Clear Sky Science · nl
HiCoBERT: een hiërarchisch transformer-framework voor het segmenteren van secties in Pakistaanse juridische vonnissen met XAI-inzichten op meerdere niveaus
Waarom het opdelen van rechterlijke uitspraken in onderdelen ertoe doet
Wanneer rechters uitspraken schrijven, vertellen ze doorgaans een lange, compacte verhaal: eerst de achtergrond, daarna de kwesties, vervolgens pagina’s met motivering en tenslotte het vonnis. Voor advocaten, burgers of software die een sleutelpassage zoeken, kan deze tekstmassa overweldigend zijn. Dit artikel introduceert HiCoBERT, een nieuw kunstmatig-intelligentie‑framework dat automatisch vonnissen van het Pakistaanse Hooggerechtshof in vier betekenisvolle delen snijdt — achtergrond, kwesties, motivering en beslissing — zodat juridische informatie preciezer doorzocht, samengevat en geanalyseerd kan worden.
Juridische verhalen omzetten in heldere bouwstenen
De auteurs vertrekken van een eenvoudige observatie: de meeste moderne taalmodellen lezen een document als een platte stroom woorden en negeren dat vonnissen van nature in fasen zijn georganiseerd. Eerder onderzoek liet zien dat respect voor deze interne structuur — het scheiden van feiten en juridische analyse bijvoorbeeld — taken zoals samenvatten en uitkomstvoorspelling verbetert. Voortbouwend op dit idee definieert het team een praktisch viervoudig sjabloon dat past bij hoe veel rechtbanken daadwerkelijk schrijven: een beknopte casusomschrijving, de punten die de rechtbank moet beslissen, de gedetailleerde motivering en de uiteindelijke beslissing. Hun doel is een AI-systeem te leren deze structuur automatisch te herstellen, zelfs wanneer er geen koppen of visuele aanwijzingen aanwezig zijn.
Een nieuwe dataset opbouwen van Pakistan’s hoogste rechtbank
Om hun methode te trainen en te testen curateerden de auteurs LeJA, een nieuwe dataset van vonnissen van het Hooggerechtshof van Pakistan. Nadat metadata zoals zaaknummers en datums waren verwijderd, labelden juridische experts elk vonnis volgens de vier functionele secties, waarbij zij erop toezagen dat de onderdelen geordend, niet-overlappend en consistent waren over documenten heen. Omdat vonnissen veel langer zijn dan waar standaard-AI‑modellen in één keer mee uit de voeten kunnen, werden de teksten verder verdeeld in kleinere stukken van ongeveer 128 tokens (ongeveer enkele zinnen), met een dynamische strategie die zinnen intact houdt en tegelijk de rekencapaciteit beheersbaar houdt.
Hoe het hiërarchische model lange vonnissen leest
HiCoBERT benadert elk vonnis in twee fasen. Eerst behandelt het elk tekstblok als een mini-document en gebruikt het een juridische domeinvariant van het BERT-model (LegalBERT) om de lokale betekenis te begrijpen. Dit levert een compacte vectorsamenvatting van elk blok op. Vervolgens, in plaats van daar te stoppen, voert het de volledige reeks bloksamenvattingen in een extra Transformer en een bidirectioneel recurrent netwerk. Deze lagen stellen het model in staat elk blok met de rest van het document te vergelijken en te leren hoe vroege achtergrond, tussenliggende kwesties en late motivering gewoonlijk met elkaar samenhangen. Een laatste classifier wijst dan op elk blok één van de vier functionele rollen toe, gestuurd door zowel de eigen inhoud als de buurblokken.
