Clear Sky Science · tr
HiCoBERT: Pakistan hukuk karar bölümlerini çok seviyeli XAI içgörüleriyle segmentleme için hiyerarşik dönüştürücü tabanlı bir çerçeve
Mahkeme kararlarını parçalara ayırmanın önemi
Hakimler karar yazarken genellikle uzun, yoğun bir anlatı sunarlar: önce olayın arka planı, sonra gündeme alınan hususlar, ardından sayfalarca gerekçe ve sonunda hüküm. Avukatlar, vatandaşlar veya önemli bir bölümü bulmaya çalışan yazılımlar için bu metin duvarı bunaltıcı olabilir. Bu makale HiCoBERT’i tanıtıyor: Pakistan Yüksek Mahkemesi kararlarını otomatik olarak dört anlamlı bölüme—arka plan, hususlar, gerekçeler ve karar—ayıran yeni bir yapay zeka çerçevesi; böylece hukuki bilgiler daha kesin biçimde aranabilir, özetlenebilir ve analiz edilebilir.
Hukuki anlatıları net yapı taşlarına dönüştürmek
Yazarlar basit bir gözlemden yola çıkıyor: çoğu modern dil modeli bir belgeyi düz bir kelime akışı olarak okuyor ve kararların doğal olarak aşamalara ayrıldığını görmezden geliyor. Önceki araştırmalar bu iç yapıya—örneğin olgularla hukuki analizlerin ayrılmasına—saygı göstermenin özetleme ve sonucunu tahmin etme gibi görevleri iyileştirdiğini göstermişti. Bu fikir üzerine inşa ederek, ekip birçok mahkemenin gerçekte yazdığı biçime uyan pratik bir dört parçalı şablon tanımlıyor: dava özeti, mahkemenin karara bağlaması gereken noktalar, ayrıntılı gerekçeler ve nihai karar. Amaçları, başlıklar veya görsel ipuçları olmasa bile bir yapay zekâ sistemine bu yapıyı otomatik olarak geri kazandırmayı öğretmek.
Pakistan’ın en yüksek mahkemesinden yeni bir veri seti oluşturmak
Yöntemlerini eğitmek ve test etmek için yazarlar LeJA’yı derlediler: Pakistan Yüksek Mahkemesi kararlarından oluşan yeni bir veri seti. Dosya numaraları ve tarihler gibi meta veriler çıkarıldıktan sonra, hukuk uzmanları her kararı dört işlevsel bölüme göre etiketledi; bölümlerin sıralı, örtüşmeyen ve belgeler arasında tutarlı olmasına dikkat edildi. Mahkeme kararları standart yapay zekâ modellerinin tek seferde okuyabildiğinden çok daha uzun olduğundan, metinler yaklaşık 128 token’lık (yaklaşık birkaç cümle) daha küçük parçacıklara dinamik bir stratejiyle bölündü; bu strateji cümleleri bütün tutarken hesaplamayı da makul düzeyde tutuyor.
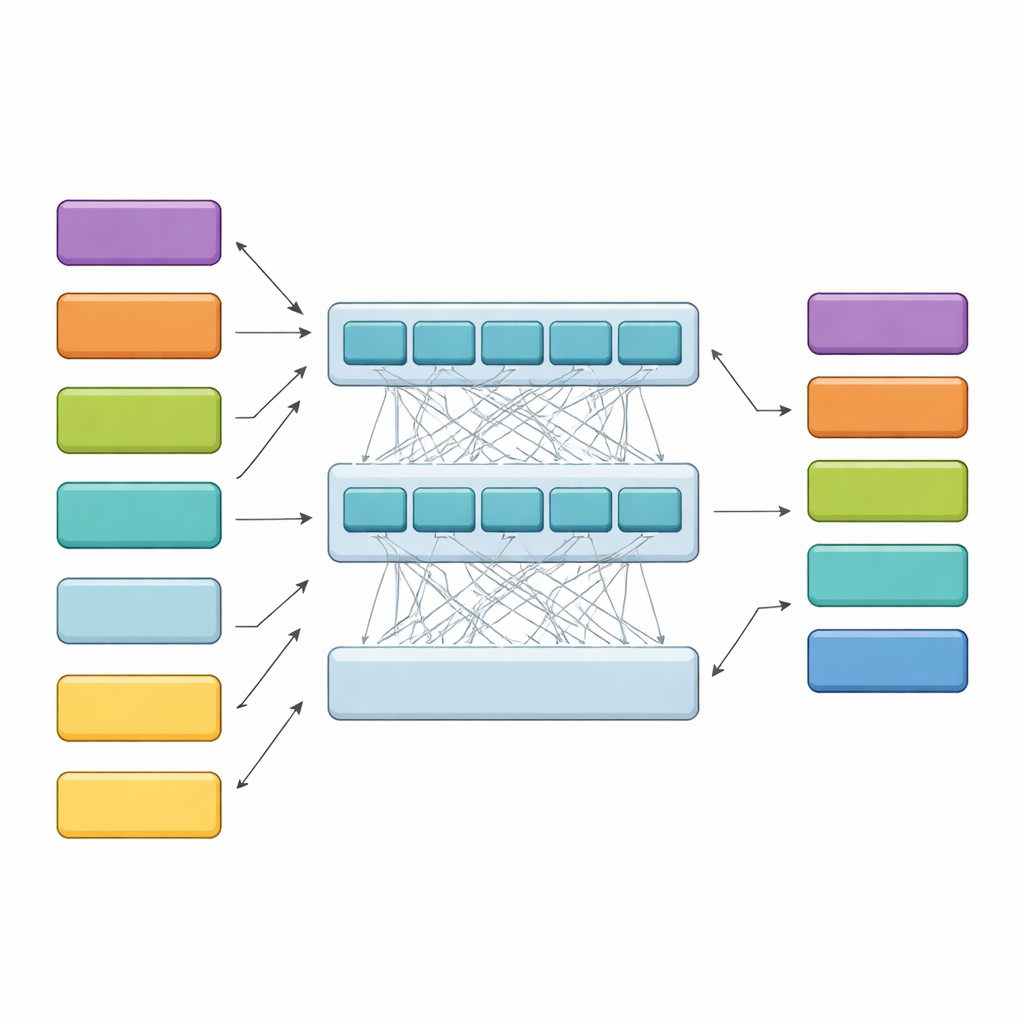
Hiyerarşik model uzun kararları nasıl okuyor
HiCoBERT her kararı iki aşamada ele alıyor. İlk olarak, her metin parçacığını mini-bir belge gibi değerlendiriyor ve yerel anlamı kavramak için hukuk alanına uyarlanmış bir BERT modeli (LegalBERT) kullanıyor. Bu işlem her parçacığın kompakt bir vektör özetiyle temsil edilmesini sağlıyor. İkinci aşamada ise bu özet dizisini ek bir Transformer ve çift yönlü bir tekrarlı ağ içine besliyor. Bu katmanlar modelin her parçacığı belgenin geri kalanıyla karşılaştırmasına izin veriyor; erken arka plan, ortadaki hususlar ve sonraki gerekçelerin birbirleriyle nasıl ilişkili olduğunu öğreniyor. Son olarak bir sınıflandırıcı, hem kendi içeriği hem de komşu parçacıkların etkisiyle her parçacığa dört işlevsel rolden birini atıyor.
