Clear Sky Science · pt
HiCoBERT: uma estrutura hierárquica baseada em transformers para segmentação de trechos de decisões judiciais do Paquistão com insights XAI em múltiplos níveis
Por que dividir decisões judiciais em partes importa
Quando juízes redigem decisões, costumam contar uma história longa e densa: primeiro o contexto, depois as questões, então páginas de fundamentação e, finalmente, a decisão. Para advogados, cidadãos ou ferramentas de software que tentam localizar um trecho-chave, esse muro de texto pode ser opressor. Este artigo apresenta o HiCoBERT, uma nova estrutura de inteligência artificial que automaticamente separa decisões do Supremo Tribunal do Paquistão em quatro partes significativas — contexto, questões, fundamentação e decisão — para que a informação jurídica possa ser pesquisada, resumida e analisada com mais precisão.
Transformando narrativas jurídicas em blocos claros
Os autores partem de uma observação simples: a maioria dos modelos de linguagem modernos lê um documento como um fluxo plano de palavras, ignorando o fato de que as decisões são naturalmente organizadas em etapas. Pesquisas anteriores mostraram que respeitar essa estrutura interna — separar fatos da análise jurídica, por exemplo — melhora tarefas como sumarização e previsão de desfecho. Com base nessa ideia, a equipe define um modelo prático de quatro partes que corresponde à forma como muitos tribunais realmente redigem: uma exposição concisa do caso, os pontos que o tribunal deve decidir, as razões detalhadas e a decisão final. O objetivo é ensinar um sistema de IA a recuperar essa estrutura automaticamente, mesmo quando não há cabeçalhos ou sinais visuais presentes.
Construindo um novo conjunto de dados a partir do tribunal superior do Paquistão
Para treinar e testar o método, os autores curaram o LeJA, um novo conjunto de dados de decisões do Supremo Tribunal do Paquistão. Após remover metadados como números de processo e datas, especialistas jurídicos rotularam cada decisão segundo as quatro seções funcionais, assegurando que as partes estivessem ordenadas, sem sobreposição e consistentes entre documentos. Como decisões judiciais são bem mais longas do que o que modelos de IA padrão conseguem ler de uma vez, os textos foram ainda divididos em blocos menores de cerca de 128 tokens (aproximadamente várias frases), usando uma estratégia dinâmica que preserva frases inteiras enquanto mantém o custo computacional manejável.
Como o modelo hierárquico lê decisões longas
O HiCoBERT aborda cada decisão em duas etapas. Primeiro, trata cada bloco de texto como um mini-documento e usa uma versão do BERT adaptada ao domínio jurídico (LegalBERT) para captar seu sentido local. Isso produz um resumo vetorial compacto de cada bloco. Em seguida, em vez de parar aí, alimenta toda a sequência de resumos de blocos em um Transformer adicional e em uma rede recorrente bidirecional. Essas camadas permitem que o modelo compare cada bloco com o restante do documento, aprendendo como o contexto inicial, as questões do meio e a fundamentação tardia normalmente se relacionam entre si. Um classificador final então atribui uma das quatro funções a cada bloco, guiado tanto pelo conteúdo próprio quanto pelos vizinhos.
