Clear Sky Science · ar
HiCoBERT: إطار هرمي قائم على الترنسفورمر لتقسيم أقسام أحكام باكستان مع رؤى XAI متعددة المستويات
لماذا يهم تفكيك قرارات المحاكم إلى أجزاء
عندما يكتب القضاة قراراتهم، عادة ما يروون قصة طويلة وكثيفة: أولاً الخلفية، ثم القضايا، ثم صفحات من التعليل، وأخيرًا الحكم. بالنسبة للمحامين أو المواطنين أو الأدوات البرمجية التي تحاول العثور على مقطع مهم، يمكن أن يكون هذا الجدار النصي مربكًا. تقدّم هذه الورقة HiCoBERT، إطارًا جديدًا للذكاء الاصطناعي يقوم تلقائيًا بتقطيع أحكام المحكمة العليا في باكستان إلى أربعة أجزاء ذات معنى — الخلفية، القضايا، الأسباب، والحكم — بحيث يمكن البحث عن المعلومات القانونية وتلخيصها وتحليلها بدقة أكبر.
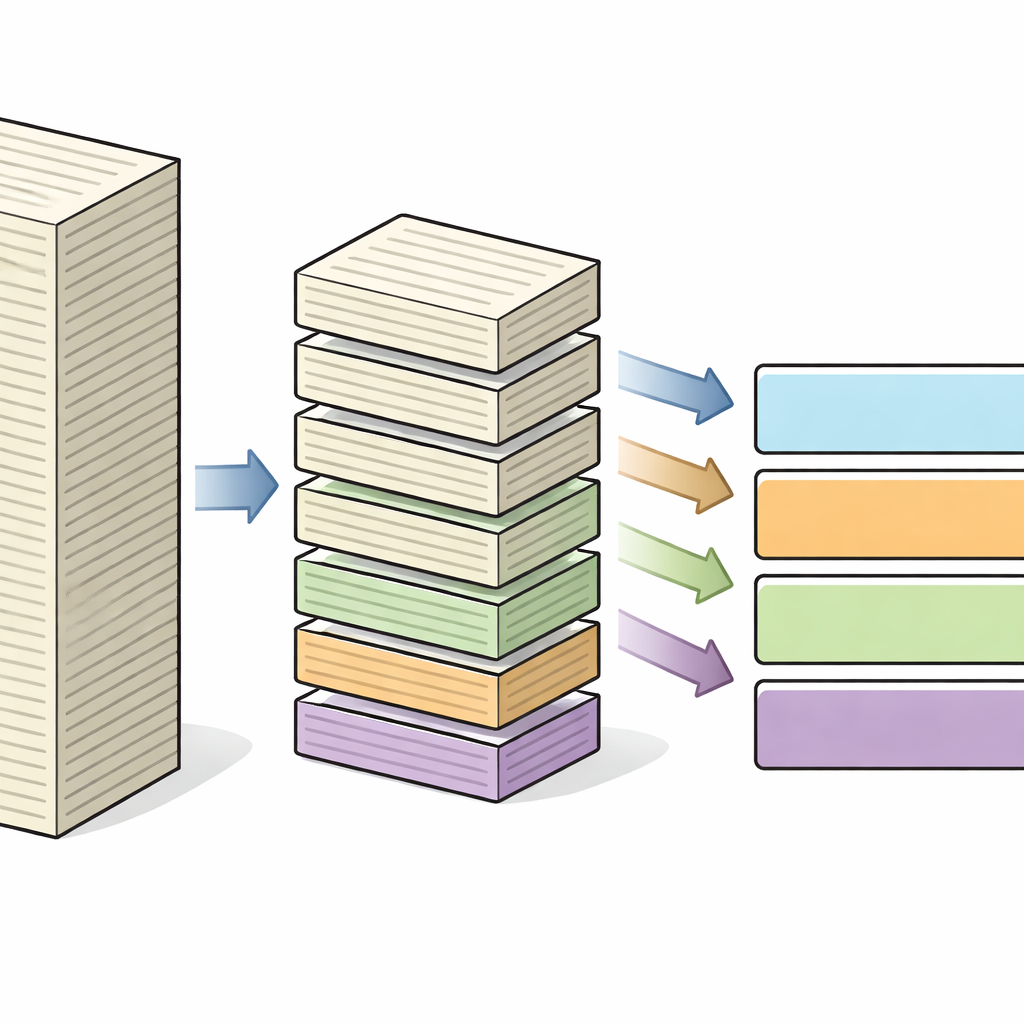
تحويل القصص القانونية إلى لبنات واضحة
ينطلق المؤلفون من ملاحظة بسيطة: معظم نماذج اللغة الحديثة تقرأ المستند كسلسلة مسطحة من الكلمات، متجاهلة حقيقة أن الأحكام منظمة بطبيعتها على مراحل. أظهرت أبحاث سابقة أن احترام هذا الهيكل الداخلي — فصل الوقائع عن التحليل القانوني، على سبيل المثال — يحسّن مهام مثل التلخيص والتنبؤ بالنتائج. وبناءً على هذه الفكرة، يحدد الفريق قالبًا عمليًا من أربعة أجزاء يتوافق مع طريقة كتابة كثير من المحاكم بالفعل: بيان موجز للقضية، النقاط التي يتعين على المحكمة البت فيها، الأسباب التفصيلية، والقرار النهائي. هدفهم هو تعليم نظام ذكاء اصطناعي لاستعادة هذا الهيكل تلقائيًا، حتى عندما لا توجد عناوين أو إشارات بصرية.
