Clear Sky Science · de
HiCoBERT: ein hierarchisches Transformer-basiertes Framework zur Segmentierung von Abschnitten in pakistanischen Gerichtsentscheidungen mit mehrstufigen XAI-Einblicken
Warum das Aufteilen von Gerichtsentscheidungen in Abschnitte wichtig ist
Wenn Richter Entscheidungen verfassen, erzählen sie meist eine lange, dichte Geschichte: zuerst den Hintergrund, dann die Streitpunkte, anschließend Seiten mit Begründungen und schließlich den Spruch. Für Anwälte, Bürger oder Softwarewerkzeuge, die eine Schlüsselstelle suchen, kann diese Textwand überwältigend sein. Dieses Papier stellt HiCoBERT vor, ein neues KI-Framework, das automatisch Urteile des Obersten Gerichtshofs von Pakistan in vier sinnvolle Teile zerlegt – Hintergrund, Streitpunkte, Begründungen und Entscheidung –, sodass juristische Informationen gezielter durchsucht, zusammengefasst und analysiert werden können.
Juristische Darstellungen in klare Bausteine verwandeln
Die Autorinnen und Autoren beginnen mit einer einfachen Beobachtung: Die meisten modernen Sprachmodelle lesen ein Dokument als flachen Strom von Wörtern und ignorieren dabei, dass Urteile natürlicherweise in Stadien organisiert sind. Frühere Forschung zeigte, dass die Beachtung dieser inneren Struktur – etwa die Trennung von Sachverhalt und rechtlicher Analyse – Aufgaben wie Zusammenfassung und Vorhersage von Entscheidungen verbessert. Aufbauend auf dieser Idee definiert das Team eine praktische Vier-teil-Vorlage, die dem Schreibstil vieler Gerichte entspricht: eine knappe Darstellung des Falls, die Fragen, die das Gericht entscheiden muss, die ausführlichen Begründungen und die abschließende Entscheidung. Ihr Ziel ist es, einem KI-System beizubringen, diese Struktur automatisch wiederherzustellen, selbst wenn keine Überschriften oder visuellen Hinweise vorhanden sind.
Erstellung eines neuen Datensatzes aus Pakistans oberstem Gericht
Um ihre Methode zu trainieren und zu testen, stellten die Autorinnen und Autoren LeJA zusammen, einen neuen Datensatz mit Urteilen des Obersten Gerichtshofs von Pakistan. Nach dem Entfernen von Metadaten wie Aktenzeichen und Daten markierten Rechtsexperten jedes Urteil gemäß den vier funktionalen Abschnitten und stellten sicher, dass die Teile geordnet, nicht überlappend und über die Dokumente hinweg konsistent waren. Da Gerichtsentscheidungen deutlich länger sind als das, was Standard-KI-Modelle in einem Durchgang verarbeiten können, wurden die Texte zusätzlich in kleinere Abschnitte von etwa 128 Tokens (ungefähr mehrere Sätze) unterteilt, wobei eine dynamische Strategie verwendet wurde, die Sätze intakt hält und zugleich die Berechnung handhabbar macht.
