Clear Sky Science · ru
HiCoBERT: иерархическая трансформерная система для сегментации частей правовых решений Пакистана с многоуровневыми интерпретируемыми объяснениями
Почему важно разбивать судебные решения на части
Когда судьи формулируют решения, они обычно излагают длинный плотный рассказ: сначала обстоятельства, затем вопросы, затем страницы мотивировочной части и, наконец, резолютивная часть. Для юристов, граждан или программ, ищущих ключевой фрагмент, такой массив текста может быть непроницаемым. В статье представлена HiCoBERT — новая система искусственного интеллекта, которая автоматически делит решения Верховного суда Пакистана на четыре осмысленных части — обстоятельства, вопросы, мотивировка и постановление — чтобы юридическую информацию можно было искать, суммировать и анализировать точнее.
Преобразование юридических историй в понятные блоки
Авторы исходят из простого наблюдения: большинство современных языковых моделей рассматривают документ как плоскую последовательность слов, игнорируя то, что решения естественно организованы по стадиям. Ранние исследования показали, что уважение к этой внутренней структуре — например, отделение фактов от юридического анализа — улучшает задачи вроде суммаризации и прогнозирования исхода. Исходя из этой идеи, команда определила практичный шаблон из четырёх частей, который соответствует тому, как многие суды действительно пишут: краткое изложение дела, вопросы, которые суд должен решить, подробная мотивировка и окончательное постановление. Их цель — научить ИИ автоматически восстанавливать эту структуру, даже когда отсутствуют заголовки или визуальные подсказки.
Создание нового набора данных из дел верховного суда Пакистана
Для обучения и тестирования метода авторы собрали LeJA — новый набор решений Верховного суда Пакистана. Удалив метаданные вроде номеров дел и дат, эксперты в праве разметили каждое решение по четырём функциональным разделам, гарантируя, что части идут в порядке, не перекрываются и выдержаны единообразно по документам. Поскольку судебные решения значительно длиннее, чем может обработать стандартная модель ИИ за один проход, тексты дополнительно разбили на более мелкие фрагменты примерно по 128 токенов (ориентировочно несколько предложений), применив динамическую стратегию, сохраняющую целостность предложений и одновременно обеспечивающую управляемость вычислений.
Как иерархическая модель читает длинные решения
HiCoBERT обрабатывает каждое решение в два этапа. Сначала он рассматривает каждый фрагмент текста как мини-документ и использует юридическую версию модели BERT (LegalBERT) для понимания локального смысла. Это порождает компактное векторное резюме каждого фрагмента. Затем, вместо того чтобы на этом остановиться, модель подаёт всю последовательность таких векторных представлений во второй трансформер и двунаправленную рекуррентную сеть. Эти слои позволяют модели сравнивать каждый фрагмент с остальным документом, изучая, как ранние обстоятельства, срединные вопросы и поздняя мотивировка обычно соотносятся друг с другом. Финальный классификатор присваивает каждому фрагменту одну из четырёх функциональных ролей, опираясь и на его содержание, и на соседние фрагменты.
