Clear Sky Science · ru
Нечеткий адаптивный нелинейный MIMO‑контроллер для жестко связанных многозвенных роботов с использованием модели обучения с подкреплением
Роботы, которые учатся в работе
Роботы выходят за пределы огороженных заводских линий и попадают в госпитали, склады и даже наши дома. В этих хаотичных условиях их груз меняется, полы далеки от идеальной ровности, и люди могут случайно сталкиваться с ними. В статье рассматривается новый подход, позволяющий многосуставным роботам — например, манипуляторам и шагающим машинам — сохранять плавность, точность и устойчивость движений даже при непредсказуемой окружающей среде и изменениях в самой механике робота.
Почему традиционное управление роботом не хватает
Классические алгоритмы управления роботом похожи на круиз‑контроль автомобиля, который считает дорогу всегда сухой и ровной. Они опираются на детальные математические модели каждого звена, шестерни и силы. На практике поведение робота меняется — когда он поднимает разные предметы, суставы нагреваются или он натыкается на неровности и толчки. Для роботов с множеством звеньев и сильной связностью между ними создать совершенную модель практически невозможно. В результате стандартные одноцикловые регуляторы и даже более сложные многоуровневые схемы нередко теряют энергоэффективность, реагируют медленно или теряют точность при изменяющихся нагрузках и возмущениях.
Управляющий «мозг», который учится для многосуставных роботов
Авторы предлагают полностью модель‑независимую структуру управления, рассчитанную на роботов с несколькими взаимовлияющими суставами. Вместо точных уравнений контроллер сочетает три идеи: нечеткую логику, которая плавно переводит расплывчатые понятия вроде «слегка в стороне» или «слишком быстро» в управляющие действия; обучение с подкреплением, которое позволяет роботу постепенно улучшать решения методом проб и ошибок; и биологически вдохновленный метод поиска — алгоритм оптимизации морской звезды, помогающий подобрать хорошие стартовые настройки до начала работы робота. Кроме того, введен специальный член с конечным временем сходимости, чтобы ошибки траектории не просто уменьшались со временем, а гарантированно снижались в пределах короткого фиксированного интервала.
Как работает новый метод управления
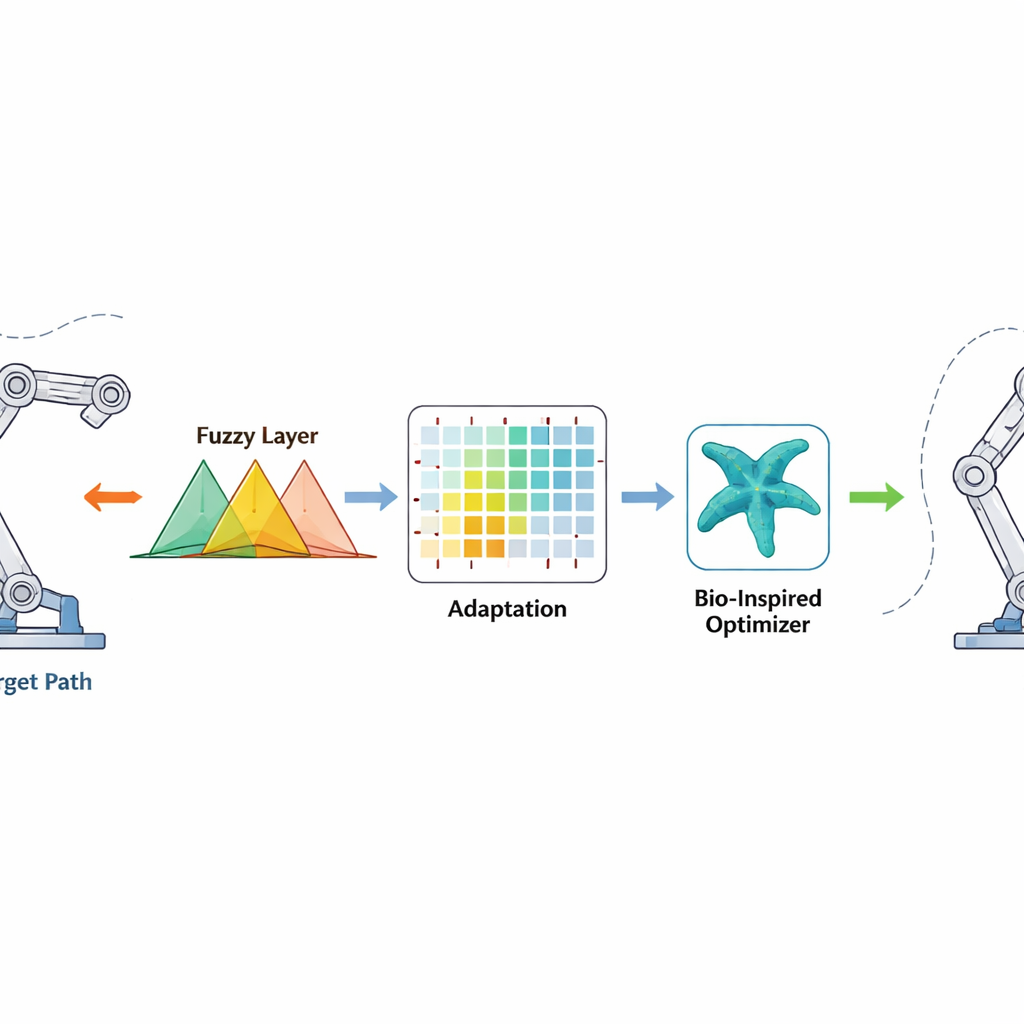
Контроллер отслеживает, на какое расстояние каждый сустав отклоняется от желаемого угла и с какой скоростью меняется это отклонение. Эти сигналы проходят через нечеткие правила — наборы перекрывающихся «если‑то» утверждений, способных работать с неопределенностью и нелинейностью — для формирования плавной команды на крутящий момент мотору. Обучение с подкреплением работает в фоновом режиме и настраивает параметры нечеткой системы онлайн, поощряя действия, которые быстро уменьшают ошибку, и штрафуя те, что вызывают перерегулирование или дрожание. Оптимизатор‑«морская звезда» действует заранее, на офлайн‑этапе, подбирая хорошие начальные параметры нечеткой системы, имитируя поведение морских звезд при исследовании и уточнении положения в океане. Такой удачный старт ускоряет обучение после включения робота, а член конечного времени добавляет сильный нелинейный импульс, который приводит ошибки почти к нулю за ограниченное время, даже при неожиданных изменениях массы или условий среды.
