Clear Sky Science · he
HiCoBERT: מסגרת היררכית מבוססת טרנספורמר לחלוקת סעיפי פסקי דין בפקולטת פקידות של פקיסטן עם תובנות XAI ברב־רמות
מדוע חשוב לחלק החלטות שיפוטיות לחלקים
כששופטים כותבים החלטות, בדרך כלל הם מספרים סיפור ארוך וצפוף: תחילה הרקע, אחר כך הנושאים, דפים של נימוקים ולבסוף הפסיקה. עבור עורכי דין, אזרחים או כלי תוכנה שמחפשים קטע מפתח, חומת הטקסט הזו עלולה להיות מכבידה. מאמר זה מציג את HiCoBERT, מסגרת בינה מלאכותית חדשה שמחלקת באופן אוטומטי פסקי דין של בית המשפט העליון של פקיסטן לארבעה חלקים משמעותיים — רקע, נושאים, נימוקים והחלטה — כדי שמידע משפטי יתאפשר לחיפוש, לסיכום ולניתוח באופן מדויק יותר.
להפוך סיפורים משפטיים לגורמי בניין ברורים
המחברים יוצאים מתצפית פשוטה: רוב דגמי השפה המודרניים קוראים מסמך כזרם שטוח של מילים, ומתעלמים מהעובדה שפסקי דין מאורגנים באופן טבעי בשלבים. מחקרים קודמים הראו שכיבוד מבנה פנימי זה — למשל הפרדה בין עובדות לבין ניתוח משפטי — משפר משימות כמו סיכום וחיזוי תוצאה. בהתבסס על רעיון זה, הצוות מגדיר תבנית מעשית בארבעה חלקים שמתאימה לאופן הכתיבה של בתי משפט רבים: הצהרה תמציתית של המקרה, הנקודות שהבית המשפט נדרש להכריע בהן, הנימוקים המפורטים, וההחלטה הסופית. מטרתם ללמד מערכת בינה מלאכותית לשחזר מבנה זה אוטומטית, גם כאשר אין כותרות או רמזים חזותיים.
בניית מאגר נתונים חדש מבית המשפט העליון של פקיסטן
כדי לאמן ולבחון את המתודה שלהם, המחברים יצרו את LeJA, מאגר נתונים חדש של פסקי דין מבית המשפט העליון של פקיסטן. לאחר הסרת מטא־נתונים כגון מספרי תיקים ותאריכים, מומחים משפטיים סומנו כל פסק דין לפי ארבעת הסעיפים הפונקציונליים, כשהחלקים סודרו כך שלא יתמזגו או יחפפו והיו עקביים בין המסמכים. מכיוון שפסקי דין ארוכים הרבה יותר ממה שדגמי AI סטנדרטיים יכולים לקרוא בבת אחת, הטקסטים חולקו עוד לשבצים קטנים של כ־128 טוקנים (בערך מספר משפטים), באמצעות אסטרטגיה דינמית ששומרת על שלמות המשפטים תוך כדי שמירה על עומס חישובי סביר.
איך המודל ההיררכי קורא פסקי דין ארוכים
HiCoBERT ניגש לכל פסק דין בשני שלבים. ראשית, הוא מתייחס לכל חתיכה של טקסט כמו למסמך מיניאטורי ומשתמש בגרסה מתחום המשפט של מודל BERT (LegalBERT) כדי להבין את משמעותה המקומית. זה מייצר סיכום וקטורי קומפקטי של כל חלק. שנית, במקום לעצור שם, הוא מזין את כל רצף הסיכומים של החתיכות לטרנספורמר נוסף ורשת חוזרת חד־כיוונית-דו״כיוונית. שכבות אלה מאפשרות למודל להשוות כל חלק לשאר המסמך וללמוד כיצד רקע מוקדם, סוגיות באמצע ונימוקים בשלב מאוחר מתקשרים בדרך כלל זה לזה. מסווג סופי מקצה אז את אחד מהתפקידים הפונקציונליים לאותה חתיכה, בהנחיית תוכנה שלה ושל שכנותיה.