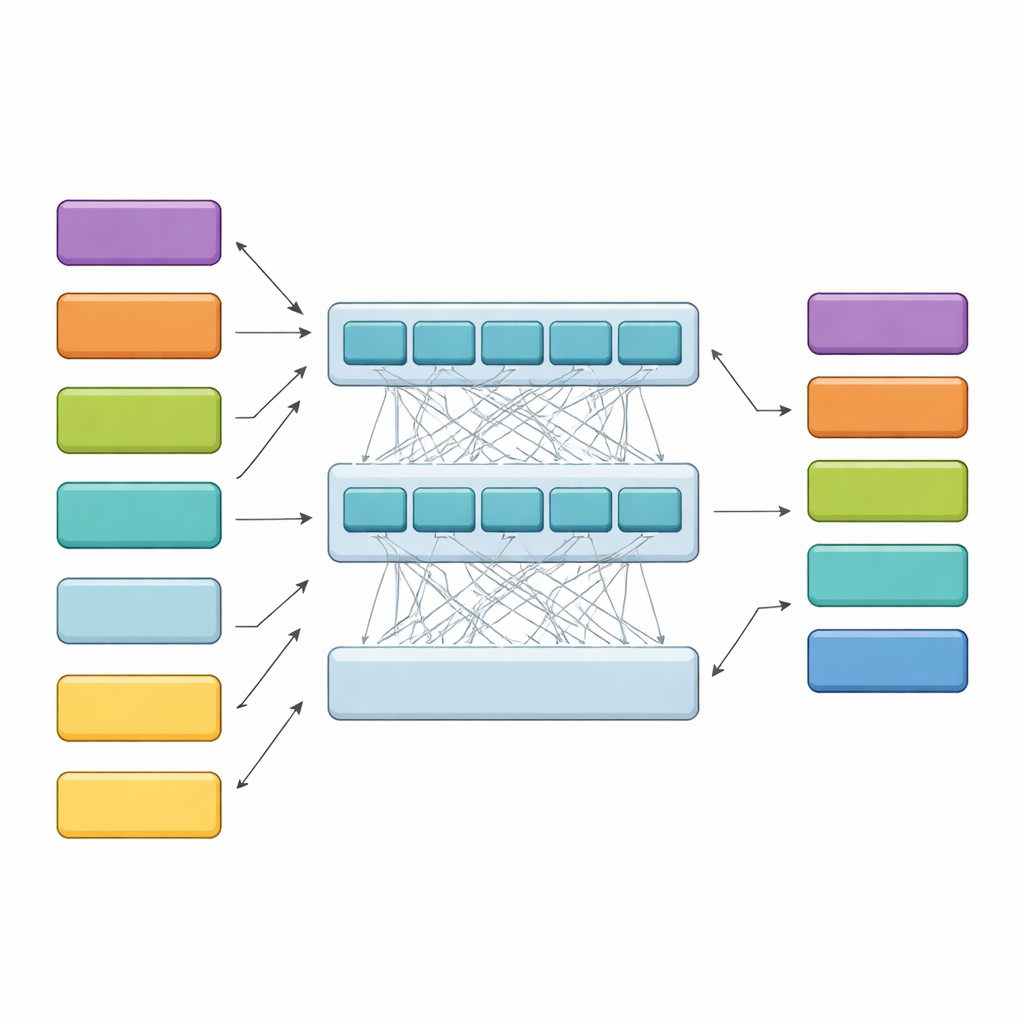
Превосходство над конкурентами и проверка логики модели
В тестах на наборе LeJA HiCoBERT достиг примерно 80% точности и макро-F1 0,70, превосходя сильные альтернативы, такие как Longformer, BigBird, LongT5 и связку LegalBERT с традиционным теггером последовательностей. Он также показал благоприятное сравнение с современными крупными языковыми моделями, запущенными с подсказками, включая GPT-4o, Gemini Pro и DeepSeek-V3, особенно при учёте качества по всем четырём типам секций, а не только по доминирующей части «мотивировка». Авторы затем исследовали, как HiCoBERT обосновывает свои решения, с помощью инструментов объяснимого ИИ. Анализ на уровне токенов показал, что модель фокусируется на фактических деталях в разделе обстоятельств, на формулировках вопроса в разделе вопросов, на юридических ссылках и аргументационной лексике в мотивировке и на решающих фразах в постановлении. Тесты на уровне сегментов выявили, что соседние фрагменты, особенно непосредственно перед постановлением, сильно влияют на присвоение метки раздела, подтверждая важность контекста.
Проверка устойчивости за пределами страны и перспективы
Чтобы понять, обобщается ли подход за пределами Пакистана, исследователи оценили HiCoBERT на LegalSeg — публичном наборе индийских решений с похожими риторическими ролями. Без дополнительного обучения модель по-прежнему показала разумные результаты, особенно по основным секциям мотивировки и постановления, хотя с краткими и неоднозначными формулировками вопросов она справлялась хуже. Это указывает на то, что модель улавливает широко распространённые шаблоны юридического письма, тогда как более тонкая детекция вопросов может зависеть от местных стилей оформления. Авторы также отмечают практические ограничения: фиксированная максимальная длина документа, сильный дисбаланс классов в пользу мотивировочной части и периодическая путаница вблизи границ секций, что мотивирует будущие улучшения, такие как адаптивные окна контекста и внимание, учитывающее границы.
Что это значит для повседневного использования юридического ИИ
Проще говоря, исследование показывает: рассматривать судебные решения как упорядоченные повествования, а не как однородный текст — выгодно для создания более точных и интерпретируемых инструментов ИИ. Иерархическая архитектура HiCoBERT позволяет разбивать длинные решения на осмысленные части, соответствующие тому, как юристы и судьи интуитивно мыслят о делах. Это облегчает создание систем, которые быстро выделяют факты, изолируют вопросы, прослеживают мотивировку или сразу переходят к постановлению. По мере того как такие модели развиваются и адаптируются к другим судам и языкам, они могут стать важной основой для поисковых юридических архивов, прозрачных инструментов поддержки принятия решений и более справедливых, понятных применений ИИ в системе правосудия.
Цитирование: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
Ключевые слова: обработка естественного языка в праве, сегментация судебных решений, иерархические трансформеры, объяснимый ИИ, Верховный суд Пакистана