Тестирование на моделях рук и ног
Для проверки идеи исследователи использовали компьютерные модели двух роботов. Первый — простая двухсуставная система, часто применяемая как аналог шагающей ноги, где один сустав намеренно не оснащён прямым моторным приводом, что моделирует недоприводную, более сложную для управления ситуацию. Второй — пятитишарнирный манипулятор, похожий на лёгкую гуманоидную конечность. В обоих случаях требуемые движения суставов были плавными, волнообразными траекториями, а массы звеньев случайно менялись во времени через статистический процесс, имитирующий реалистичные медленно меняющиеся полезные нагрузки. Для дополнительной проверки контроллера вводились внешние помехи, такие как случайные толчки и ограничения по крутящему моменту.
Что показали симуляции
Во множестве испытаний новый контроллер обеспечивал точное слежение за заданными траекториями: конечные ошибки углов обычно составляли примерно от 0,02 до 0,04 радиана — всего несколько миллиметров на кончике манипулятора. В сравнении с классическим ПИД‑регулятором и более продвинутыми адаптивными методами предложенный подход снизил суммарную ошибку отслеживания до примерно 60% для двухсуставной системы и на 30–35% для пятиришенного манипулятора. Он также быстрее выходил на плавное движение — часто менее чем за полторы секунды — и требовал примерно на 15% меньше управляющего усилия, что означает меньший расход энергии и меньший износ моторов. Даже в экстремальных испытаниях — например при удвоении эффективной массы при ограниченном доступном крутящем моменте — контроллер сохранял стабильное движение и избегал резких колебаний.
Что это значит для повседневной робототехники
Для неспециалистов главный вывод в том, что роботу не обязательно знать все детали собственной механики, чтобы надёжно двигаться в меняющемся мире. Сочетая человечноподобное «нечеткое» рассуждение, обучение методом проб и ошибок и умную предварительную настройку, вдохновлённую морскими звездами, эта схема управления позволяет многосуставным роботам подстраиваться на ходу под изменяющиеся нагрузки и помехи, при этом гарантируя быстрое уменьшение ошибок. Если результаты подтвердятся на реальном оборудовании, такие методы могут сделать сервисных роботов, вспомогательные устройства и подвижные промышленные манипуляторы безопаснее и эффективнее, даже когда им приходится выполнять новые задачи, работать с новыми инструментами и в новых средах без долгого перепрограммирования.
Цитирование: Duan, C., Wang, L. & Li, S. Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model. Sci Rep 16, 11458 (2026). https://doi.org/10.1038/s41598-026-40982-w
Ключевые слова: управление роботами, обучение с подкреплением, нечеткая логика, адаптивная робототехника, отслеживание траектории