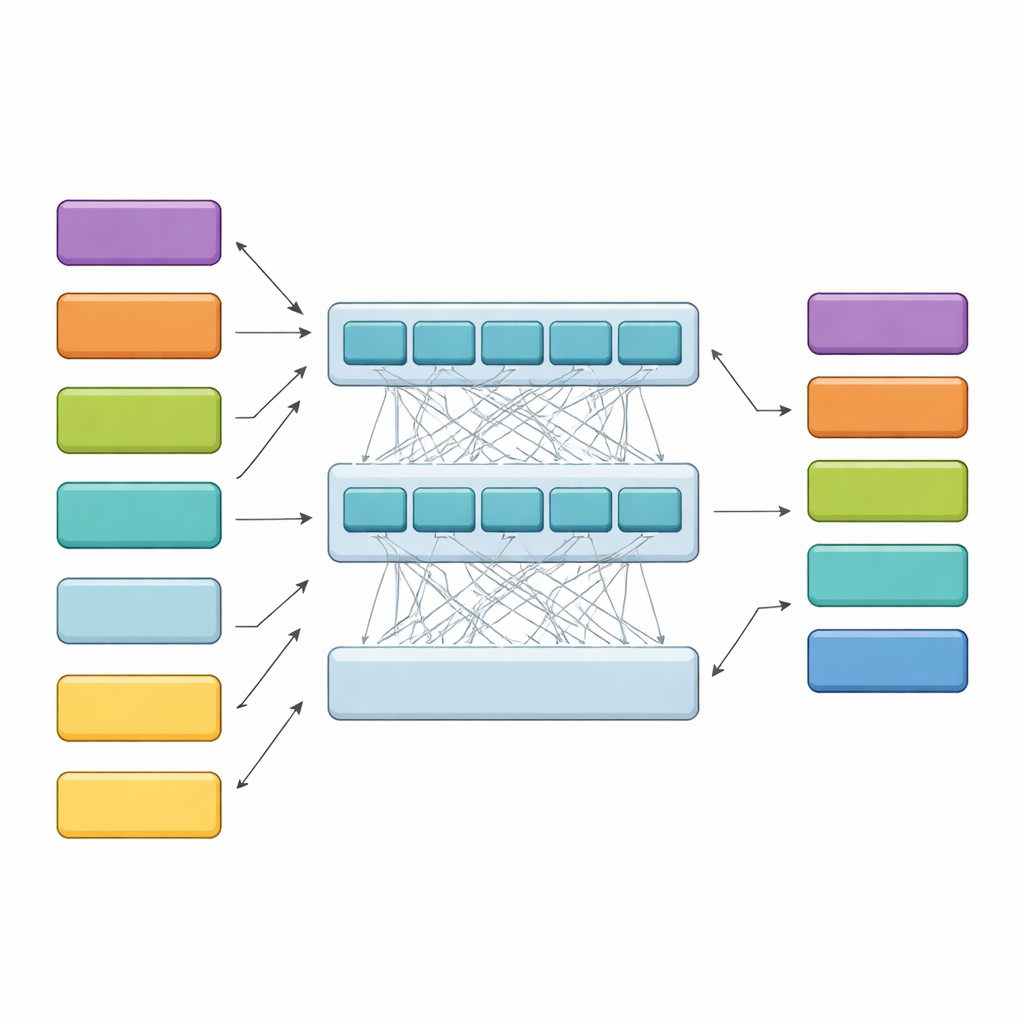
Superando modelos rivais e verificando o raciocínio do modelo
Em testes no conjunto LeJA, o HiCoBERT alcançou cerca de 80% de acurácia e uma macro-F1 de 0,70, superando alternativas fortes como Longformer, BigBird, LongT5 e um modelo LegalBERT emparelhado com um etiquetador de sequência tradicional. Também teve desempenho favorável em comparação a modernos grandes modelos de linguagem usados por prompt, incluindo GPT-4o, Gemini Pro e DeepSeek-V3, especialmente ao equilibrar o desempenho nas quatro categorias em vez de focar apenas na dominante seção de “fundamentação”. Os autores então sondaram como o HiCoBERT toma suas decisões usando ferramentas de IA explicável. Análises ao nível de token mostraram que o modelo foca em detalhes factuais no contexto, frases de enquadramento de questões nas questões, citações legais e linguagem argumentativa na fundamentação, e expressões decisivas na sentença. Testes ao nível de segmento revelaram que blocos próximos, especialmente os imediatamente anteriores à decisão, influenciam fortemente a rotulagem de uma seção, confirmando a importância do contexto.
Testando robustez além das fronteiras e olhando adiante
Para verificar se a abordagem generaliza além do Paquistão, os pesquisadores avaliaram o HiCoBERT no LegalSeg, um conjunto público de decisões indianas com papéis retóricos semelhantes. Sem retreinamento, o modelo manteve desempenho razoável, especialmente nas seções centrais de fundamentação e decisão, embora tenha tido mais dificuldade com as enunciações breves e ambíguas das questões. Isso sugere que o modelo capta padrões amplamente compartilhados da redação jurídica, enquanto a detecção mais fina das questões pode depender do estilo local de redação. Os autores também apontam limitações práticas: um comprimento máximo fixo de documento, forte desbalanço de classes em favor da seção de fundamentação e confusões ocasionais próximas às fronteiras entre seções, o que motiva melhorias futuras como janelas de contexto adaptativas e atenção consciente de limites.
O que isso significa para o uso cotidiano de IA jurídica
De forma direta, o estudo mostra que tratar decisões judiciais como histórias cuidadosamente ordenadas, em vez de texto indiferenciado, produz ferramentas de IA mais precisas e interpretáveis. O desenho hierárquico do HiCoBERT permite que decisões longas sejam divididas em partes significativas que correspondem à forma como advogados e juízes naturalmente pensam sobre os casos. Isso pode facilitar a construção de sistemas que rapidamente evidenciem os fatos, isolem as questões, tracem a fundamentação ou acessem diretamente a sentença. À medida que esses modelos amadurecem e são estendidos para outros tribunais e línguas, eles podem se tornar uma base importante para arquivos jurídicos pesquisáveis, ferramentas de apoio à decisão transparentes e aplicações de IA mais justas e compreensíveis no sistema de justiça.
Citação: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
Palavras-chave: processamento de linguagem natural jurídico, segmentação de decisões judiciais, transformers hierárquicos, IA explicável, Supremo Tribunal do Paquistão