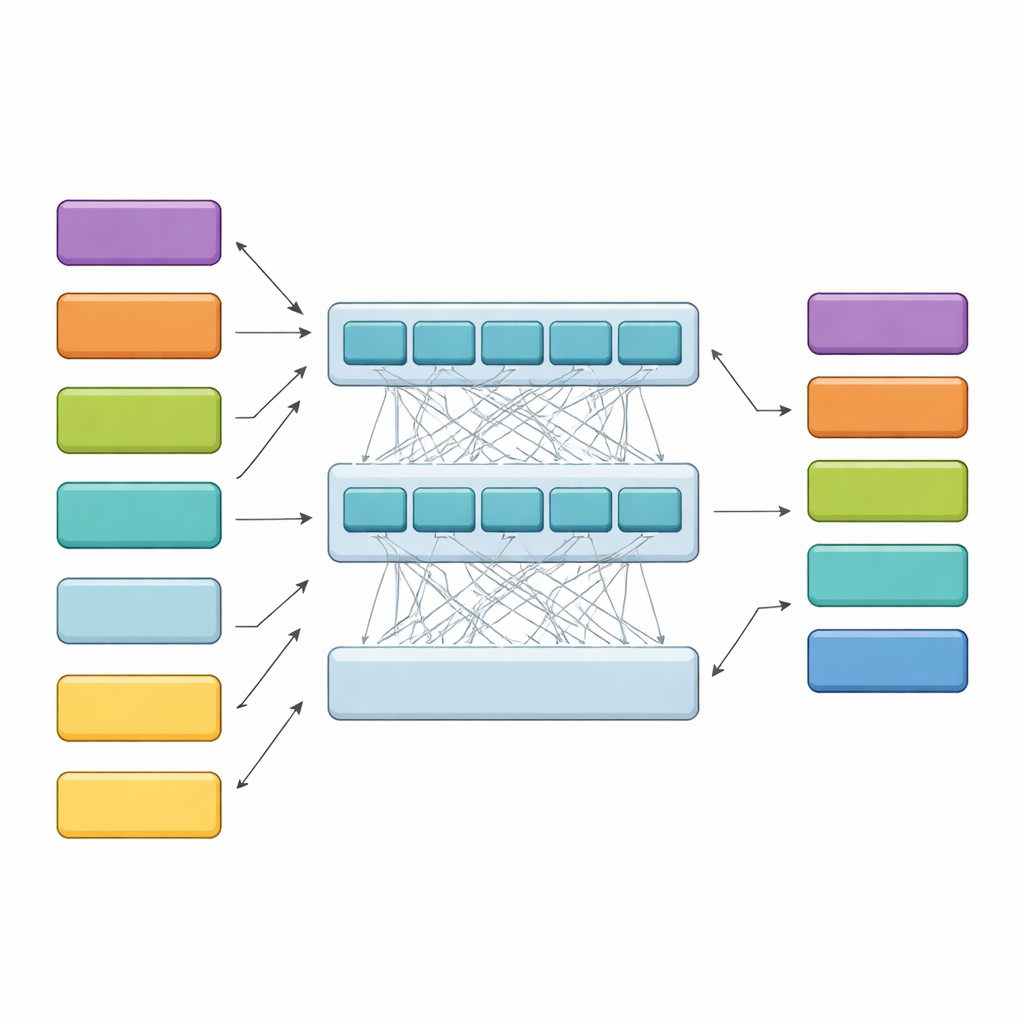
Wie das hierarchische Modell lange Urteile liest
HiCoBERT nähert sich jedem Urteil in zwei Stufen. Zuerst behandelt es jeden Textabschnitt wie ein Mini-Dokument und nutzt eine juristische Domain-Version des BERT-Modells (LegalBERT), um seine lokale Bedeutung zu erfassen. Das erzeugt eine kompakte Vektor-Zusammenfassung jedes Abschnitts. Anschließend, anstatt dort zu stoppen, gibt es die gesamte Sequenz dieser Abschnitts-Zusammenfassungen in einen zusätzlichen Transformer und ein bidirektionales rekurrentes Netzwerk. Diese Schichten erlauben dem Modell, jeden Abschnitt im Kontext des restlichen Dokuments zu vergleichen und zu lernen, wie frühere Hintergrundteile, mittlere Streitpunkte und spätere Begründungen typischerweise zueinander in Beziehung stehen. Ein abschließender Klassifikator weist dann jedem Abschnitt eine der vier funktionalen Rollen zu, geleitet von seinem eigenen Inhalt und dem seiner Nachbarabschnitte.
