Clear Sky Science · nl
Fuzzy adaptieve niet-lineaire MIMO-regeling voor starre gekoppelde multibody-robots met behulp van reinforcement learning-model
Robots die onderweg kunnen leren
Robots verlaten de afgeschermde productielijnen en betreden ziekenhuizen, magazijnen en zelfs onze huizen. In deze rommelige omgevingen veranderen hun lasten, zijn vloeren niet perfect vlak en kunnen mensen tegen ze aanlopen. Dit artikel onderzoekt een nieuwe manier om meergewrichtige robots — zoals armen en loopmachines — het vermogen te geven hun bewegingen soepel, precies en stabiel te houden, zelfs wanneer de omgeving onvoorspelbaar is en het eigen lichaam van de robot in de loop van de tijd verandert.
Waarom traditionele robotregeling tekortschiet
Klassieke robotregelaars zijn een beetje als cruisecontrol in een auto die ervan uitgaat dat de weg altijd droog en vlak is. Ze steunen op gedetailleerde wiskundige modellen van elk gewricht, elke tandwieloverbrenging en elke kracht. In de praktijk verandert het gedrag van een robot wanneer hij verschillende voorwerpen oppakt, zijn gewrichten opwarmen of hij stoten en duwen tegenkomt. Voor robots met veel gewrichten en sterke koppelingen daartussen is het vrijwel onmogelijk een perfect model te maken. Daardoor verspillen standaard enkelvoudige regelsystemen en zelfs meer geavanceerde meervoudige structuren vaak energie, reageren traag of verliezen ze nauwkeurigheid bij wisselende belastingen en verstoringen.
Een leerend regelings-‘brein’ voor meergewrichtige robots
Om dit aan te pakken, stellen de auteurs een volledig modelvrij regelkader voor, ontworpen voor robots met meerdere onderling beïnvloedende gewrichten. In plaats van te vertrouwen op exacte vergelijkingen, combineert de regelaar drie ideeën: fuzzylogica, die vage begrippen zoals “iets te ver” of “te snel bewegend” soepel vertaalt naar regelacties; reinforcement learning, waarmee de robot zijn beslissingen in de tijd door vallen en opstaan kan verbeteren; en een bio-geïnspireerde zoekmethode, het starfish-optimalisatie-algoritme, dat helpt goede beginstellingen te kiezen voordat de robot ooit beweegt. Daarbovenop wordt een speciaal ‘eindige-tijd’-term toegevoegd zodat volgfouten niet alleen uiteindelijk kleiner worden, maar binnen een gegarandeerd korte tijdsperiode gedwongen afnemen.
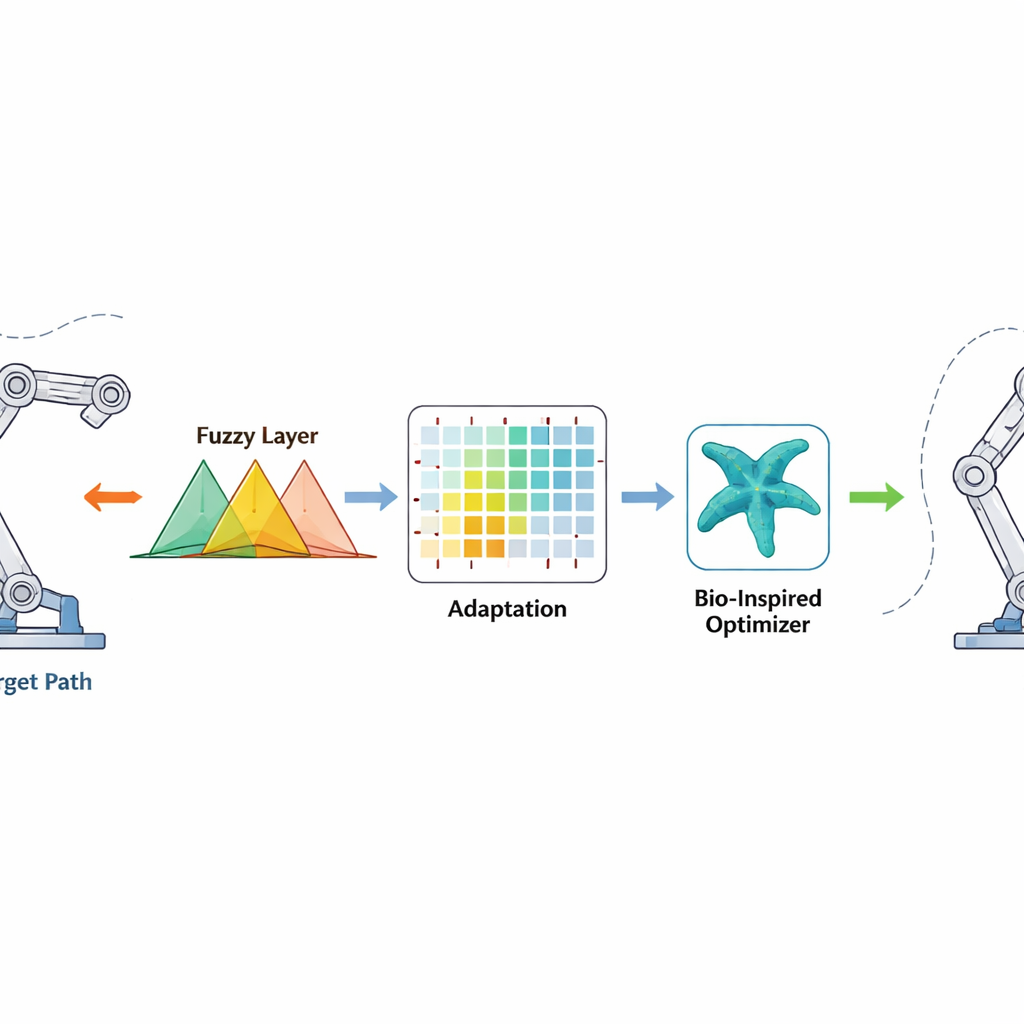
Hoe de nieuwe regelmethode werkt
De regelaar kijkt naar hoe ver elk gewricht van zijn gewenste hoek afzit en hoe snel die fout verandert. Deze signalen worden door fuzzy-regels gevoerd — sets overlappende ‘als-dan’-regels die onzekerheid en niet-lineariteit aankunnen — om een vloeiend koppelcommando voor de motoren te genereren. Reinforcement learning werkt op de achtergrond en past de parameters van de fuzzy-regels online aan, en beloont acties die fouten snel verminderen en bestraft die overshoot of trilling veroorzaken. De starfish-optimizer treedt eerder op, in een offline fase, en zoekt naar een goede initiële set fuzzy-parameters door na te bootsen hoe zeesterren hun positie verkennen en verfijnen. Dit goede startpunt versnelt het leren zodra de robot wordt ingeschakeld, terwijl de eindige-tijd-correctieterm een sterke, niet-lineaire impuls toevoegt die fouten binnen een begrensde tijd naar bijna nul drijft, zelfs als massa of omgeving van de robot onverwacht verandert.
