Clear Sky Science · sv
HiCoBERT: ett hierarkiskt transformerbaserat ramverk för segmentering av pakistanska rättsavgöranden med flernivå XAI-insikter
Varför det spelar roll att dela upp domstolsavgöranden i delar
När domare skriver avgöranden berättar de ofta en lång, tät historia: först bakgrund, sedan frågorna, därefter flera sidor med motiveringar och slutligen domen. För advokater, medborgare eller programvara som försöker hitta ett nyckelavsnitt kan denna textmassa vara överväldigande. Denna artikel introducerar HiCoBERT, ett nytt artificiellt intelligensramverk som automatiskt delar upp Pakistans högsta domstols avgöranden i fyra meningsfulla delar—bakgrund, frågeställningar, motiveringar och beslut—så att juridisk information kan sökas, sammanfattas och analyseras mer precist.
Att omvandla juridiska berättelser till tydliga byggstenar
Författarna utgår från en enkel iakttagelse: de flesta moderna språkmodeller läser ett dokument som en flat ordström och bortser från att avgöranden naturligt organiseras i skeden. Tidigare forskning visade att respekt för denna interna struktur—att separera fakta från juridisk analys, till exempel—förbättrar uppgifter som sammanfattning och utfallsprognos. Med denna idé som grund definierar teamet en praktisk fyrdelad mall som motsvarar hur många domstolar faktiskt formulerar sina beslut: en kortfattad redogörelse av ärendet, de frågor domstolen måste avgöra, de detaljerade motiveringarna och slutligen beslutet. Målet är att lära ett AI-system att automatiskt återskapa denna struktur, även när inga rubriker eller visuella ledtrådar finns.
Att bygga en ny datamängd från Pakistans högsta domstol
För att träna och testa metoden kuraterade författarna LeJA, en ny datamängd med avgöranden från Pakistans högsta domstol. Efter att ha tagit bort metadata som målnummer och datum märkte juridiska experter varje avgörande enligt de fyra funktionella sektionerna, och säkerställde att delarna var ordnade, icke-överlappande och konsekventa över dokument. Eftersom domstolsavgöranden är mycket längre än vad standardmodeller klarar i ett stycke delades texterna ytterligare upp i mindre bitar om cirka 128 token (ungefär flera meningar), med en dynamisk strategi som bevarar meningar intakta samtidigt som beräkningen hålls hanterbar.
Hur den hierarkiska modellen läser långa avgöranden
HiCoBERT närmar sig varje avgörande i två steg. Först behandlas varje textbit som ett mini-dokument och en juridisk domänanpassad version av BERT (LegalBERT) används för att förstå dess lokala innebörd. Detta ger en kompakt vektorsammanfattning av varje bit. Sedan, istället för att stanna där, matas hela sekvensen av bit-sammanfattningar in i en ytterligare Transformer och ett bidirektionellt rekurrent nätverk. Dessa lager tillåter modellen att jämföra varje bit med resten av dokumentet och lära sig hur tidig bakgrund, mellanskedans frågor och slutliga motiveringar vanligtvis relaterar till varandra. En slutgiltig klassificerare tilldelar därefter en av de fyra funktionella rollerna till varje bit, styrd både av dess eget innehåll och av grannarna.
