Clear Sky Science · it
HiCoBERT: un framework gerarchico basato su transformer per la segmentazione delle sezioni dei giudizi pakistani con approfondimenti XAI multilivello
Perché suddividere le sentenze è importante
Quando i giudici redigono le sentenze, spesso raccontano una lunga e densa storia: prima i fatti, poi le questioni, quindi pagine di motivazione e infine la decisione. Per avvocati, cittadini o strumenti software che cercano un passaggio chiave, questo muro di testo può risultare opprimente. Questo articolo presenta HiCoBERT, un nuovo framework di intelligenza artificiale che suddivide automaticamente le sentenze della Corte Suprema del Pakistan in quattro parti significative — contesto, questioni, motivazioni e decisione — in modo che le informazioni legali possano essere cercate, sintetizzate e analizzate con maggiore precisione.
Trasformare i racconti giuridici in blocchi chiari
Gli autori partono da un’osservazione semplice: la maggior parte dei modelli linguistici moderni legge un documento come un flusso piatto di parole, ignorando il fatto che le sentenze sono naturalmente organizzate per fasi. Ricerche precedenti hanno dimostrato che rispettare questa struttura interna — separare, per esempio, i fatti dall’analisi giuridica — migliora compiti come la sintesi e la predizione dell’esito. Sulla base di questa idea, il team definisce un modello pratico in quattro parti che corrisponde a come molte corti effettivamente scrivono: una sintesi del caso, i punti che la corte deve decidere, le motivazioni dettagliate e la decisione finale. L’obiettivo è insegnare a un sistema di IA a ricostruire automaticamente questa struttura, anche quando non sono presenti intestazioni o indizi visivi.
Costruire un nuovo dataset dalla corte suprema del Pakistan
Per addestrare e testare il metodo, gli autori hanno curato LeJA, un nuovo dataset di sentenze della Corte Suprema del Pakistan. Dopo aver rimosso i metadati come i numeri di causa e le date, esperti giuridici hanno etichettato ogni sentenza secondo le quattro sezioni funzionali, garantendo che le parti fossero ordinate, non sovrapposte e coerenti tra i documenti. Poiché le decisioni giudiziarie sono molto più lunghe di quanto i modelli standard di IA possano leggere in una sola volta, i testi sono stati ulteriormente suddivisi in blocchi più piccoli di circa 128 token (approssimativamente alcune frasi), usando una strategia dinamica che mantiene intatte le frasi e al contempo controlla il carico computazionale.
Come il modello gerarchico legge le lunghe sentenze
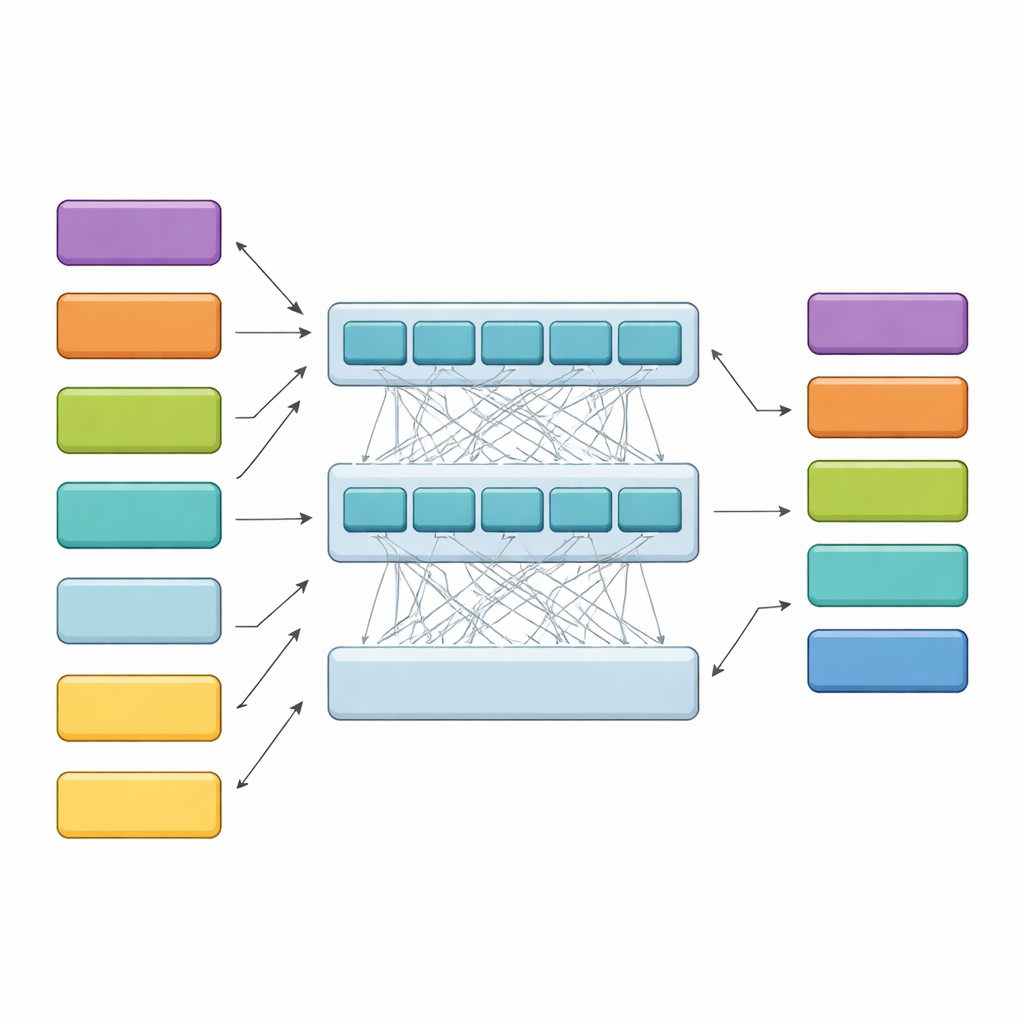
HiCoBERT affronta ogni sentenza in due fasi. Prima tratta ogni blocco di testo come un mini-documento e utilizza una versione di BERT specializzata per il dominio legale (LegalBERT) per comprenderne il significato locale. Questo produce un riassunto vettoriale compatto di ogni blocco. In seconda battuta, invece di fermarsi lì, alimenta l’intera sequenza di riassunti dei blocchi in un ulteriore Transformer e in una rete ricorrente bidirezionale. Questi strati permettono al modello di confrontare ogni blocco con il resto del documento, apprendendo come il contesto iniziale, le questioni di metà testo e le motivazioni finali siano tipicamente correlate. Un classificatore finale assegna quindi a ogni blocco una delle quattro funzioni, guidato sia dal contenuto del blocco sia dai suoi vicini.
