Clear Sky Science · pl
HiCoBERT: hierarchiczne ramy oparte na transformerach do segmentacji części orzeczeń sądowych Pakistanu z wielopoziomowymi wglądami XAI
Dlaczego dzielenie orzeczeń sądowych na części ma znaczenie
Kiedy sędziowie piszą orzeczenia, zwykle przedstawiają długą, zagęszczoną narrację: najpierw tło sprawy, potem zagadnienia, następnie strony uzasadnienia, a na końcu rozstrzygnięcie. Dla prawników, obywateli czy narzędzi programowych poszukujących kluczowego fragmentu taki mur tekstu może być przytłaczający. W artykule zaprezentowano HiCoBERT — nowe rozwiązanie sztucznej inteligencji, które automatycznie dzieli orzeczenia Sądu Najwyższego Pakistanu na cztery sensowne części — tło, zagadnienia, uzasadnienie i rozstrzygnięcie — tak aby informacje prawne można było wyszukiwać, streszczać i analizować precyzyjniej.
Przekształcanie prawnych opowieści w przejrzyste bloki
Autorzy wychodzą od prostego spostrzeżenia: większość współczesnych modeli językowych czyta dokument jako płaski strumień słów, ignorując fakt, że orzeczenia naturalnie są zorganizowane etapami. Wcześniejsze badania wykazały, że uwzględnianie tej wewnętrznej struktury — na przykład oddzielanie faktów od analizy prawnej — poprawia zadania takie jak streszczanie czy przewidywanie wyniku. W oparciu o tę ideę zespół definiuje praktyczny, czteroczęściowy szablon odpowiadający temu, jak wiele sądów rzeczywiście pisze: zwięzłe przedstawienie sprawy, punkty, które sąd musi rozstrzygnąć, szczegółowe uzasadnienie oraz ostateczne rozstrzygnięcie. Celem jest nauczenie systemu AI automatycznego odtwarzania tej struktury, nawet gdy brakuje nagłówków lub wizualnych wskazówek.
Budowa nowego zbioru danych z najwyższego sądu Pakistanu
Aby wytrenować i przetestować swoją metodę, autorzy przygotowali LeJA, nowy zbiór orzeczeń z Sądu Najwyższego Pakistanu. Po usunięciu metadanych, takich jak numery spraw i daty, eksperci prawni oznaczyli każde orzeczenie zgodnie z czterema funkcjonalnymi sekcjami, dbając aby części były uporządkowane, nie nakładały się i były spójne w całym korpusie. Ponieważ orzeczenia są znacznie dłuższe niż to, co standardowe modele AI potrafią przetworzyć naraz, teksty dodatkowo podzielono na mniejsze fragmenty liczące około 128 tokenów (w przybliżeniu kilka zdań), stosując dynamiczną strategię, która zachowuje zdania w całości przy jednoczesnym ograniczaniu złożoności obliczeniowej.
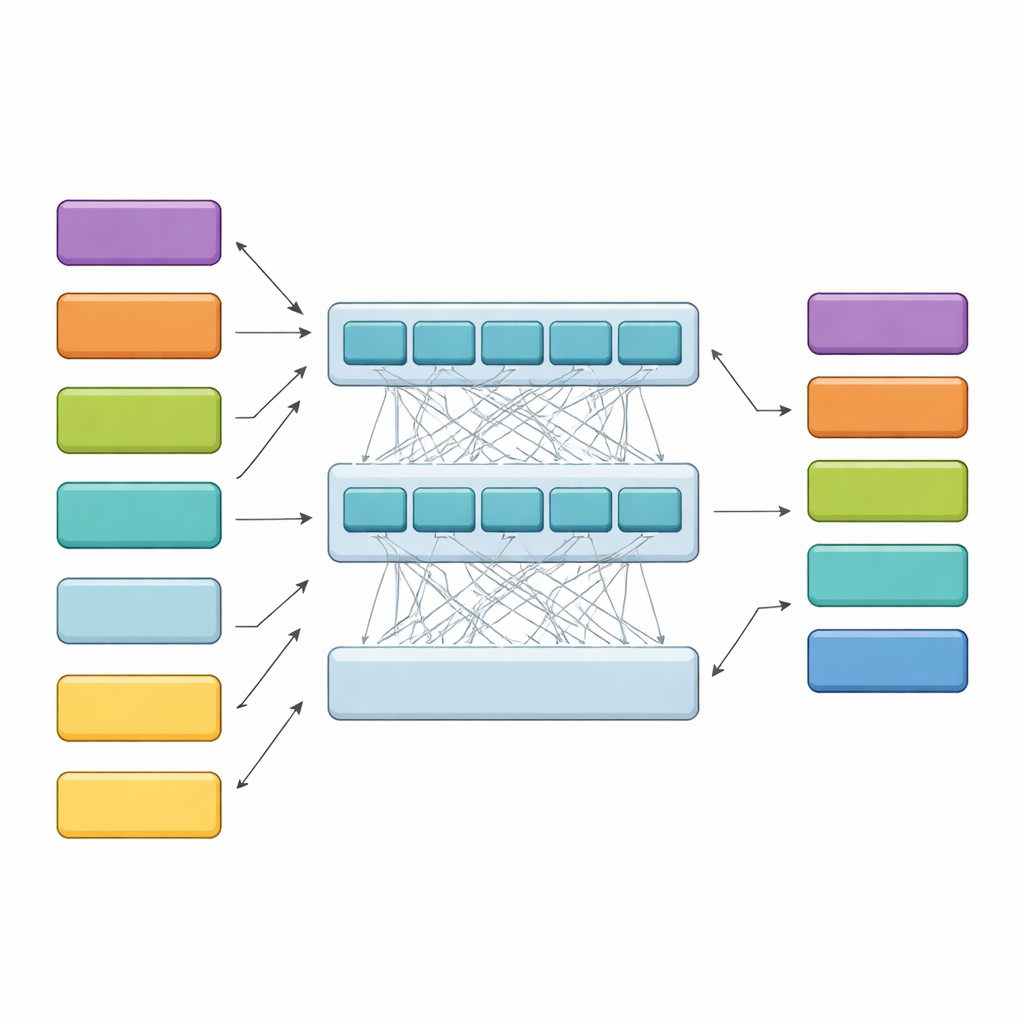
Jak model hierarchiczny czyta długie orzeczenia
HiCoBERT podchodzi do każdego orzeczenia w dwóch etapach. Najpierw traktuje każdy fragment tekstu jak mini-dokument i używa wersji modelu BERT dostosowanej do domeny prawnej (LegalBERT), aby zrozumieć jego lokalne znaczenie. To generuje zwarty wektorowy skrót każdego fragmentu. Następnie, zamiast na tym poprzestać, cały ciąg skrótów fragmentów jest przetwarzany przez dodatkowy Transformer i dwukierunkową sieć rekurencyjną. Warstwy te pozwalają modelowi porównywać każdy fragment z resztą dokumentu, ucząc się, jak wczesne tło, środkowe zagadnienia i późniejsze uzasadnienia zwykle ze sobą się wiążą. Na końcu klasyfikator przypisuje każdemu fragmentowi jedną z czterech funkcjonalnych ról, kierując się zarówno jego własną treścią, jak i kontekstem sąsiednich fragmentów.