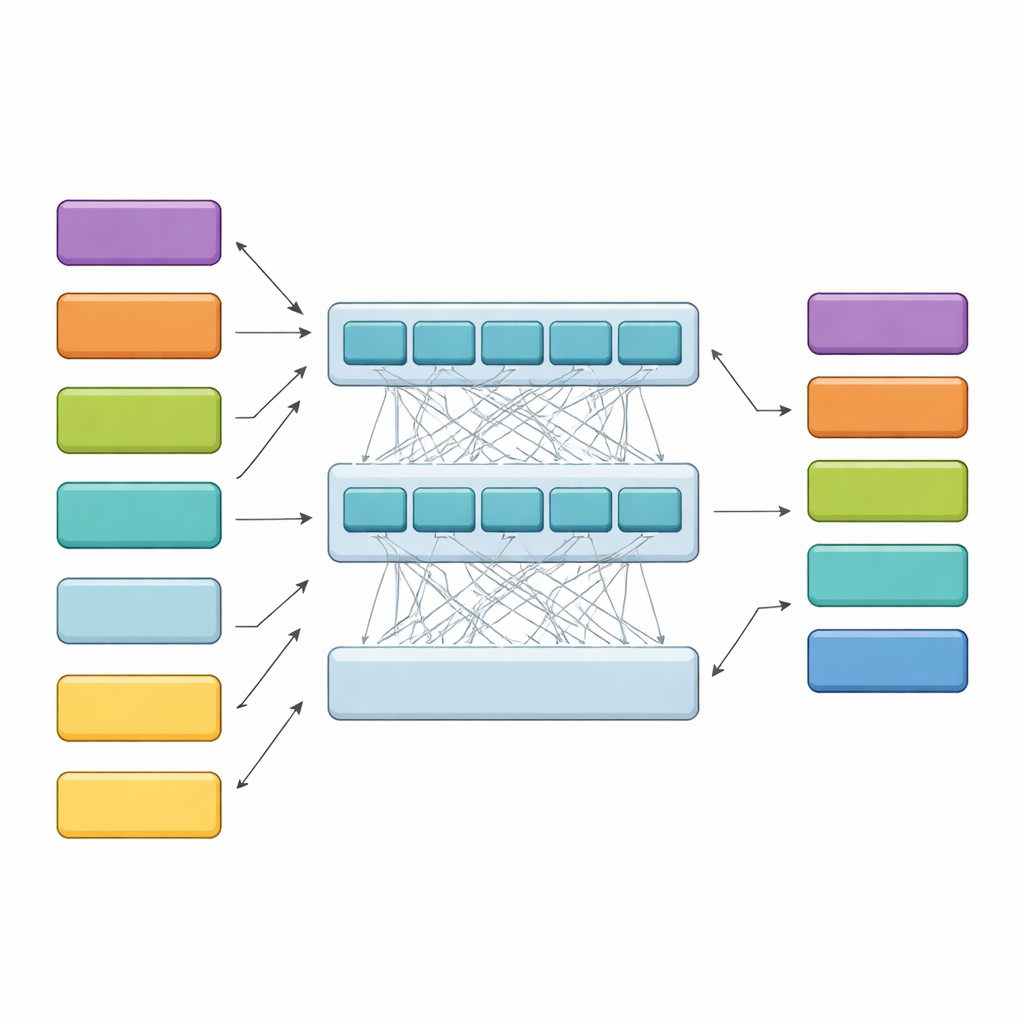
Slår rivalmodeller och granskar modellens resonemang
I tester på LeJA-datamängden nådde HiCoBERT ungefär 80 % noggrannhet och ett macro-F1-värde på 0,70 och överträffade starka alternativ som Longformer, BigBird, LongT5 samt en LegalBERT-modell kombinerad med en traditionell sekvenstagare. Den stod sig också väl i jämförelse med moderna stora språkmodeller som körts via prompting, inklusive GPT-4o, Gemini Pro och DeepSeek-V3, särskilt när man väger prestanda över alla fyra sektionstyper snarare än bara den dominerande "motiveringar"-delen. Författarna granskade sedan hur HiCoBERT fattar sina beslut med verktyg för förklarbar AI. Token-nivåanalyser visade att modellen fokuserar på faktiska detaljer i bakgrunden, frågor som ramar in problem i issues-sektionen, juridiska hänvisningar och argumenterande formuleringar i motiveringarna samt beslutsfattande fraser i domen. Segmentnivåtester visade att närliggande bitar, särskilt precis före beslutet, starkt påverkar hur en sektion märks, vilket bekräftar kontextens betydelse.
Testa robusthet över gränser och blicka framåt
För att se om deras angreppssätt generaliserar bortom Pakistan utvärderade forskarna HiCoBERT på LegalSeg, en offentlig datamängd med indiska avgöranden med liknande retoriska roller. Utan omträning presterade modellen fortfarande rimligt bra, särskilt på de centrala motiverings- och beslutssektionerna, även om den hade större svårigheter med korta och tvetydiga formuleringar av issues. Detta tyder på att modellen fångar brett delade mönster i juridiskt skrivande, samtidigt som mer finkornig detektion av frågeställningar kan bero på lokal skrivstil. Författarna noterar också praktiska begränsningar: en fast maximal dokumentlängd, stark klassobalans mot motiveringssektionen och ibland förvirring nära sektionsgränserna, vilket alla motiverar framtida förbättringar såsom adaptiva kontextfönster och gränsmedveten attention.
Vad detta betyder för vardaglig användning av juridisk AI
I korthet visar studien att behandla domstolsavgöranden som omsorgsfullt ordnade berättelser snarare än odifferentierad text ger mer precisa och tolkbara AI-verktyg. HiCoBERTs hierarkiska design gör det möjligt att dela upp långa avgöranden i meningsfulla delar som stämmer med hur jurister och domare naturligt tänker om ärenden. Det kan göra det enklare att bygga system som snabbt lyfter fram fakta, isolerar frågeställningar, spårar motiveringarna eller hoppar direkt till domen. Allteftersom sådana modeller mognar och utvidgas till andra domstolar och språk kan de bli en viktig grund för sökbara juridiska arkiv, transparenta beslutsstöd och rättvisare, mer förståeliga tillämpningar av AI i rättssystemet.
Citering: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
Nyckelord: juridisk naturlig språkbehandling, segmentering av domstolsavgöranden, hierarkiska transformermodeller, förklarbar AI, Pakistans högsta domstol