Rakip modelleri geride bırakmak ve modelin gerekçesini denetlemek
LeJA veri seti üzerindeki testlerde HiCoBERT yaklaşık %80 doğruluk ve 0,70 makro-F1 skoruna ulaştı; Longformer, BigBird, LongT5 ve geleneksel bir sekans etiketleyiciyle eşleştirilmiş bir LegalBERT gibi güçlü alternatifleri geride bıraktı. Ayrıca GPT-4o, Gemini Pro ve DeepSeek-V3 gibi prompt ile çalıştırılan modern büyük dil modellerine kıyasla da özellikle dört bölümün tümünde dengeli performans gösterdiğinde olumlu bir performans sergiledi. Yazarlar daha sonra HiCoBERT’in karar verme süreçlerini açıklanabilir yapay zeka araçlarıyla inceledi. Token (kelime/parça) düzeyindeki analizler modelin arka planda olgusal ayrıntılara, hususlar bölümünde soru sorma ifadelerine, gerekçelerde hukuki atıflara ve argümantatif dile, kararda ise belirleyici ifadelere odaklandığını gösterdi. Segment düzeyindeki testler, özellikle karardan hemen önceki komşu parçaların bir bölümün nasıl etiketlendiğini güçlü şekilde etkilediğini ortaya koydu; bu sonuç bağlamın önemini doğruluyor.
Sınır aşan dayanıklılığı test etmek ve ileriye bakmak
Yöntemlerinin Pakistan dışına genellenip genellenemeyeceğini görmek için araştırmacılar HiCoBERT’i benzer retorik rollere sahip Hint kararlarından oluşan halka açık LegalSeg veri seti üzerinde değerlendirdi. Yeniden eğitim yapmadan model hâlâ makul bir performans gösterdi; özellikle temel gerekçe ve karar bölümlerinde başarılı oldu, ancak kısa ve belirsiz ifade edilen hususlarda daha fazla zorlandı. Bu, modelin genel olarak paylaşılan hukuki yazım kalıplarını yakaladığına işaret ederken, daha ince tespitlerin yerel yazım tarzına bağlı olabileceğini gösteriyor. Yazarlar ayrıca pratik sınırlamalara da dikkat çekiyor: sabit bir maksimum belge uzunluğu, gerekçe bölümüne doğru güçlü sınıf dengesizliği ve bölüm sınırlarında zaman zaman karışıklık; bunlar uyarlanabilir bağlam pencereleri ve sınır farkındalıklı dikkat gibi gelecekteki iyileştirmeleri motive ediyor.
Hukuki yapay zekânın günlük kullanımı için anlamı
Basitçe söylemek gerekirse çalışma, mahkeme kararlarını ayrım yapılmamış bir metin olarak değil, dikkatle sıralanmış anlatılar olarak ele almanın daha doğru ve yorumlanabilir yapay zekâ araçları verdiğini gösteriyor. HiCoBERT’in hiyerarşik tasarımı, uzun kararları avukatların ve hakimlerin davalara doğal olarak yaklaştığı şekilde anlamlı parçalara ayırabiliyor. Bu, olguları hızlıca ortaya çıkaran, hususları izole eden, gerekçeyi takip eden veya doğrudan karara atlayan sistemlerin inşasını kolaylaştırabilir. Bu tür modeller olgunlaşıp diğer mahkemelere ve dillere genişletildikçe, aranabilir hukuki arşivlerin, şeffaf karar-destek sistemlerinin ve adalet sisteminde daha anlaşılır ve adil yapay zekâ uygulamalarının önemli bir temeli haline gelebilir.
Atıf: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
Anahtar kelimeler: hukuki doğal dil işleme, mahkeme kararı segmentasyonu, hiyerarşik dönüştürücüler, açıklanabilir yapay zeka, Pakistan Yüksek Mahkemesi