Clear Sky Science · tr
Bulanık uyarlanabilir doğrusal olmayan MIMO kontrolü: Pekiştirmeli öğrenme modeli kullanan rijit bağlı çokcisimli robotlar
İş Başında Öğrenen Robotlar
Robotlar fabrikaların çevrili hattından çıkarak hastanelere, depolara ve hatta evlerimize giriyor. Bu dağınık ortamlarda yükler değişiyor, zeminler kusursuz düz değil ve insanlar onlara çarpabiliyor. Bu makale, çok eklemli robotlara—örneğin kollar ve yürüyen makineler—çevre belirsiz ve kendi yapıları zamanla değişken olsa bile hareketlerini pürüzsüz, hassas ve kararlı tutma yetisi kazandırmanın yeni bir yolunu araştırıyor.
Geleneksel Robot Kontrolünün Neden Yetersiz Kaldığı
Klasik robot kontrolörleri, yolun her zaman kuru ve düz olduğunu varsayan bir arabadaki hız sabitleyiciye benzer. Her bir eklem, dişli ve kuvvetin ayrıntılı matematiksel modellerine dayanırlar. Oysa gerçek dünyada bir robotun davranışı farklı nesneler taşıdıkça, eklemleri ısındıkça veya tümsek ve itmelerle karşılaştıkça kayma gösterir. Çok eklemli ve güçlü bağlı sistemlerde mükemmel bir model yazmak neredeyse imkânsızdır. Sonuç olarak, tek döngülü standart kontrolörler ve hatta daha gelişmiş çok döngülü şemalar, değişen yükler ve bozucu etkenlerle karşılaştıklarında enerji israfına, yavaş tepkiye veya doğruluk kaybına yol açabilir.
Çok Eklemli Robotlar İçin Öğrenen Bir Kontrol “Beyni”
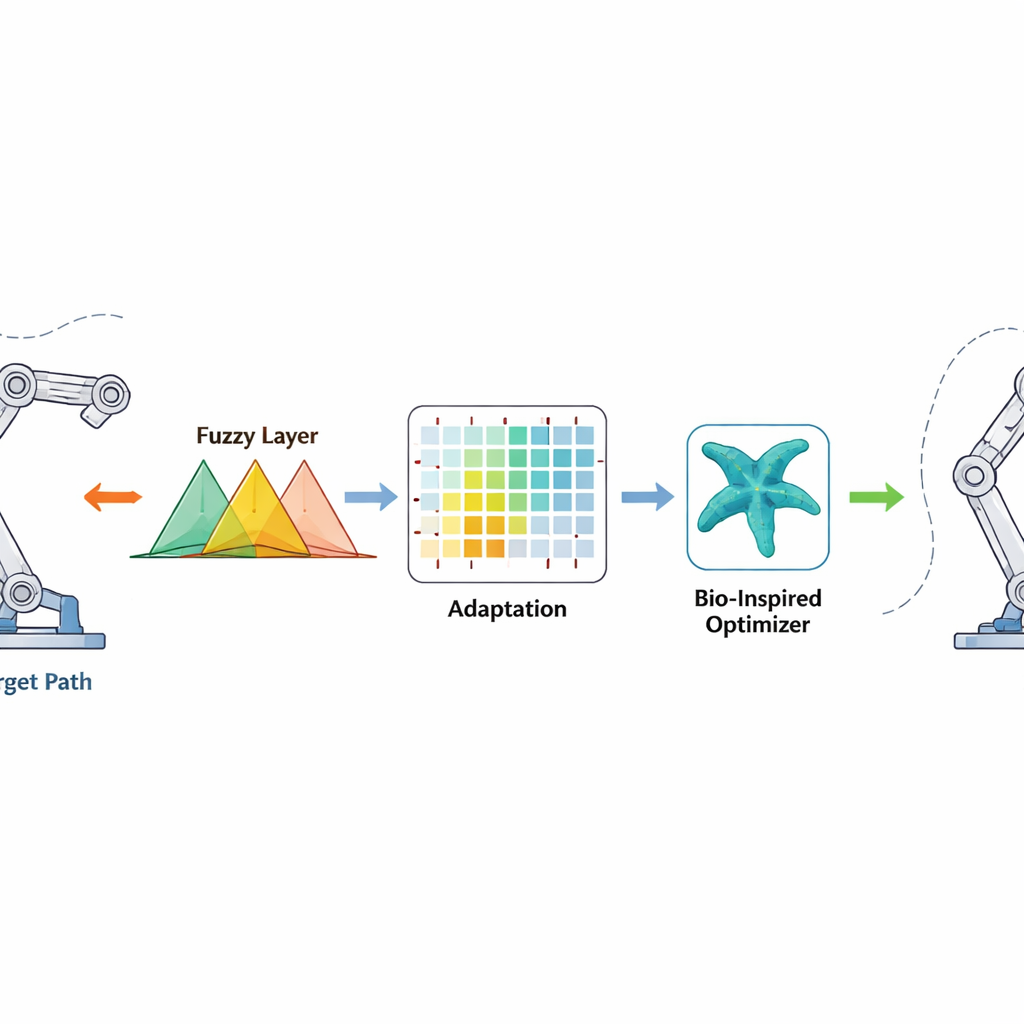
Bunu aşmak için yazarlar, eklemlerinin birbirini etkilediği robotlar için tamamen model-özgür bir kontrol çerçevesi öneriyor. Tam eşitliklere bağlı kalmak yerine kontrolör üç fikri harmanlıyor: “biraz fazla” veya “çok hızlı hareket ediyor” gibi belirsiz ifadeleri kontrol eylemlerine pürüzsüzce çeviren bulanık mantık; hatadan öğrenmeyi deneyim yoluyla sağlayan pekiştirmeli öğrenme; ve başlangıç ayarlarını harekete geçmeden önce iyi seçmeye yardımcı olan deniz yıldızı optimizasyon algoritması adını taşıyan biyomimetrik arama yöntemi. Buna ek olarak, takip hatalarının sadece er ya da geç küçülmesini değil, belirli kısa bir zaman penceresinde zorla indirilmelerini sağlayan özel bir "sonlu-zaman" terimi eklenir.