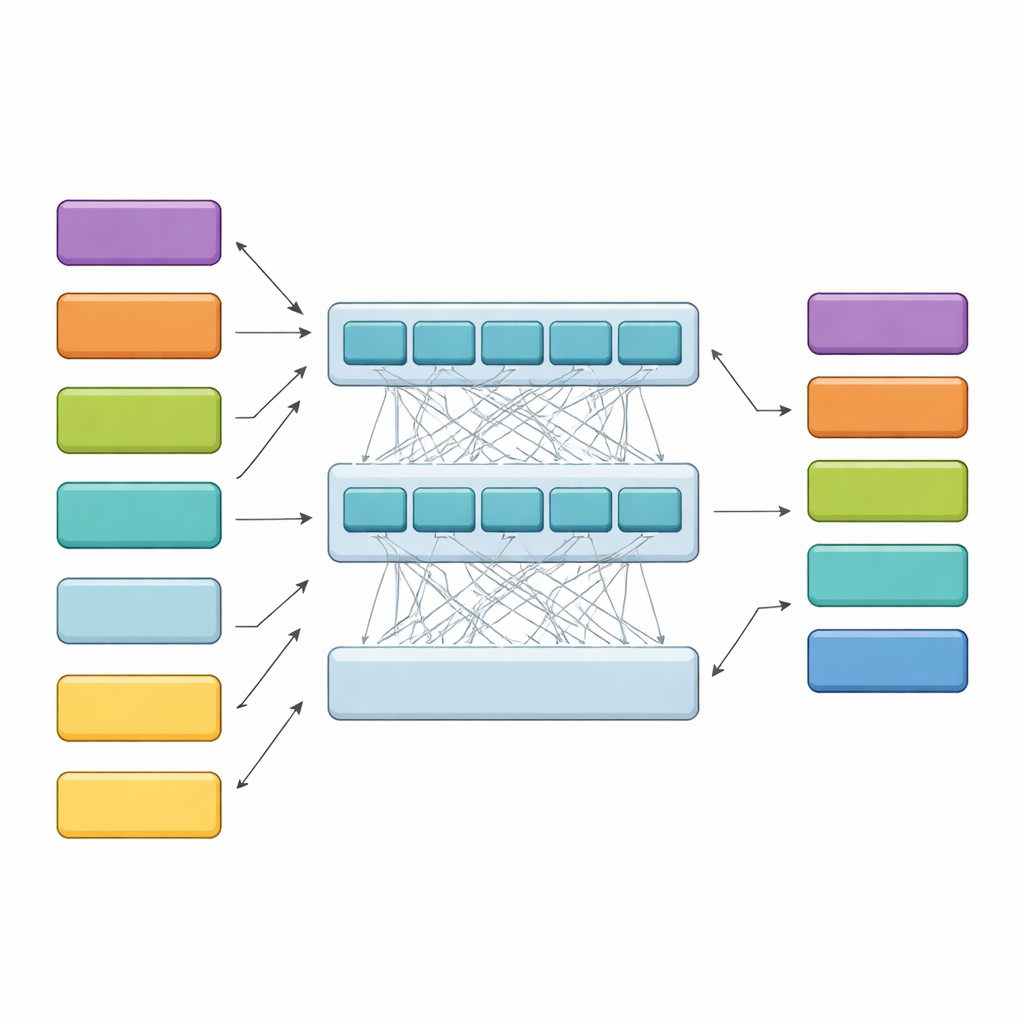
לנצח דגמים מתחרים ולבדוק את הנימוקים של המודל
במבחנים על מאגר LeJA, HiCoBERT השיג כ־80% דיוק וציון macro‑F1 של 0.70, תוך הישג מעל אלטרנטיבות חזקות כגון Longformer, BigBird, LongT5, ומודל LegalBERT בצירוף תגי רצף מסורתי. הוא השווה יתרון גם מול דגמי שפה גדולים מודרניים שהופעלו בעזרת פרומפטים, כולל GPT‑4o, Gemini Pro ו‑DeepSeek‑V3, במיוחד כאשר מאזנים ביצועים על כל ארבעת סוגי הסעיפים ולא רק על החלק הדומיננטי של "נימוקים". לאחר מכן המחברים בחנו כיצד HiCoBERT מקבל החלטות באמצעות כלים של בינה מוסברת. ניתוח ברמת הטוקן הראה שהמודל מתמקד בפרטי עובדות ברקע, בביטויי ניסוח שאלות בסעיף הנושאים, בציטוטים משפטיים ובניסוח טיעוני בנימוקים, ובניסוחים החלטיים בפסיקה. מבחנים ברמת הקטע חשפו כי חלקים סמוכים, במיוחד אלה שמופיעים ממש לפני ההחלטה, משפיעים בחוזקה על תווית הסעיף, מה שמאשר את חשיבות ההקשר.
בדיקת עמידות מעבר לגבולות ומבט קדימה
כדי לבדוק האם הגישה שלהם מתכללת מעבר לפקיסטן, החוקרים העריכו את HiCoBERT על LegalSeg, מאגר ציבורי של פסקי דין הודיים בעלי תפקידים רטוריים דומים. ללא אימון מחדש, המודל עדיין עמד בביצועים סבירים, במיוחד בחלקי הנימוקים וההחלטה המרכזיים, אם כי התקשה יותר עם ניסוחים קצרים ומעורפלים של הנושאים. זה מרמז שהמודל לוכד דפוסים משותפים ורחבים בכתיבה משפטית, בעוד שזיהוי דק של סוגיות עשוי להתבסס על סגנון ניסוח מקומי. המחברים גם מציינים מגבלות מעשיות: אורך מסמך מקסימלי קבוע, חוסר איזון חזק בכיתות לטובת סעיף הנימוקים, ובלבול מקומי סמוך לגבולות הסעיפים — כל אלה מדרבנים שיפורים עתידיים כמו חלונות הקשר אדפטיביים ותשומת לב הרגישה לגבולות.
מה משמע הדבר לשימוש היומיומי בבינה משפטית
במלים פשוטות, המחקר מראה שטיפול בפסקי דין כבסיפורים מסודרים במקום כטקסט אחיד מביא לכלים של AI דיוקים ופרשנות טובים יותר. העיצוב ההיררכי של HiCoBERT מאפשר לפצל החלטות ארוכות לחלקים משמעותיים התואמים לאופן שבו עורכי דין ושופטים חושבים על תיקים. זה יכול להקל על בניית מערכות שמעלות במהירות את העובדות, מבודדות את הנושאים, עוקבות אחרי הנימוקים או מדלגות ישירות לפסיקה. ככל שמודלים אלה יתפתחו ויורחבו לבתי משפט ושפות נוספות, הם עשויים להפוך לבסיס חשוב לארכיוני חיפוש משפטיים, לכלי תמיכה בהחלטה שקופים וליישומי AI הוגנים וברורים יותר במערכת המשפטית.
ציטוט: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
מילות מפתח: עיבוד שפה טבעית משפטי, חלוקת פסקי דין של בתי משפט, טרנספורמרים היררכיים, בינה מוסברת, בית המשפט העליון של פקיסטן