Testen op gesimuleerde armen en benen
Om het idee te testen gebruikten de onderzoekers computermodellen van twee robots. De eerste is een eenvoudig tweewrichtingssysteem dat vaak gebruikt wordt om een loopbeen na te bootsen, waarbij één gewricht opzettelijk zonder directe motorbesturing wordt gelaten om een onderaandreven, moeilijker te regelen situatie weer te geven. De tweede is een vijfgewrichtige arm vergelijkbaar met een lichtgewicht menselijke ledemaat. In beide gevallen waren de gevraagde gewrichtsbewegingen vloeiende, golfachtige paden, terwijl de massa’s van de robotverbindingen in de tijd willekeurig werden gevarieerd met een statistisch proces dat realistische, langzaam veranderende ladingen imiteert. Extra verstoringen, zoals willekeurige duwen en koppelbeperkingen, werden eveneens toegevoegd om de regelaar te belasten.
Wat de simulaties laten zien
In veel proefopstellingen kon de nieuwe regelaar de robotgewrichten nauwgezet hun gewenste paden laten volgen, met eindhoeksfouten die doorgaans binnen ongeveer twee honderdsten tot vier honderdsten van een radiaan lagen — slechts een paar millimeter aan het einde van een arm. Vergeleken met standaard proportioneel–integraal–derivaat (PID)-regeling en meer geavanceerde adaptieve methoden, verminderde de voorgestelde aanpak de totale volgfout tot ongeveer 60 procent voor het tweewrichtingssysteem en ongeveer 30–35 procent voor de vijfgewrichtige arm. Het bereikte ook sneller vloeiende bewegingen, vaak in minder dan anderhalve seconde, en gebruikte grofweg 15 procent minder regelinspanning, wat lagere energieconsumptie en minder slijtage aan motoren betekent. Zelfs onder extreme tests — zoals het verdubbelen van de effectieve massa terwijl het beschikbare koppel beperkt werd — behield de regelaar stabiele beweging en vermeden wilde uitwijkingen.
Wat dit betekent voor alledaagse robotica
Voor niet-specialisten is de kernboodschap dat robots niet elk detail van hun eigen mechanica hoeven te kennen om betrouwbaar te bewegen in een veranderende wereld. Door mensachtige ‘fuzzy’-redenering, trial-and-error leren en een slimme voorinstellingsstap geïnspireerd door zeesterren te combineren, laat dit regelschema meergewrichtige robots ter plaatse aanpassen aan verschuivende lasten en verstoringen, terwijl het toch garandeert dat fouten snel afnemen. Als dit op echte hardware wordt bevestigd, kunnen zulke methoden dienstrobots, ondersteunende apparaten en wendbare industriële armen zowel veiliger als efficiënter maken, zelfs wanneer ze gevraagd worden nieuwe taken, nieuwe gereedschappen en nieuwe omgevingen te hanteren zonder uitgebreide herprogrammering.
Bronvermelding: Duan, C., Wang, L. & Li, S. Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model. Sci Rep 16, 11458 (2026). https://doi.org/10.1038/s41598-026-40982-w
Trefwoorden: robotbesturing, reinforcement learning, fuzzylogica, adaptieve robotica, trajectvolging