Stärkere Leistung als konkurrierende Modelle und Prüfung der Modellgründe
In Tests am LeJA-Datensatz erzielte HiCoBERT etwa 80 % Genauigkeit und eine Macro-F1 von 0,70 und übertraf damit starke Alternativen wie Longformer, BigBird, LongT5 sowie ein LegalBERT-Modell kombiniert mit einem traditionellen Sequenz-Tagger. Es schnitt auch günstiger ab als moderne große Sprachmodelle, die per Prompt angewandt wurden, darunter GPT-4o, Gemini Pro und DeepSeek-V3, insbesondere wenn die Leistung über alle vier Abschnittstypen hinweg balanciert wurde und nicht nur auf dem dominanten Bereich der "Begründungen". Die Autorinnen und Autoren untersuchten anschließend, wie HiCoBERT seine Entscheidungen trifft, mithilfe von Werkzeugen der erklärbaren KI. Token-ebene Analysen zeigten, dass das Modell sich im Hintergrund auf faktische Details konzentriert, in den Streitpunkten auf frageformende Formulierungen, in den Begründungen auf Rechtszitate und argumentierende Formulierungen und im Spruch auf entscheidungsrelevante Phrasen. Segment-Ebene-Tests enthüllten, dass nahegelegene Abschnitte, besonders unmittelbar vor der Entscheidung, starken Einfluss darauf haben, wie ein Abschnitt etikettiert wird, was die Bedeutung des Kontexts bestätigt.
Robustheit über Grenzen hinweg testen und Ausblick
Um zu prüfen, ob ihr Ansatz über Pakistan hinaus generalisiert, evaluierten die Forschenden HiCoBERT auf LegalSeg, einem öffentlichen Datensatz mit indischen Urteilen mit ähnlichen rhetorischen Rollen. Ohne Nachtraining lief das Modell weiterhin recht gut, besonders bei den zentralen Begründungs- und Entscheidungsabschnitten, obwohl es bei kurzen und mehrdeutigen Streitpunktaussagen größere Schwierigkeiten hatte. Das legt nahe, dass das Modell breit geteilte Muster juristischen Schreibens erfasst, während die feinere Erkennung von Streitpunkten vom lokalen Formulierungsstil abhängen kann. Die Autorinnen und Autoren verweisen außerdem auf praktische Einschränkungen: eine feste maximale Dokumentenlänge, eine starke Klassenungleichheit zugunsten des Begründungsabschnitts und gelegentliche Verwirrung an Abschnittsgrenzen; all dies motiviert künftige Verbesserungen wie adaptive Kontextfenster und grenzbewusste Attention-Mechanismen.
Was das für den Alltagsgebrauch juristischer KI bedeutet
Einfach gesagt zeigt die Studie, dass die Behandlung von Gerichtsentscheidungen als sorgfältig geordnete Geschichten statt als undifferenzierter Text genauere und interpretierbarere KI-Werkzeuge ergibt. Das hierarchische Design von HiCoBERT erlaubt es, lange Entscheidungen in sinnvolle Teile zu zerlegen, die der Denkweise von Anwälten und Richterinnen und Richtern entsprechen. Das kann es erleichtern, Systeme zu bauen, die schnell die Fakten hervorheben, die Streitpunkte isolieren, die Argumentation nachverfolgen oder direkt zum Spruch springen. Wenn solche Modelle reifen und auf andere Gerichte und Sprachen erweitert werden, könnten sie eine wichtige Grundlage für durchsuchbare Rechtsarchive, transparente Entscheidungsunterstützung und fairere, verständlichere Anwendungen von KI im Justizwesen werden.
Zitation: Bibi, M., Rehman, ZU., Awan, K. et al. HiCoBERT: a hierarchical transformer-based framework for Pakistan legal judgment section segmentation with multi-level XAI insights. Sci Rep 16, 11393 (2026). https://doi.org/10.1038/s41598-026-45259-w
Schlüsselwörter: juristische Verarbeitung natürlicher Sprache, Segmentierung von Gerichtsentscheidungen, hierarchische Transformer, erklärbare KI, Oberster Gerichtshof von Pakistan