بناء مجموعة بيانات جديدة من محكمة باكستان العليا
لتدريب واختبار طريقتهم، جمع المؤلفون LeJA، مجموعة بيانات جديدة من أحكام المحكمة العليا لباكستان. بعد إزالة البيانات الوصفية مثل أرقام القضايا والتواريخ، قام خبراء قانونيون بوسم كل حكم وفقًا للأقسام الوظيفية الأربعة، مع ضمان أن تكون الأجزاء مرتبة وغير متداخلة ومتسقة عبر المستندات. وبما أن قرارات المحاكم أطول بكثير مما تستطيع نماذج الذكاء الاصطناعي القياسية قراءته دفعة واحدة، فقد تم تقسيم النصوص إلى قطع أصغر من حوالي 128 توكنًا (تقريبًا عدة جمل)، باستخدام استراتيجية ديناميكية تحافظ على سلامة الجمل مع إبقاء الحسابات في مستوى معقول.
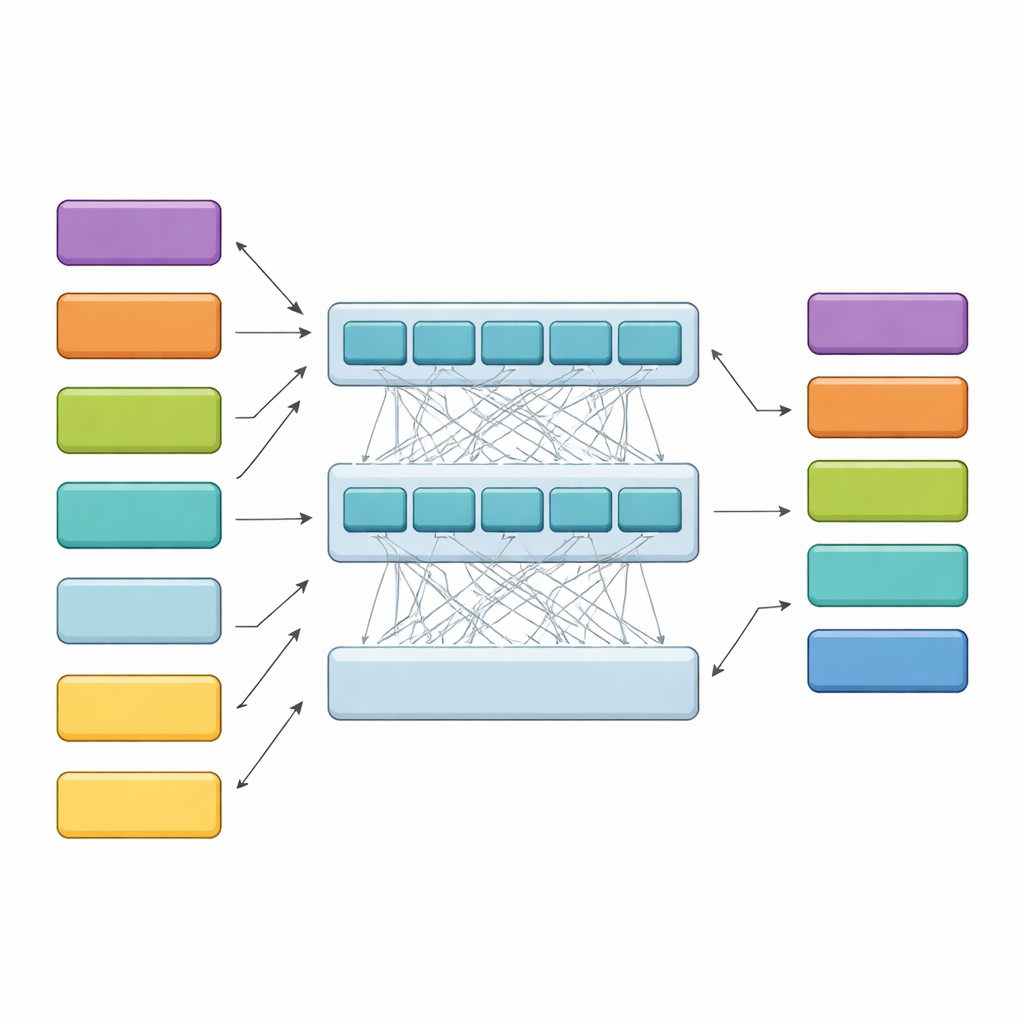
كيف يقرأ النموذج الهرمي الأحكام الطويلة
يتعامل HiCoBERT مع كل حكم على مرحلتين. أولًا، يعامل كل قطعة نصية كمستند مصغر ويستخدم نسخة متخصصة في المجال القانوني من نموذج BERT (LegalBERT) لفهم معناها المحلي. هذا ينتج ملخصًا متجهًا مدمجًا لكل قطعة. ثانيًا، بدلًا من التوقف عند هذا الحد، يغذي تسلسل ملخصات القطع بأكمله إلى ترنسفورمر إضافي وشبكة تكرارية ثنائية الاتجاه. تتيح هذه الطبقات للنموذج مقارنة كل قطعة مع بقية المستند، متعلمًا كيف ترتبط الخلفية المبكرة والقضايا المتوسطة والتعليل المتأخر عادة ببعضها البعض. ثم يقوم مصنف نهائي بتعيين أحد الأدوار الوظيفية الأربعة لكل قطعة، موجَّهًا بمحتواها وسياقها المجاور.
