Clear Sky Science · en
HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights
Why breaking court decisions into parts matters
When judges write decisions, they usually tell a long, dense story: first the background, then the issues, then pages of reasoning, and finally the ruling. For lawyers, citizens, or software tools trying to find a key passage, this wall of text can be overwhelming. This paper introduces HiCoBERT, a new artificial intelligence framework that automatically slices Pakistani Supreme Court judgments into four meaningful parts—background, issues, reasons, and decision—so that legal information can be searched, summarized, and analyzed more precisely.
Turning legal stories into clear building blocks
The authors start from a simple observation: most modern language models read a document as a flat stream of words, ignoring the fact that judgments are naturally organized in stages. Earlier research showed that respecting this internal structure—separating facts from legal analysis, for example—improves tasks like summarization and outcome prediction. Building on this idea, the team defines a practical four-part template that matches how many courts actually write: a concise statement of the case, the points the court must decide, the detailed reasons, and the final decision. Their goal is to teach an AI system to recover this structure automatically, even when no headings or visual cues are present.
Building a new dataset from Pakistan’s top court
To train and test their method, the authors curated LeJA, a new dataset of judgments from the Supreme Court of Pakistan. After stripping away metadata such as case numbers and dates, legal experts labeled each judgment according to the four functional sections, ensuring that the parts were ordered, non-overlapping, and consistent across documents. Because court decisions are much longer than what standard AI models can read in one go, the texts were further divided into smaller chunks of about 128 tokens (roughly several sentences), using a dynamic strategy that keeps sentences intact while keeping computation manageable.
How the hierarchical model reads long judgments
HiCoBERT approaches each judgment in two stages. First, it treats each chunk of text like a mini-document and uses a legal-domain version of the BERT model (LegalBERT) to understand its local meaning. This produces a compact vector summary of every chunk. Second, instead of stopping there, it feeds the entire sequence of chunk summaries into an additional Transformer and a bidirectional recurrent network. These layers allow the model to compare each chunk with the rest of the document, learning how early background, midstream issues, and late-stage reasoning typically relate to one another. A final classifier then assigns one of the four functional roles to every chunk, guided by both its own content and its neighbors.