Pokonanie konkurentów i weryfikacja rozumowania modelu
W testach na zbiorze LeJA HiCoBERT osiągnął około 80% dokładności i makro-F1 na poziomie 0,70, przewyższając silne alternatywy takie jak Longformer, BigBird, LongT5 oraz model LegalBERT w parze z tradycyjnym taggerem sekwencyjnym. W porównaniu z nowoczesnymi dużymi modelami językowymi uruchamianymi przez promptowanie — w tym GPT-4o, Gemini Pro i DeepSeek-V3 — również wypadł korzystnie, szczególnie gdy oceniano wydajność we wszystkich czterech typach sekcji zamiast tylko dominującej części „uzasadnienie”. Autorzy następnie zbadali, jak HiCoBERT podejmuje decyzje, używając narzędzi wyjaśnialnej sztucznej inteligencji. Analizy na poziomie tokenów pokazały, że model skupia się na szczegółach faktycznych w tle, zwrotach ramujących pytania w sekcji zagadnień, cytowaniach prawnych i argumentacyjnym języku w uzasadnieniu oraz sformułowaniach rozstrzygających w części dotyczącej orzeczenia. Testy na poziomie segmentów ujawniły, że pobliskie fragmenty, zwłaszcza tuż przed rozstrzygnięciem, silnie wpływają na sposób etykietowania sekcji, potwierdzając znaczenie kontekstu.
Testowanie odporności ponad granicami i perspektywy
Aby sprawdzić, czy podejście generalizuje poza Pakistanem, badacze ocenili HiCoBERT na LegalSeg, publicznym zbiorze orzeczeń indyjskich o podobnych rolach retorycznych. Bez ponownego trenowania model wciąż radził sobie stosunkowo dobrze, szczególnie w kluczowych sekcjach uzasadnienia i rozstrzygnięcia, choć miał większe trudności z krótkimi i niejednoznacznymi formułowaniami zagadnień. Sugeruje to, że model wychwytuje szeroko wspólne wzorce pisma prawniczego, podczas gdy dokładniejsze wykrywanie zagadnień może zależeć od lokalnego stylu redakcyjnego. Autorzy zwracają też uwagę na praktyczne ograniczenia: stała maksymalna długość dokumentu, silna nierównowaga klas na korzyść części uzasadniającej oraz sporadyczne niejasności przy granicach sekcji — co motywuje do przyszłych usprawnień, takich jak adaptacyjne okna kontekstowe i uwzględniające granice mechanizmy uwagi.
Co to oznacza dla codziennego użycia AI w prawie
Mówiąc prosto, badanie pokazuje, że traktowanie orzeczeń sądowych jako starannie uporządkowanych opowieści, a nie niepodzielnego tekstu, daje dokładniejsze i bardziej interpretowalne narzędzia AI. Hierarchiczna konstrukcja HiCoBERT pozwala dzielić długie orzeczenia na sensowne części odpowiadające temu, jak prawnicy i sędziowie naturalnie myślą o sprawach. Ułatwia to budowę systemów, które szybko wydobywają fakty, izolują zagadnienia, śledzą tok rozumowania lub przechodzą bezpośrednio do rozstrzygnięcia. W miarę dojrzewania takich modeli i ich rozszerzania na inne sądy i języki, mogą stać się istotną podstawą dla przeszukiwalnych archiwów prawnych, przejrzystych narzędzi wspomagających decyzje oraz bardziej uczciwych i zrozumiałych zastosowań AI w systemie wymiaru sprawiedliwości.
Cytowanie: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
Słowa kluczowe: przetwarzanie języka naturalnego w prawie, segmentacja orzeczeń sądowych, hierarchiczne transformatory, wyjaśnialna sztuczna inteligencja, Sąd Najwyższy Pakistanu