Clear Sky Science · es
HiCoBERT: un marco jerárquico basado en transformadores para la segmentación de secciones en sentencias legales de Pakistán con conocimientos XAI multinivel
Por qué importa dividir las decisiones judiciales en partes
Cuando los jueces redactan decisiones, por lo general cuentan una historia larga y densa: primero los antecedentes, luego las cuestiones, después páginas de razonamiento y, por último, la resolución. Para abogados, ciudadanos o herramientas informáticas que buscan un pasaje clave, esta pared de texto puede resultar abrumadora. Este artículo presenta HiCoBERT, un nuevo marco de inteligencia artificial que segmenta automáticamente las sentencias del Tribunal Supremo de Pakistán en cuatro partes significativas —antecedentes, cuestiones, motivos y decisión— para que la información legal pueda buscarse, resumirse y analizarse con mayor precisión.
Convertir relatos legales en bloques claros
Los autores parten de una observación sencilla: la mayoría de los modelos de lenguaje modernos leen un documento como un flujo plano de palabras, sin tener en cuenta que las sentencias están naturalmente organizadas por etapas. Investigaciones anteriores demostraron que respetar esta estructura interna —separar, por ejemplo, los hechos del análisis jurídico— mejora tareas como la elaboración de resúmenes y la predicción de resultados. Partiendo de esta idea, el equipo define una plantilla práctica de cuatro partes que coincide con la forma en que muchos tribunales redactan: una declaración concisa del caso, los puntos que el tribunal debe decidir, los motivos detallados y la decisión final. Su objetivo es enseñar a un sistema de IA a recuperar esta estructura automáticamente, incluso cuando no haya encabezados ni pistas visuales.
Construir un nuevo conjunto de datos a partir del tribunal superior de Pakistán
Para entrenar y evaluar su método, los autores crearon LeJA, un nuevo conjunto de datos de sentencias del Tribunal Supremo de Pakistán. Tras eliminar metadatos como números de expediente y fechas, expertos legales etiquetaron cada sentencia según las cuatro secciones funcionales, asegurando que las partes estuvieran ordenadas, no se solaparan y fueran consistentes entre documentos. Debido a que las decisiones judiciales son mucho más extensas de lo que los modelos de IA estándar pueden procesar de una sola vez, los textos se dividieron además en fragmentos más pequeños de aproximadamente 128 tokens (a grosso modo varias oraciones), usando una estrategia dinámica que mantiene las oraciones intactas y a la vez mantiene la carga computacional manejable.
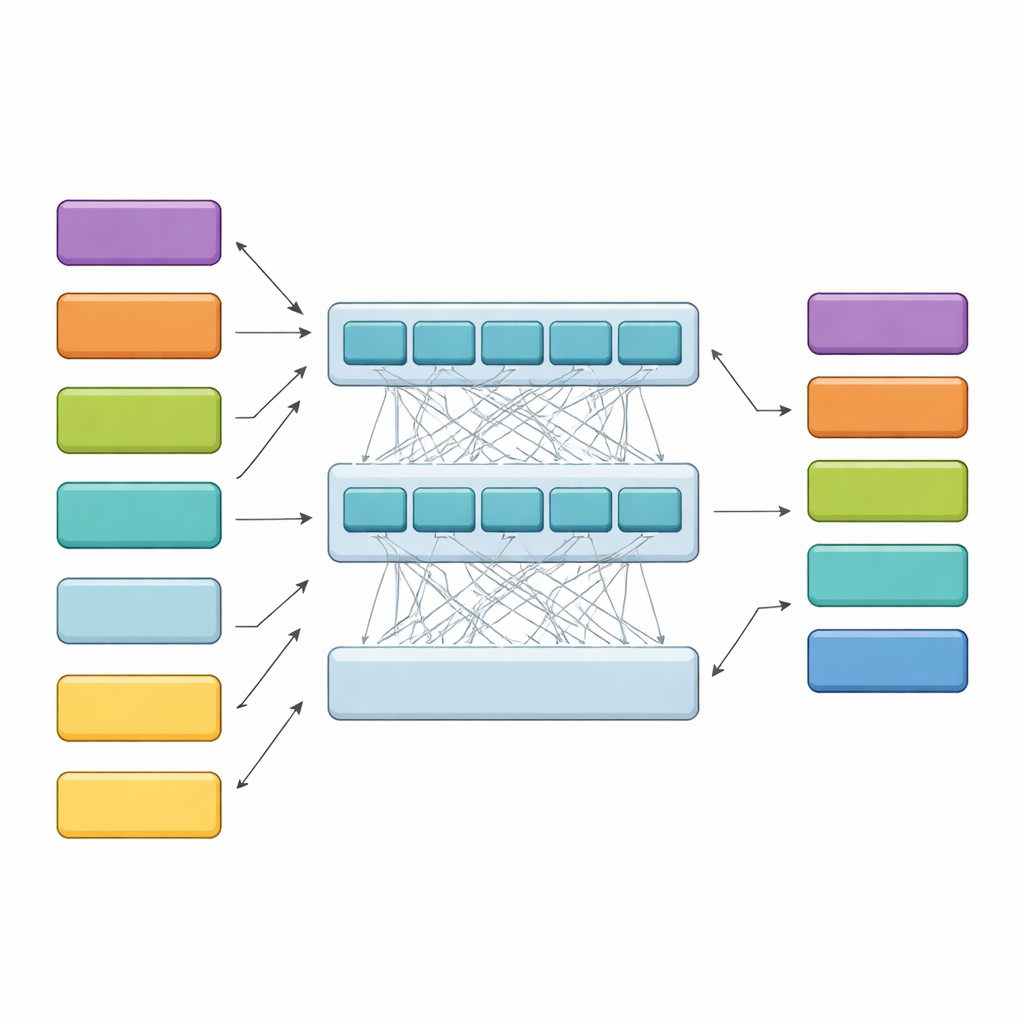
Cómo el modelo jerárquico lee sentencias largas
HiCoBERT aborda cada sentencia en dos etapas. Primero, trata cada fragmento de texto como un mini-documento y utiliza una versión de BERT adaptada al dominio legal (LegalBERT) para comprender su significado local. Esto produce un resumen vectorial compacto de cada fragmento. Segundo, en lugar de detenerse ahí, alimenta toda la secuencia de resúmenes de fragmentos a un transformador adicional y a una red recurrente bidireccional. Estas capas permiten que el modelo compare cada fragmento con el resto del documento, aprendiendo cómo los antecedentes tempranos, las cuestiones a media altura y los razonamientos tardíos suelen relacionarse entre sí. Un clasificador final asigna entonces una de las cuatro funciones a cada fragmento, guiado tanto por su contenido como por sus vecinos.