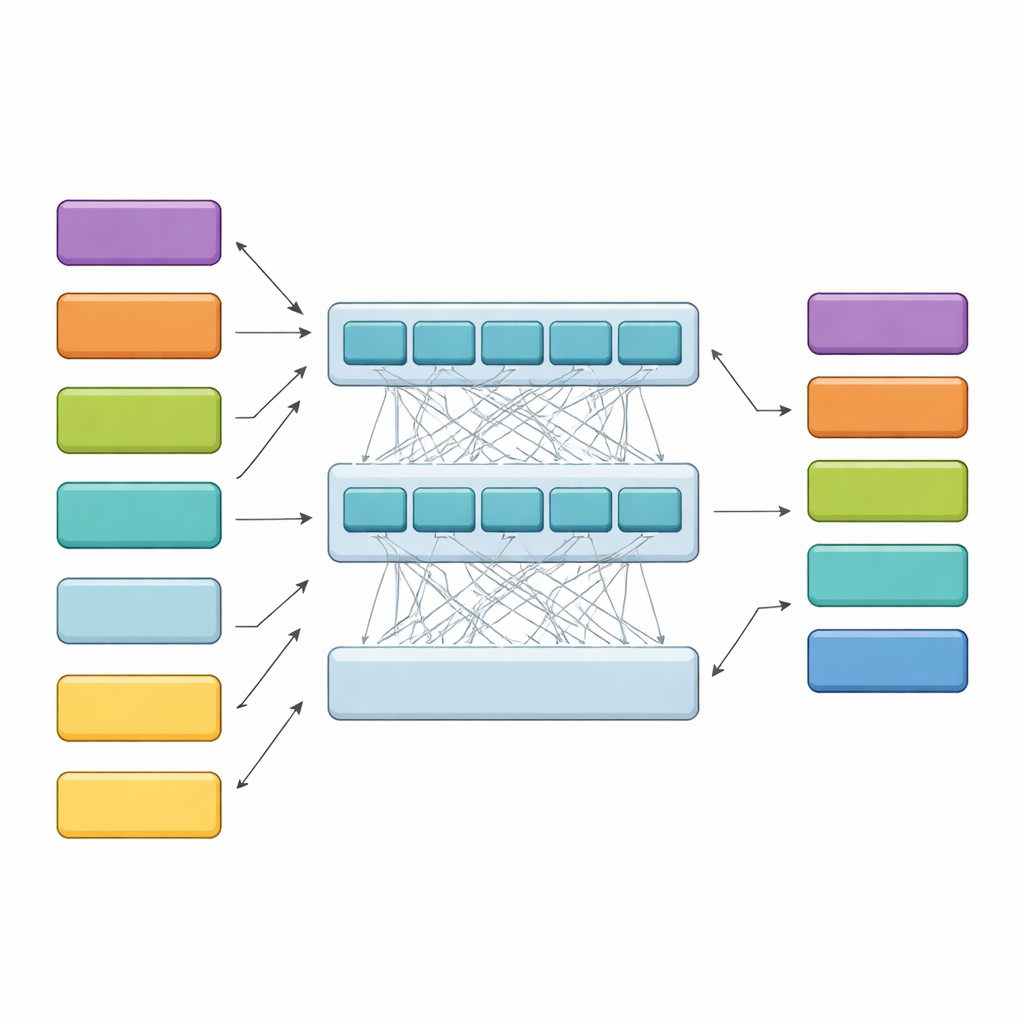
Concurrenten verslaan en het redeneren van het model checken
In tests op de LeJA‑dataset behaalde HiCoBERT ongeveer 80% nauwkeurigheid en een macro‑F1‑score van 0,70, waarmee het sterke alternatieven als Longformer, BigBird, LongT5 en een LegalBERT gecombineerd met een traditionele sequentietagger overtrof. Het verging het model ook gunstig ten opzichte van moderne grote taalmodellen die via prompts werden aangestuurd, waaronder GPT‑4o, Gemini Pro en DeepSeek‑V3, vooral wanneer men de prestaties over alle vier sectietypen in balans bracht in plaats van alleen het dominante “motivering”-deel. De auteurs onderzochten vervolgens hoe HiCoBERT zijn beslissingen neemt met behulp van verklaarbare-AI‑tools. Token‑niveau‑analyses toonden dat het model focust op feitelijke details in de achtergrond, op fraseringen die vragen kaderen in de kwesties, op juridische citaten en argumentatieve bewoording in de motivering en op beslissende formuleringen in de uitspraak. Segmentniveau‑tests lieten zien dat nabijgelegen blokken, vooral net vóór de beslissing, sterk beïnvloeden hoe een sectie wordt gelabeld, wat het belang van context bevestigt.
Robuustheid over grenzen heen testen en vooruitkijken
Om te onderzoeken of hun aanpak generaliseert buiten Pakistan evalueerden de onderzoekers HiCoBERT op LegalSeg, een openbare dataset van Indiase vonnissen met vergelijkbare retorische rollen. Zonder hertraining presteerde het model nog steeds redelijk goed, vooral op de kernsecties motivering en beslissing, hoewel het meer moeite had met korte en ambigue formuleringen van kwesties. Dit suggereert dat het model breed gedeelde patronen van juridisch schrijven vastlegt, terwijl fijnmazigere detectie van kwesties kan afhangen van lokale schrijfstijl. De auteurs wijzen ook op praktische beperkingen: een vaste maximale documentlengte, sterke klasse-imbalance ten gunste van de motiveringssectie en af en toe verwarring nabij sectiegrenzen, wat toekomstige verbeteringen zoals adaptieve contextvensters en grensbewuste attentie motiveert.
Wat dit betekent voor dagelijks gebruik van juridische AI
Kort gezegd laat de studie zien dat het behandelen van vonnissen als zorgvuldig geordende verhalen in plaats van ongedeelde tekst leidt tot meer accurate en interpreteerbare AI‑hulpmiddelen. HiCoBERTs hiërarchische ontwerp maakt het mogelijk lange uitspraken op te delen in betekenisvolle delen die overeenkomen met hoe juristen en rechters van nature over zaken denken. Dit kan het eenvoudiger maken systemen te bouwen die snel de feiten naar voren halen, de kwesties isoleren, de motivering volgen of direct naar het vonnis springen. Naarmate zulke modellen rijpen en worden uitgebreid naar andere rechtbanken en talen, kunnen ze een belangrijke basis vormen voor doorzoekbare juridische archieven, transparante besluitvormingsondersteuning en eerlijkere, beter begrijpelijke toepassingen van AI in het rechtsstelsel.
Bronvermelding: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
Trefwoorden: juridische natural language processing, segmentatie van vonnissen, hiërarchische transformers, verklaarbare AI, Hooggerechtshof van Pakistan