets, to form a global view of which features matter most. It then sends this global weight vector back to all clients, which use it to guide another round of local refinement. A few such rounds are usually enough to reach a stable shared feature set. This loop creates a collaborative learning process in which institutions benefit from one another’s experience without ever sharing their raw text data. The authors also discuss how this design can be combined with stronger cryptographic tools in future work.
Proving the gains in practice
To test their idea, the researchers ran experiments on eight public multi-label text datasets covering domains such as education, health, arts, and science. They compared their method with both classic centralized approaches that assume all data can be pooled and newer federated feature-selection schemes. Across several standard measures of multi-label performance—including how accurately the correct tags are ranked and how often labels are missed or misassigned—the new framework consistently performed as well as or better than the alternatives, often reaching strong accuracy with surprisingly few selected features. Statistical tests confirmed that these improvements were not due to chance, and ablation studies showed that both the manifold modeling and the grey-wolf optimization were crucial pieces of the overall design.
What this means going forward
In plain terms, this work shows that it is possible to trim down massive text representations, respect complex relationships among multiple tags, and collaborate across many data holders—all while keeping sensitive documents at home. By combining structured geometric insight with a nature-inspired search strategy, Fed‑MSMCGWO offers a practical recipe for building faster, more accurate, and more privacy-aware text tagging systems. The authors envision extending this approach beyond plain text to richer data types and pairing it with stronger encryption, paving the way for collaborative AI that can learn from many sources without exposing what those sources actually contain.
Citation: Zheng, Y., Ye, Z., Zhang, S. et al. Federated multi-label text feature selection via manifold-aware sparse modeling and cooperative grey wolf optimization. Sci Rep 16, 11680 (2026). https://doi.org/10.1038/s41598-026-46223-4
Keywords: federated learning, feature selection, multi-label text classification, privacy-preserving AI, metaheuristic optimization