Superar modelos rivales y comprobar el razonamiento del modelo
En pruebas sobre el conjunto LeJA, HiCoBERT alcanzó aproximadamente un 80 % de exactitud y una puntuación macro-F1 de 0,70, superando alternativas potentes como Longformer, BigBird, LongT5 y un modelo LegalBERT emparejado con un etiquetador de secuencias tradicional. También se comparó favorablemente con modelos de lenguaje grandes modernos ejecutados mediante prompts, incluidos GPT-4o, Gemini Pro y DeepSeek-V3, especialmente cuando se equilibraba el rendimiento en las cuatro categorías en lugar de centrarse solo en la dominante sección de “motivos”. Los autores examinaron a continuación cómo HiCoBERT toma sus decisiones usando herramientas de IA explicable. Los análisis a nivel de token mostraron que el modelo se centra en detalles fácticos en los antecedentes, en frases que enmarcan la cuestión en las secciones de cuestiones, en citas legales y en el lenguaje argumentativo en los motivos, y en frases decisivas en la resolución. Las pruebas a nivel de segmento revelaron que los fragmentos cercanos, especialmente los justo antes de la decisión, influyen fuertemente en cómo se etiqueta una sección, confirmando la importancia del contexto.
Probar la robustez a través de fronteras y perspectivas futuras
Para ver si su enfoque se generaliza más allá de Pakistán, los investigadores evaluaron HiCoBERT en LegalSeg, un conjunto de datos público de sentencias indias con roles retóricos similares. Sin volver a entrenar, el modelo siguió rindiendo razonablemente bien, sobre todo en las secciones centrales de razonamiento y decisión, aunque tuvo más dificultades con las declaraciones breves y ambiguas de las cuestiones. Esto sugiere que el modelo captura patrones de redacción legal ampliamente compartidos, mientras que la detección más fina de cuestiones puede depender del estilo local de redacción. Los autores también señalan limitaciones prácticas: una longitud máxima fija de documento, un fuerte desequilibrio de clases hacia la sección de motivos y confusiones ocasionales cerca de los límites de sección, todo lo cual motiva mejoras futuras como ventanas de contexto adaptativas y atención sensible a los límites.
Qué significa esto para el uso cotidiano de la IA legal
En términos sencillos, el estudio muestra que tratar las sentencias judiciales como historias cuidadosamente ordenadas en lugar de texto indiferenciado produce herramientas de IA más precisas e interpretables. El diseño jerárquico de HiCoBERT permite dividir decisiones largas en partes significativas que coinciden con la forma en que abogados y jueces piensan naturalmente sobre los casos. Esto puede facilitar la creación de sistemas que exponenen rápidamente los hechos, aislen las cuestiones, sigan el razonamiento o salten directamente a la resolución. A medida que estos modelos maduren y se extiendan a otros tribunales e idiomas, podrían convertirse en una base importante para archivos legales buscables, herramientas de apoyo a la decisión transparentes y aplicaciones de IA en la justicia más justas y comprensibles.
Cita: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
Palabras clave: procesamiento del lenguaje natural legal, segmentación de sentencias judiciales, transformadores jerárquicos, inteligencia artificial explicable, Tribunal Supremo de Pakistán