Yeni Kontrol Yöntemi Nasıl Çalışıyor
Kontrolör, her eklemin istenen açısına ne kadar uzak olduğunu ve bu hatanın ne kadar hızlı değiştiğini inceliyor. Bu sinyaller, belirsizlik ve doğrusal olmama ile başa çıkabilen örtüşen “eğer-ise” kuralları setleri olan bulanık kurallardan geçirilerek motorlara pürüzsüz bir tork komutu üretiliyor. Pekiştirmeli öğrenme, arka planda çevrim içi olarak bulanık kural parametrelerini ayarlıyor; hataları hızla azaltan eylemleri ödüllendiriyor, aşım veya titreşim yaratanları cezalandırıyor. Deniz yıldızı optimizatörü daha erken, çevrimdışı bir aşamada etkili oluyor ve deniz yıldızlarının okyanusta konumlarını keşfetme ve rafine etme şeklini taklit ederek iyi bir başlangıç bulanık parametre kümesi arıyor. Bu iyi başlangıç noktası, robot çalıştırıldığında öğrenmeyi hızlandırıyor; sonlu-zaman düzeltme terimi ise robotun kütlesi veya çevresi beklenmedik şekilde değişse bile hataları sınırlı bir zaman içinde neredeyse sıfıra iten güçlü, doğrusal olmayan bir ivme sağlıyor.
Simüle Edilmiş Kol ve Bacaklarda Test
Fikri test etmek için araştırmacılar iki robotun bilgisayar modellerini kullandılar. İlki, yürüyen bir bacağı taklit etmek için sıkça kullanılan basit iki eklemli bir sistem; burada bir eklem doğrudan motor kontrolü olmadan bırakılarak eksik etkili (underactuated), kontrolü daha zor bir durum temsil ediliyor. İkincisi ise hafif bir insansı uzuvla benzerlik taşıyan beş eklemli bir kol. Her iki durumda da gerekli eklem hareketleri pürüzsüz, dalga benzeri yollar şeklindeydi ve robotun bağlantı kütleleri gerçekçi, yavaş değişen yükleri taklit eden istatistiksel bir süreçle zaman içinde rastgele değiştirildi. Ek olarak rastgele itmeler ve tork sınırları gibi bozucu etkenler de kontrolörü zorlamak için eklendi.
Simülasyonlar Ne Gösteriyor
Çok sayıda denemede yeni kontrolör, robot eklemlerini istenen yolları yakından takip edecek şekilde tuttu; nihai açı hataları tipik olarak yaklaşık 0.02 ila 0.04 radyan aralığındaydı—bir kolun ucunda sadece birkaç milimetreye karşılık geliyor. Standart oransal–integrel–türev (PID) kontrol ve daha gelişmiş uyarlanabilir yöntemlerle karşılaştırıldığında, önerilen yaklaşım iki eklemli sistem için toplam takip hatasını yaklaşık yüzde 60’a kadar, beş eklemli kol için ise yaklaşık yüzde 30–35 civarında azalttı. Ayrıca genellikle bir buçuk saniyenin altında daha hızlı pürüzsüz harekete geçti ve yaklaşık yüzde 15 daha az kontrol çabası kullanarak daha düşük enerji tüketimi ve motorlarda daha az aşınma sağladı. Etkili kütleyi iki katına çıkarmak ve kullanılabilir torku sınırlamak gibi aşırı testlerde bile kontrolör kararlı hareketi sürdürdü ve şiddetli salınımlardan kaçındı.
Günlük Robotikte Bunun Anlamı
Uzman olmayanlar için temel mesaj, robotların değişen bir dünyada güvenilir hareket etmek için kendi mekanik ayrıntılarının tamamını bilmek zorunda olmadığıdır. İnsan benzeri "bulanık" muhakemeyi, deneme-yanılma öğrenimini ve deniz yıldızından ilham alan akıllı bir ön-ayarlama adımını birleştiren bu kontrol şeması, çok eklemli robotların değişen yükler ve bozucu etkenlere anında uyum sağlamasına ve yine de hataların hızla küçülmesini garanti etmesine olanak tanır. Gerçek donanımda doğrulanırsa, bu tür yöntemler servis robotlarını, yardımcı cihazları ve çevik endüstriyel kolları, yeni görevler, yeni aletler ve yeni ortamlarla uğraşırken bile daha güvenli ve daha verimli hale getirebilir; büyük yeniden programlama gerektirmeden.
Atıf: Duan, C., Wang, L. & Li, S. Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model. Sci Rep 16, 11458 (2026). https://doi.org/10.1038/s41598-026-40982-w
Anahtar kelimeler: robot kontrolü, pekiştirmeli öğrenme, bulanık mantık, uyarlanabilir robotik, trajektori takibi