Superare i modelli avversari e verificare il ragionamento del modello
Nei test sul dataset LeJA, HiCoBERT ha raggiunto circa l’80% di accuratezza e un punteggio macro-F1 di 0,70, superando alternative robuste come Longformer, BigBird, LongT5 e un modello LegalBERT abbinato a un tradizionale sequence tagger. Ha inoltre avuto un confronto favorevole con moderni large language model usati via prompt, inclusi GPT-4o, Gemini Pro e DeepSeek-V3, soprattutto quando si bilanciava la prestazione su tutte e quattro le sezioni invece di concentrarsi solo sulla porzione predominante delle «motivazioni». Gli autori hanno poi investigato come HiCoBERT prende le sue decisioni utilizzando strumenti di intelligenza artificiale spiegabile. Analisi a livello di token hanno mostrato che il modello si concentra sui dettagli fattuali nel contesto, su frasi che inquadrano la questione nelle sezioni delle questioni, su citazioni legali e formulazioni argomentative nelle motivazioni, e su frasi decisive nella sentenza. Test a livello di segmento hanno rivelato che i blocchi vicini, specialmente quelli immediatamente precedenti la decisione, influenzano fortemente l’etichettatura di una sezione, confermando l’importanza del contesto.
Testare la robustezza oltre i confini e prospettive future
Per verificare se l’approccio generalizza oltre il Pakistan, i ricercatori hanno valutato HiCoBERT su LegalSeg, un dataset pubblico di sentenze indiane con ruoli retorici simili. Senza riaddestramento, il modello ha comunque performato in modo ragionevole, soprattutto sulle sezioni centrali di motivazione e decisione, sebbene abbia avuto più difficoltà con enunciazioni di questioni brevi e ambigue. Ciò suggerisce che il modello cattura schemi di scrittura giuridica ampiamente condivisi, mentre una rilevazione più fine delle questioni può dipendere dallo stile locale di redazione. Gli autori notano anche limiti pratici: una lunghezza massima fissa dei documenti, un forte squilibrio di classe verso la sezione delle motivazioni e occasionali confusioni vicino ai confini tra sezioni, tutti aspetti che motivano miglioramenti futuri come finestre di contesto adattive e attenzione sensibile ai confini.
Cosa significa per l’uso quotidiano dell’IA legale
In termini semplici, lo studio mostra che trattare le sentenze come storie ordinate piuttosto che come testo indifferenziato produce strumenti di IA più accurati e interpretabili. Il design gerarchico di HiCoBERT permette di suddividere le lunghe decisioni in parti significative che corrispondono a come avvocati e giudici pensano naturalmente i casi. Ciò può rendere più facile costruire sistemi che evidenzino rapidamente i fatti, isolino le questioni, traccino le motivazioni o arrivino direttamente alla decisione. Man mano che questi modelli maturano e vengono estesi ad altre corti e lingue, potrebbero diventare una base importante per archivi legali ricercabili, strumenti di supporto alle decisioni trasparenti e applicazioni di IA nella giustizia più eque e comprensibili.
Citazione: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
Parole chiave: elaborazione del linguaggio naturale giuridico, segmentazione dei giudizi della corte, transformer gerarchici, intelligenza artificiale spiegabile, Corte Suprema del Pakistan