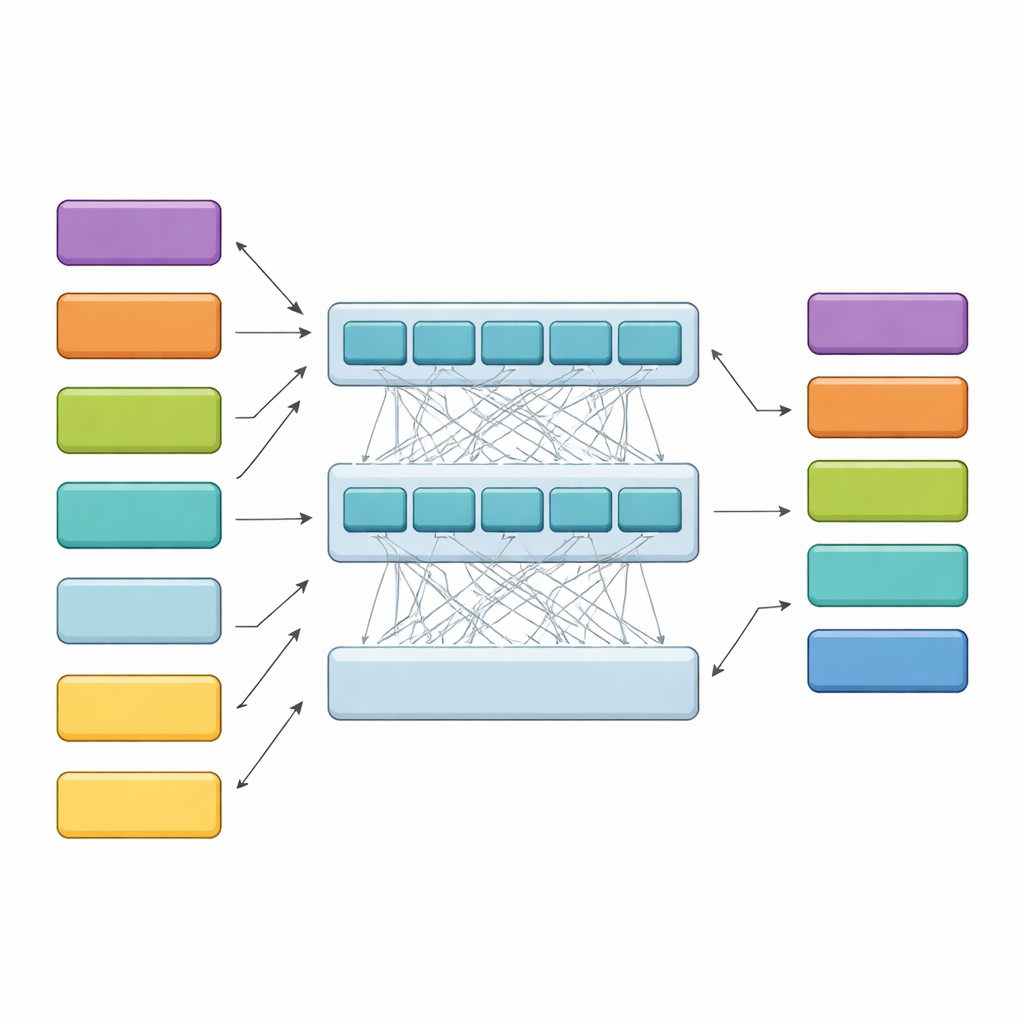
Beating rival models and checking the model’s reasoning
In tests on the LeJA dataset, HiCoBERT reached about 80% accuracy and a macro-F1 score of 0.70, outperforming strong alternatives such as Longformer, BigBird, LongT5, and a LegalBERT model paired with a traditional sequence tagger. It also compared favorably to modern large language models run via prompts, including GPT-4o, Gemini Pro, and DeepSeek-V3, especially when balancing performance on all four section types instead of just the dominant “reasons” portion. The authors then probed how HiCoBERT makes its decisions using explainable AI tools. Token-level analyses showed that the model focuses on factual details in the background, question-framing phrases in the issues, legal citations and argumentative wording in the reasons, and decisive phrases in the ruling. Segment-level tests revealed that nearby chunks, especially just before the decision, strongly influence how a section is labeled, confirming the importance of context.
Testing robustness across borders and looking ahead
To see whether their approach generalizes beyond Pakistan, the researchers evaluated HiCoBERT on LegalSeg, a public dataset of Indian judgments with similar rhetorical roles. Without retraining, the model still performed reasonably well, especially on the core reasoning and decision sections, though it struggled more with the brief and ambiguous issue statements. This suggests that the model captures broadly shared patterns of legal writing, while finer-grained issue detection may depend on local drafting style. The authors also note practical limitations: a fixed maximum document length, strong class imbalance toward the reasoning section, and occasional confusion near section boundaries, all of which motivate future improvements such as adaptive context windows and boundary-aware attention.
What this means for everyday use of legal AI
In plain terms, the study shows that treating court judgments as carefully ordered stories rather than undifferentiated text yields more accurate and interpretable AI tools. HiCoBERT’s hierarchical design allows long decisions to be split into meaningful parts that match how lawyers and judges naturally think about cases. This can make it easier to build systems that quickly surface the facts, isolate the issues, trace the reasoning, or jump straight to the ruling. As such models mature and are extended to other courts and languages, they could become an important foundation for searchable legal archives, transparent decision-support tools, and fairer, more understandable applications of AI in the justice system.
Citation: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
Keywords: legal natural language processing, court judgment segmentation, hierarchical transformers, explainable AI, Pakistan Supreme Court