تفوق على النماذج المنافسة وفحص أسباب قرارات النموذج
في الاختبارات على مجموعة LeJA، حقق HiCoBERT دقة تقارب 80% ودرجة macro-F1 بمقدار 0.70، متفوقًا على بدائل قوية مثل Longformer وBigBird وLongT5 ونموذج LegalBERT مقترنًا بوسم تسلسلي تقليدي. كما قارن أداءه إيجابيًا مع نماذج اللغة الكبيرة الحديثة المشغّلة عبر الاستدعاءات، بما في ذلك GPT-4o وGemini Pro وDeepSeek-V3، لا سيما عند موازنة الأداء عبر جميع أنواع الأقسام الأربعة بدلًا من التركيز على قسم "الأسباب" المسيطر. ثم فحص المؤلفون كيفية اتخاذ HiCoBERT لقراراته باستخدام أدوات الذكاء الاصطناعي القابل للتفسير. أظهرت تحليلات على مستوى التوكن أن النموذج يركز على تفاصيل واقعية في الخلفية، وعبارات تأطير السؤال في القضايا، والاقتباسات القانونية والعبارات الجدلية في الأسباب، وعبارات الحسم في الحكم. وكشفت اختبارات على مستوى القطع أن القطع المجاورة، خاصةً تلك التي تسبق الحكم مباشرة، تؤثر بقوة في كيفية وسم القسم، مما يؤكد أهمية السياق.
اختبار المتانة عبر الحدود ونظرة مستقبلية
للاطلاع على ما إذا كانت طريقتهم تعمم خارج باكستان، قيّم الباحثون HiCoBERT على LegalSeg، مجموعة بيانات عامة لأحكام هندية ذات أدوار بلاغية مشابهة. دون إعادة تدريب، حافظ النموذج على أداء معقول، لا سيما في أقسام التعليل والقرار الأساسية، رغم أنه واجه صعوبة أكبر مع بيانات القضايا القصيرة والغموض في صياغتها. يشير هذا إلى أن النموذج يلتقط أنماط كتابة قانونية مشتركة على نطاق واسع، بينما قد تعتمد القدرة الدقيقة على اكتشاف القضايا على أسلوب الصياغة المحلي. كما يشير المؤلفون إلى قيود عملية: طول مستند أقصى ثابت، وعدم توازن قوي بين الفئات لصالح قسم التعليل، والارتباك العرضي قرب حدود الأقسام، وكلها تحفز تحسينات مستقبلية مثل نوافذ سياقية تكيفية وانتباه واعٍ بالحدود.
ماذا يعني هذا للاستخدام اليومي للذكاء الاصطناعي القانوني
بعبارات بسيطة، تظهر الدراسة أن التعامل مع أحكام المحاكم كقصص مرتبة بعناية بدلًا من نص غير مميز يؤدي إلى أدوات ذكاء اصطناعي أكثر دقة وقابلة للتفسير. يتيح التصميم الهرمي لـ HiCoBERT تقسيم القرارات الطويلة إلى أجزاء ذات معنى تتوافق مع طريقة تفكير المحامين والقضاة في القضايا. يمكن أن يسهل هذا بناء أنظمة تُظهر بسرعة الوقائع، وتعزل القضايا، وتتبع التعليل، أو تقفز مباشرة إلى الحكم. ومع نضوج هذه النماذج وتمديدها إلى محاكم ولغات أخرى، قد تصبح أساسًا مهمًا لأرشيفات قانونية قابلة للبحث، وأدوات دعم قرار شفافة، وتطبيقات ذكاء اصطناعي أكثر عدلاً وفهمًا في نظام العدالة.
الاستشهاد: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
الكلمات المفتاحية: معالجة اللغة الطبيعية القانونية, تقسيم أحكام المحاكم, ترنسفورمرات هرمية, الذكاء الاصطناعي القابل للتفسير, المحكمة العليا لباكستان